Graph Lakehouse Requirements
This topic lists the minimum requirements and recommendations to follow when provisioning host servers for Graph Lakehouse.
- Hardware Requirements
- Software Requirements
- Firewall Requirements
- Notes on Clusters and Virtual Environments
Hardware Requirements
The following guidelines apply to individual Graph Lakehouse servers. Your Cambridge Semantics Customer Success manager can help you identify an overall Graph Lakehouse deployment configuration that is appropriate for your solution and use cases.
| Component | Minimum | Recommended | Guidelines |
|---|---|---|---|
| RAM | 16 GB (small-scale testing only) | 200+ GB | Graph Lakehouse needs enough RAM to store data, intermediate query results, and run the server processes. Altair recommends that you allocate 3 to 4 times as much RAM as the planned data size.
Do not overcommit RAM on a VM or on the hypervisor/container host. For information on determining the server and cluster size that is ideal for your workload, see Sizing Guidelines for In-Memory Storage. |
| Disk Space (Install Path) | 40 GB HDD | 200+ GB SSD | Graph Lakehouse requires 30 GB for internal requirements. By default, up to 20 GB of disk space (in install_path/spill) is used for logging historical system information for analysis. The amount of additional disk space required for any load file staging, data persistence, or logs depends on the size of the data to be loaded. |
| vCPU | 2 | 32 or 64 | Once you provision sufficient RAM and a high-performing I/O subsystem, performance depends on CPU capabilities. A greater number of cores can make a dramatic difference in the performance of file loads and concurrent queries. Intel x86-64 processors are recommended, but Graph Lakehouse is supported on Epyc and later generation AMD processors. Graph Lakehouse does not run on Opteron AMD processors or Mac ARM-based processors. |
| Networking | 10gbE | 20+gbE | Not applicable for single server installations.
Since Graph Lakehouse is high performance computing (HPC) Massively Parallel Processing (MPP) OLAP engine, inter-cluster communications bandwidth dramatically affects performance. Graph Lakehouse clusters require optimal network bandwidth. All servers in a cluster must be in the same network. Make sure that all instances are in the same VLAN, security group, or placement group. In a switched network, make sure that all NICs link to the same Top Of Rack or Full-Crossbar Modular switch. If possible, enable SR-IOV and other HW acceleration methods and dedicated layer 2 networking that guarantees bandwidth. |
| Shared File System | N/A | Mounted NFS | The shared file system must be accessible from each Graph Lakehouse host server. See Platform Shared File Storage Requirements. |
Software Requirements
The table below lists the software requirements for Graph Lakehouse servers. Instructions for installing each of the required software components are included in the Graph Lakehouse installation instructions. See Installing AnzoGraph for more information.
| Component | Requirement | Description |
|---|---|---|
| Operating System | RHEL/Rocky Linux 9.3+ | AnzoGraph is not supported on Enterprise Linux 7 or 8. |
| Glibc-devel Library | Installed on all host servers | For compiling queries, Graph Lakehouse requires the latest version of the glibc-devel library for your operating system. |
| GNU Binutils | Installed on all host servers | To compile and link programs, Graph Lakehouse requires the latest version of the binutils package for your operating system. |
| OpenJDK or GraalVM | Version 21 installed on all host servers | Graph Lakehouse uses a Java client interface to access structured data sources and Elasticsearch for unstructured pipelines. A Java 21 environment is required for using the Java client. Graph Lakehouse supports OpenJDK 21 and GraalVM 21. |
| Service User Account | Enterprise-level account | It is important to install and run Graph Lakehouse (and all other platform components) as the same service user. See Platform Service User Account Requirements. |
Optional Software
| Program | Description |
|---|---|
| vim | Editor for creating or changing files. |
| sudo | Enables users to run programs with alternate security privileges. |
| net-tools | Networking utilities. |
| psutil | Python system and process utilities for retrieving information on running processes and system usage. |
| tuned | Linux system service to apply tuning. |
| wget | Utility for downloading files over a network. |
Firewall Requirements
Graph Lakehouse servers communicate via TCP/IP sockets. Graph Lakehouse communicates with Graph Studio via the secure, encrypted, gRPC-based Graph Studio protocol. Since Graph Lakehouse is SPARQL-compliant, you also have the option to enable and the standard SPARQL HTTP/S protocol for communication.
