Running an Unstructured Pipeline
This page provides instructions for running an unstructured pipeline.
- In the Anzo application, expand the Onboard menu and click Unstructured Data. Anzo displays the Pipeline screen, which lists any existing unstructured pipelines. For example:
- Click the name of the pipeline that you want to run. Anzo displays the pipeline Overview screen. For example:

- Click Run Pipeline to run the pipeline.
The process can take several minutes to complete. You can click the Progress tab to view details such as the pipeline status, runtime, number of documents processed, and errors. For example:
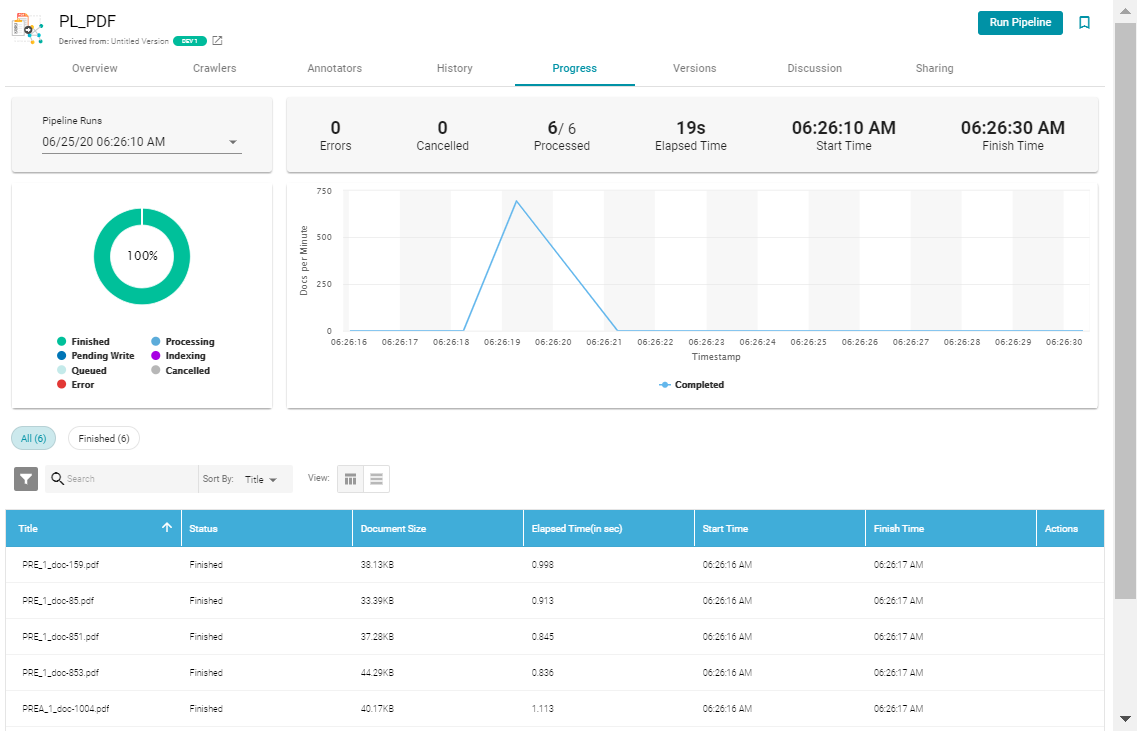
When the Pipeline finishes, this run of the Pipeline becomes the Managed Edition. The Managed Edition always contains the latest successfully published data for all of the jobs in the Pipeline. If one or more of the jobs failed, those jobs are excluded from the Edition. If you publish the failed jobs at a later date or you create and publish additional jobs in the Pipeline, the data from those jobs is also added to the Managed Edition. For more information about Editions, see Managing Dataset Editions.
The new Dataset also becomes available in the Dataset catalog. From the catalog, you can generate graph Data Profiles and create Graphmarts. See Blending Data for next steps.