Introduction to Anzo Concepts and Vocabulary
This topic introduces you to key features, concepts, and vocabulary to know when working with Anzo. The diagram below shows a high-level overview of Anzo components and concepts. Details about the components in the image are described below, followed by a glossary that defines common Anzo terms and phrases.
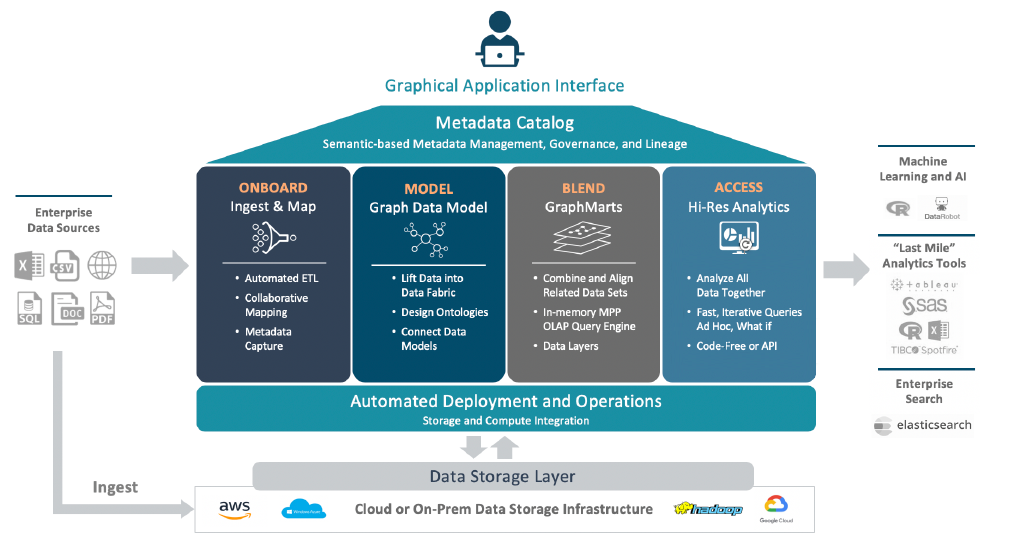
| Component | Description |
|---|---|
| Enterprise Data Sources | Anzo onboards data from many structured and unstructured data sources. Structured data sources such as relational databases or flat files are onboarded using Anzo’s built-in pipelines. These pipelines natively support CSV, JSON, XML, and SAS files, along with all
common database connections, including SQL, Oracle, MySQL, HIVE and others. Unstructured data sources, such as documents, PDFs, text snippets, web pages, and content from knowledgebases, are onboarded using configurable unstructured data pipelines. These pipelines onboard unstructured source files, integrate metadata about those files into the Anzo catalog, and make the full text in those files and key facts available as part of graph data models. |
| Data Storage Layer | Anzo is typically deployed on top of existing storage, including HDFS, AWS S3, NFS, or other cloud storage. Anzo uses this storage to maintain onboarded subsets of the data fabric as graph data. |
| Metadata Catalog | Anzo’s catalog is a special-purpose graph data model within Anzo. It combines traditional technical, operational, and business metadata with a semantic layer to describe all aspects of enterprise data elements. The catalog enables Anzo’s unique use of semantics and graph models and is the system of record for data in Anzo. Anzo collects and generates metadata at every stage in the data discovery and integration process. Metadata in the catalog documents how data is converted during the onboarding process from its original format into a graph model. Subsequent data blending, transformation, and preparation steps are captured as additional metadata. Anzo also captures new metadata to describe all actions taken against data within Anzo. Anzo uses the metadata to enable users to visualize their data, understand business contexts, identify connections, and blend and prepare data. |
| Onboard | When data is onboarded from its source platform to Anzo, it is converted from its original format into a new format that describes the data as a graph data model. This format, Resource Description Framework (RDF), captures each data value and relationship. Anzo stores the converted RDF data in files that Anzo’s catalog manages. RDF data, in Turtle (TTL) format, is efficiently laid out on disk for optimal loading into Anzo’s in-memory graph engine, AnzoGraph. Mappings describe how data from source systems is transformed into Anzo’s RDF format. These mappings can be automatically generated from the source system’s schema or custom-defined to perform additional transformation steps as part of the onboarding process. At run time, Anzo converts these mappings into Spark code that is executed on a Spark engine. |
| Model | Anzo establishes the semantic layer by enabling users to convert diverse enterprise data models into graph data models and then enhance the data by adding new business definitions, names, and tags. Further insight is added when data from separate graph data maps are linked, connecting shared business definitions across previously siloed sources. Anzo employs open World Wide Web Consortium (W3C) standards, including Web Ontology Language (OWL), RDF, and SPARQL to model, connect, and query interconnected graphs. |
| Blend | When users select one or more data sets from the Anzo catalog to blend and access, Anzo loads the corresponding files from the file store into memory for rapid analysis and manipulation. Anzo delivers blending and access through “graphmarts” that give users the flexibility to combine and analyze any subset of data in Anzo. |
| Access | Anzo’s Hi-Res Analytics module enables users to analyze all data onboarded, modeled, and blended into graphmarts. Graphmarts and Hi-Res Analytics are backed by AnzoGraph, Anzo’s high-performance graph OLAP engine that scales as required from a single node up to hundreds of nodes. |
| Graphical Application Interface | The graphical application interface is organized and compartmentalized by the concepts and processes described above. The design accommodates use cases where users with different permissions and responsibilities build various parts of a solution. For a tour of the graphical user interface, see Introduction to the User Interface. |
| Last Mile Analytics Tools | In line with its open standard architecture, Anzo graphmarts can be accessed using modern application program interfaces (APIs). In addition to using SPARQL-compliant query endpoints, Anzo offers standards-compliant Open Data Protocol (OData)-based REST data feed endpoints as part of its data on demand service. |
Anzo Glossary
The table below defines commonly used Anzo terms and phrases.