Open the TCP ports listed in the table below. The following image shows a representation of the connections.
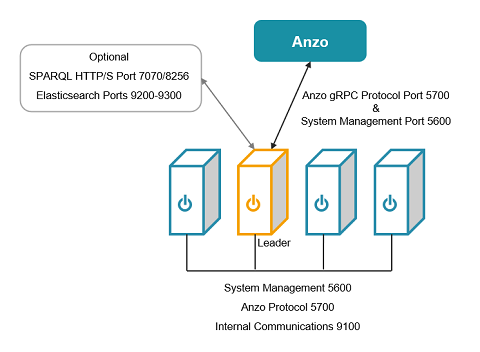
When configuring the firewall, keep in mind that Graph Lakehouse also needs to be able to connect directly to data sources if you plan to load data from databases and HTTP endpoints. Database connections are made via JDBC drivers on the Graph Lakehouse file system.
| Port | Description | Required Access |
|---|---|---|
| 5700 | The gRPC port for secure communication between Graph Lakehouse and Graph Studio |
The list below describes the access that is needed on port 5700:
|
| 5600 | The SSL system management port | The list below describes the access that is needed on port 5600:
|
| 9100 | The internal fabric communications port | The list below describes the access that is needed on port 9100:
|
| 9200-9300 (optional) | If you plan to connect to Elasticsearch, Graph Lakehouse needs access to the Elasticsearch http.port. | Between Elasticsearch and the Graph Lakehouse leader server |
| 7070 (optional) | Optional SPARQL HTTP port to enable if you want to give external applications access to Graph Lakehouse over HTTP | Between client applications and the Graph Lakehouse leader server |
| 8256 (optional) | Optional SPARQL HTTPS port to enable if you want to give external applications SSL access to Graph Lakehouse and/or use the command line interface, azgi | Between client applications and the Graph Lakehouse leader server |
Notes on Clusters and Virtual Environments
Graph Lakehouse requires that all elements of the infrastructure provide the same quality of service (QoS). Do not run Graph Lakehouse on the same server as any other software, including anti-virus software, except when in single-server mode and with an expectation of lowered performance. Providing the same QoS is especially important when using Graph Lakehouse in a clustered configuration. If any of the servers in the cluster perform additional processing, the cluster becomes unbalanced and may perform poorly. A single poor performing server degrades the other servers to the same performance level. All nodes require the same hardware specification and configuration. Also use static IP addresses or make sure that DHCP leases are persistent.
To ensure the maximum and most reliable QoS for CPU, memory, and network bandwidth, do not co-locate other virtual machines or containers (such as Docker containers) on the same hypervisor or container host. For hypervisor-managed VMs, configure the hypervisor to reserve the available memory for the Graph Lakehouse server. For clusters, make sure there is enough physical RAM to support all of the Graph Lakehouse servers, and reserve the memory via the hypervisor.
In addition, running memory compacting services such as Kernel Same-page Merging (KSM) impacts CPU QoS significantly and does not benefit Graph Lakehouse. Live migrations also impact the performance of VMs while they get migrated. While live migration can provide value for planned host maintenance, Graph Lakehouse performance may be impacted if live migrations occur frequently. For more information about Kernel Same-page Merging, see https://en.wikipedia.org/wiki/Kernel_same-page_merging.
Advanced configurations may benefit from CPU pinning on the hypervisor host and disabling CPU hyper-threading. For more information about CPU pinning, see https://en.wikipedia.org/wiki/Processor_affinity. For information about hyper-threading, see https://en.wikipedia.org/wiki/Hyper-threading.
Cambridge Semantics can provide benchmarks to establish relative cluster performance metrics and validate the environment.
For instructions on installing Graph Lakehouse, see Deploying a Static Graph Lakehouse Cluster.