Configuring a Spark ETL Engine
This topic provides instructions for configuring a connection to a Spark ETL engine.
- In the Administration application, expand the Connections menu and click ETL Engine Config. Anzo displays the ETL Engine Config screen, which lists existing ETL engine connections. For example:
- On the ETL Engine Config screen, click the Add ETL Engine Config button and select Spark Engine Config. Anzo displays the Create Spark Engine Config screen.

- On the Create screen, type a Title and optional Description for the engine. Then click Save. Anzo displays the Details view for the new engine. For example:
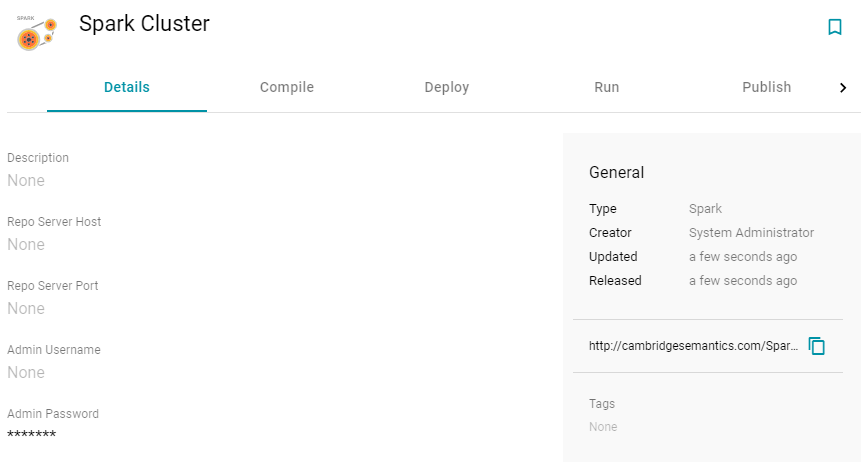
- Configure the engine by completing the required fields and adding any optional values on the Details, Compile, Deploy and Run tabs. To edit a field, click a value to make the field editable or click the edit icon (
 ). Click the check mark icon (
). Click the check mark icon ( ) to save changes to an option, or click the X icon (
) to save changes to an option, or click the X icon ( ) to clear the value for an option. See the Spark Settings Reference section below for descriptions of the settings.
) to clear the value for an option. See the Spark Settings Reference section below for descriptions of the settings.
Spark Settings Reference
This section provides reference information for the Spark ETL engine settings on each of the tabs.
Details Tab
- Repo Server Host: Leave this field blank.
- Repo Server Port: Leave this field blank.
- Admin Username: Not currently used.
- Admin Password: Not currently used.
Compile Tab
The Compile settings control where Anzo saves the compiled Scala .jar files for the Spark job.
- Remote Server: The host name or IP address of the server where the compilation will be performed.
- Target Folder: The path and directory on the server where Anzo can stage temporary artifacts created during the compilation and upload process. The location must be a valid path on the Anzo server that the user running the ETL job has access to.
Deploy Tab
The Deploy step is performed after the job is compiled locally and before the job is submitted to Spark. The Deploy settings control how and where the job's .jar files will be copied from the Anzo server to a file system that Spark can access.
- Deployment Working Dir: The directory that the Anzo server should use when executing the deploy commands.
- Deploy Command: The command line script that the deploy step should run.
Run Tab
- Job Runner Endpoint: The HTTP endpoint used to reach the Livy server. For example, when using the local Anzo Spark engine, the endpoint is localhost:8998.
- SDI Jobs Dir: The file system location where the Spark engine will look for the compiled .jar files. This field is required when working with a remote Spark server. It can be left blank when using the local Spark engine.
- SDI Dependencies Dir: The file system location where the Spark engine will look for the dependency .jar files, sdi-full-deps.jar and sdi-deps.jar. If you are using a remote Spark cluster, sdi-full-deps.jar and sdi-deps.jar can be copied to the Spark master node from the
<install_path>/Server/data/sdiScripts/<Spark_version>/compile/dependencies-libdirectory on the Anzo server. - Additional Jars: For relational database sources, this field lists the file system location for the JDBC driver .jar file or files that are used to connect to the source. All paths must be absolute. For multiple jar files, specify a comma-separated list. Do not include a space after the commas.
For RDBs whose drivers are installed with Anzo, such as MSSQL (com.springsource.net.sourceforge.jtds_1.2.2.jar), Oracle (oracle.jdbc_11.2.0.3.jar), Amazon Redshift (org.postgresql.osgi.redshift_9.3.702.jar), and PostgreSQL (com.springsource.org.postgresql.jdbc3_8.3.603.jar), you can find the driver jar files in the
<install_path>/Server/pluginsdirectory.- If you use the local Spark ETL engine, the Additional Jars field should list the path to the jar files in the Anzo plugins directory. For example,
/opt/Anzo/Server/plugins/org.postgresql.osgi.redshift_9.3.702.jar. - If you use a remote Spark cluster in cluster mode, the driver jar files need to be copied onto the HDFS. If Spark is running in client mode, jar files can be copied to the Hadoop/Spark master node file system. Specify the path to the copied jar files in the Additional Jars field.
If a driver is uploaded to Anzo as described in Uploading a Plugin, the driver will be in the
<install_path>/Server/dropinsdirectory. For example,/opt/Anzo/Server/dropins/com.springsource.com.mysql.jdbc-5.1.6.jar - If you use the local Spark ETL engine, the Additional Jars field should list the path to the jar files in the Anzo plugins directory. For example,
- Execute Locally: Select this option for local Spark engines on the Anzo server. Make sure this option is not selected when using a remote Spark server.
- Do Callback: Select this option when you want Anzo to create a new data set in the Dataset catalog and generate load files for the graph source.
- Run with Yarn: Employs the Spark YARN cluster manager when running ETL jobs.
- Callback URL: When Do Callback is selected, enter one of the following URLs:
http://Anzo_hostname_or_IP:Anzo_app_HTTP_port/anzoclient/call
https://Anzo_hostname_or_IP:Anzo_app_HTTPS_port/anzoclient/call
For example:
https://10.100.0.1:8443/anzoclient/call
Publish Tab
The Publish tab controls the action of the Publish All button when a pipeline is published.
Sharing Tab
The Sharing tab enables you to share or restrict access to this ETL engine.
When the configuration is complete, Anzo provides this ETL engine as a choice to select when ingesting data and configuring pipelines. If you want to specify the default ETL engine to use automatically any time a pipeline is configured, see Configure the Default ETL Engine.