| Phrase | Description |
|---|---|
| Anzo for Office | Anzo for Office (AFO or A4O) is the Microsoft Excel plugin that enables you to create and edit source to target ETL mappings. |
| Anzo Data Store | An Anzo data store (previously known as a graph data source) defines an endpoint for writing data. It specifies the file store and directory on the file store where Anzo can generate file-based linked data sets. It also defines write properties such as the maximum file size and whether files should be compressed. |
| AnzoGraph | AnzoGraph (AZG) is Anzo’s in-memory massively parallel processing (MPP) graph OLAP engine. |
| Data Layers | Data layers enable users to enhance graphmarts dynamically. Users can create layers to load additional data sets, clean, conform, or transform data, infer new information, or export data to an FLDS. |
| Data Toolkit | Anzo's Data Toolkit is a SPARQL service that enables users to query data from external endpoints that are accessible over JDBC or HTTP. Information from the external sources can augment data in the Anzo catalog without having to onboard the data to Anzo. |
| ELT | In addition to traditional ETL, Anzo’s data layers capability enables users to transform, blend, and prepare any data that has been added to the catalog into analytics-ready data sets using an extract, load, transform (ELT) flow. Data layers are Anzo's mechanisms for flexibly transforming data in memory. |
| ETL | The extract, transform, and load (ETL) process takes source data and converts it to the graph data model, including the definition of a source to target mapping. Anzo’s mapping tool enables users to define field-level transformations, including type casting, date conversions, unit conversions, etc., as data is onboarded to Anzo. |
| File-Based Linked Data Set | When Anzo generates a set of Turtle files in an Anzo data store during the ETL process, the set of files is known as a file-based linked data set (FLDS). |
| File Store | A file store is the file storage system, such as NFS, HDFS, or cloud storage, that is shared between servers in an Anzo solution. Anzo, AnzoGraph, Elasticsearch, and other systems share data in a file store. |
| Graphmart | Graphmarts are metadata descriptions of collections of datasets that users can share, discover, and enhance. Graphmarts can combine any subset of data in Anzo for analysis. |
| Hi-Res Analytics | Anzo Hi-Res Analytics enable users to explore and ask questions across all of their data. Using model-guided dashboards, users can perform computations across multi-dimensional data. Hi-Res Analytics dashboards generate complex graph queries dynamically based on user input. |
| IRI | An Internationalized Resource Identifier (IRI) is similar to URI but allows a greater range of characters. URI and IRI are often used interchangeably. |
| Journal | A journal is a local volume that is written to disk as a .jnl file. |
| Linked Data Set | A linked data set (LDS) is a fundamental concept. Anzo organizes all data, including system data, into linked data sets. An LDS is associated with a data model and can be searched, discovered, shared, and protected with access control. For example, graphmarts are organized in a linked data set or registry of graphmarts, pipelines are organized in a linked data set, the Activity Log is a linked data set, data source configurations exist in a linked data set, and so on. |
| Local Volume | A local volume refers to Anzo's local storage, a quadstore called BlazeGraph. |
| NLP | Anzo onboards unstructured data using natural language processing (NLP) to find and extract data. |
| OData | Open Data Protocol (OData) facilitates the creation of interoperable RESTful APIs. The Anzo Data on Demand service provides OData-based feeds that can be used to query graphmart data from third-party business intelligence tools. |
| OSGi | The Open Service Gateway Initiative (OSGi) is the open-standard architecture upon which Anzo is built. It is a Java framework for developing and deploying software programs and libraries. OSGi enables Cambridge Semantics to compartmentalize Anzo into "bundles" that can be deployed, activated, and removed independently without affecting other bundles in the system. |
| Provenance | Anzo retains and displays the provenance of all onboarded structured data. The provenance explorer provides an overview of the relationships across various sources and models. Users can search for data entities and view associated pipelines, data sources, models, and schemas. |
| System Volume | The local volume that contains system information, such as registries for models, linked data sets, data sources, etc. |
| URI | A Uniform Resource Identifier (URI) is a globally unique identifier for a piece of information. A URL (Uniform Resource Locator) is a URI that specifies a location, such as a web address. |