Using the Data Toolkit Service to Access Data
The Anzo Data Toolkit SPARQL service is a flexible tool that enables users to query data from remote endpoints that are accessible over JDBC or HTTP. Using the data toolkit, you can access data that is stored in databases, web servers, or files. You can also use the toolkit to invoke other scripts. The data that you retrieve can be incorporated into a data layer to augment the data that is stored in Anzo.
Getting Familiar with the Data Toolkit
One way to learn about the capabilities of the Data Toolkit is to explore the Data Toolkit Ontology, which is available as a system model. Exploring the classes that the model contains enables you to view details such as the properties that are available for queries, the types of data sources you can target, and how to supply credentials. This section provides instructions for viewing the model.
- In the Anzo console, click Model. Anzo displays the Manage Data Model Working Set screen. For example:
- Open the Filters panel by clicking the filter icon (
 ) in the top left corner of the screen.
) in the top left corner of the screen. - In the Filters panel, select the Only show system data checkbox. The Manage Working Set screen is refreshed to show only the system models.
- In the search field at the top of the screen, search for "data toolkit." The working set screen displays the model.
- To open the model, select the checkbox to the left of the model and click OK. Anzo opens the model in the viewer:
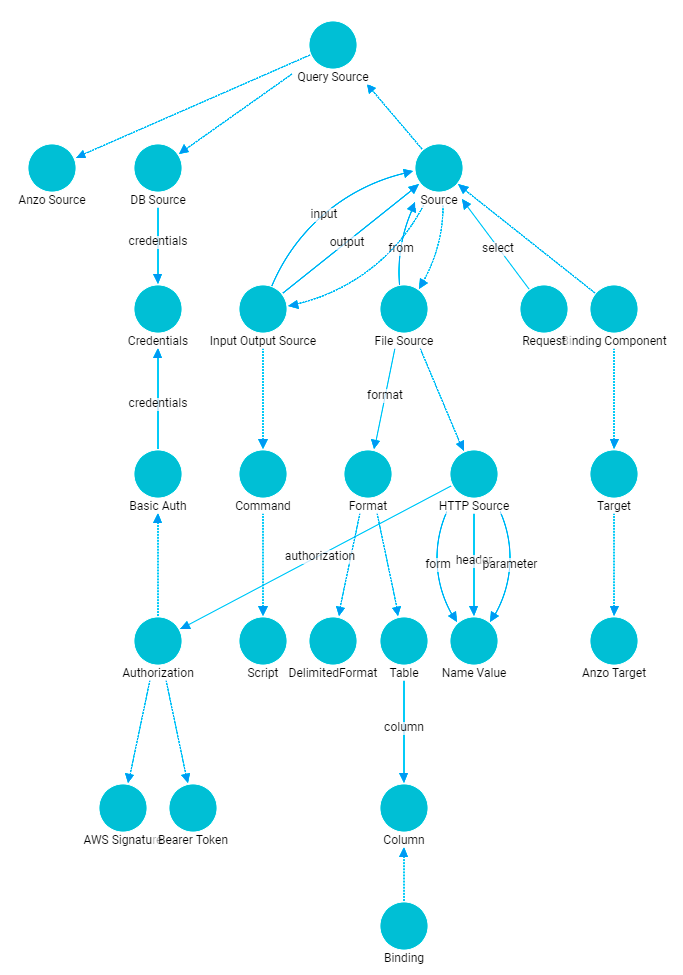
- You can click the View tab to see a graph view of the model. For example, the image below shows a hierarchical view of the model.
Using the Toolkit in a Data Layer
To invoke the Data Toolkit service in a data layer, add a Query Step to the layer. When writing the query to run in the Query Step, include a SERVICE call that specifies the remote endpoint and defines the data to retrieve from the endpoint. For instructions on creating a Query Step, see Adding a Step that Runs a Query. For details about writing data toolkit SERVICE statements, see Writing a Data Toolkit SERVICE Query below.
Writing a Data Toolkit SERVICE Query
The following WHERE clause syntax can be used as a template for writing queries with SERVICE calls that invoke the Data Toolkit service:
WHERE
{
[ SERVICE TOPDOWN <http://openanzo.org/localsparql>
{ ]
SERVICE <http://cambridgesemantics.com/services/DataToolkit>
{
triple_patterns
}
[ } ]
}
The SERVICE TOPDOWN clause is optional. It typically calls the local Anzo SPARQL endpoint, and it indicates that the rest of the query produces values that are input to the SERVICE call. When TOPDOWN is excluded, the query is run "bottom up;" the SERVICE clause is run first, and those results become input to the rest of the query. In general, if the SERVICE call needs input based on the results from the rest of the query, it is a TOPDOWN query.
Top Down Query Scenarios
The list below describes two scenarios for using a top-down query:
- A graphmart contains data about a company's office locations. A user wants to query the graphmart to return all of the office locations and then send those results to a service to retrieve the current temperature for each location.
- A graphmart contains data about employees. A user wants to query the graphmart to return the top 10 employees and then send the results to a service to retrieve those employees' personal information from an LDAP server. If the query excluded the TOPDOWN clause, the service would be called first and return the LDAP records for every employee.
Bottom Up Query Scenario
This example describes a scenario for using a bottom-up query: A graphmart contains data about a company's office locations. A user wants to query a service to find the city with highest income and then use that result to query the graphmart and see if the company has an office in that city.
Examples
The query below invokes the Data Toolkit service to retrieve weather forecast data for specific cities from Dark Sky API.
REFIX s: <http://cambridgesemantics.com/ontologies/DataToolkit#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX anzo: <http://openanzo.org/ontologies/2008/07/Anzo#>
PREFIX zowl: <http://openanzo.org/ontologies/2009/05/AnzoOwl#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
SELECT
?name ?state ?latitude ?longitude ?time ?summary ?temperature ?rainChance
?rainIntensity ?nearestStormDistance ?nearestStormBearing ?visibility
WHERE
{
SERVICE <http://cambridgesemantics.com/services/DataToolkit>
{
?data a s:HttpSource ;
s:url "https://api.darksky.net/forecast/bdbe3f638eb908c9b94919537dad5945/{{?latitude}},{{?longitude}}" ;
s:selector "currently" ;
?time () ;
?summary () ;
?temperature () ;
?rainChance ( "precipProbability" ) ;
?rainIntensity ( "precipIntensity" ) ;
?nearestStormDistance () ;
?nearestStormBearing () ;
?visibility () .
}
}
VALUES( ?name ?state ?latitude ?longitude )
{
( "Lakeway" "TX" 30.374563 -97.975892 )
( "Boston" "MA" 42.358043 -71.060415 )
( "Seatle" "WA" 47.590720 -122.307053 )
( "Chicago" "IL" 41.837741 -87.823296 )
( "Hilo" "HI" 19.702040 -155.090312 )
}
Additional examples are in progress. The Data Toolkit plugin JAR file, com.cambridgesemantics.anzo.datatoolkit.jar, in Anzo_install_dir/Server/plugins/ contains several example queries.