Introduction to the Platform
The Graph Studio knowledge graph platform connects multiple components that enable you to ingest, transform, store, explore, and analyze various types of data. When determining which components to deploy in your environment, the primary distinction is made between structured and semi-structured (relational databases and flat files) and unstructured (documents, text snippets, web pages, emails, etc.) data sources. The list below introduces each of the components in the platform. An environment that includes all of these components could process both structured and unstructured data.
- Graph StudioServer: This required component is the administrative layer that helps organize all of the platform assets. It connects and manages the other components and provides the Graph Studio application, Administration, and Hi-Res Analytics user interfaces. Graph Studio manages all of the onboarded data and metadata and provides access control over the other components and artifacts in the system.
- Graph Lakehouse: This required component is Graph Studio’s in-memory graph OLAP engine. Graph Lakehouse stores all of your graphmarts and includes the Graph Data Interface (GDI), which is used to ingest (or virtualize) and transform all of the structured (and semi-structured) data that is onboarded to the platform.
- Distributed Unstructured: This optional component is a cluster of worker nodes that process unstructured documents (like PDFs, text snippets, emails, and knowledgebases) and convert them to the graph data model.
- Elasticsearch: This optional component supports the creation, storage, and search of indexes for both structured and unstructured data. Elasticsearch is required for onboarding unstructured data, and it is optional for structured data, depending on whether you want to be able to index and search your knowledge graphs.
- Shared File System: The required shared file storage system is a critical part of the platform. The Graph Studio Server and any Graph Lakehouse, Distributed Unstructured, and Elasticsearch servers need access to read and write shared files.
Component Details
The diagram below shows an overview of the platform components, their features, and how they work together. Details about the image and the components listed above are provided in the sections below the diagram.
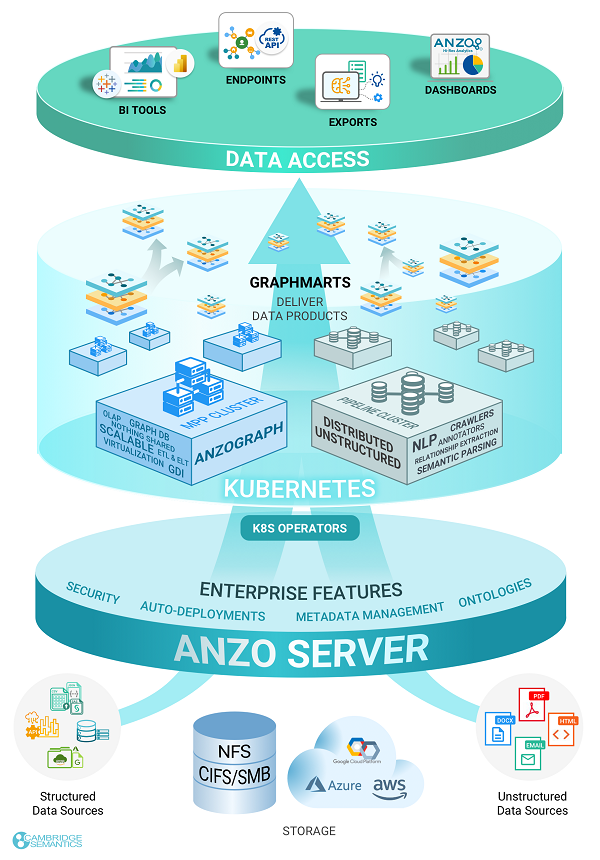
- Structured Data Sources
- Storage
- Unstructured Data Sources
- Graph Studio Server
- Kubernetes
- Graph Lakehouse
- Distributed Unstructured
- Graphmarts
- Data Access
Structured Data Sources
Graph Studio supports ingesting data from structured (relational databases) and semi-structured (flat files) data sources. Graph Studio connects directly to database sources via ODBC and JDBC drivers and supports loading data directly from CSV, JSON, XML, SAS, and Parquet files. Ingesting structured and semi-structured data sources is automated using Graph Lakehouse's Graph Data Interface (GDI). The GDI also supports ingesting or virtualizing data via manually written SPARQL queries.
Storage
The Graph Studio server and all installed platform components need to have read and write access to at least one shared file storage system. Though users can connect to and import files from various types of long-term storage systems, such as Hadoop Distributed File Systems (HDFS), File Transfer Protocol (FTP/S) systems, Google Cloud Platform (GCP) storage, Azure Cloud Storage, and Amazon Simple Cloud Storage Service (S3), it is important to deploy a file system that consistently offers good read and write support and can be shared by all of the components in the platform. Cambridge Semantics strongly recommends that you deploy an NFS and mount it in the same location on all component host servers. If you plan to set up Kubernetes (K8s) integration for dynamic deployments of Graph Studio components, an NFS is required. For more information, see Platform Shared File Storage Requirements.
Unstructured Data Sources
Unstructured data sources such as documents, PDFs, text snippets, web pages, emails, and content from knowledgebases are ingested using configurable, scalable pipelines. The pipelines generate a graph model for the unstructured text and extracted metadata, and they connect related entities so that the data can be fully integrated into the knowledge graph. The pipelines also build an Elasticsearch index that can be used for fully-integrated queries that search both free-text and semantic relationships within the knowledge graph. More information about unstructured data processing is included in Distributed Unstructured below.
Graph Studio Server
The Graph Studio Server connects all of the components and provides the user interfaces. Since Graph Lakehouse is stateless, Graph Studio manages updates to all of the data that is onboarded. It also manages all data models and other metadata such as data source configuration details, dataset catalog entries, registries, and access control definitions. For more information about how graph data is stored between Graph Studio and Graph Lakehouse see Graph Storage Concepts.
Kubernetes
The Graph Lakehouse, Distributed Unstructured, and Elasticsearch components can be deployed on "static" clusters, where the software is installed on pre-configured hardware, VMs, or cloud instances, or they can be deployed dynamically in a Kubernetes (K8s) cluster. If you choose to configure the K8s infrastructure, Graph Studio can launch components on-demand and then deprovision the resources when they are not in use. For more information about K8s integration with Graph Studio, see Kubernetes Concepts.
Graph Lakehouse
Graph Lakehouse is Graph Studio’s massively parallel processing (MPP) graph OLAP engine. To provide the highest performance possible, Graph Lakehouse stores all graph data and performs all analytic operations entirely in memory. You can scale Graph Lakehouse to run in environments ranging from a single server to tens or even hundreds of servers in a cluster. Graph Lakehouse also includes advanced analytic functions, such as the analytics that are run when datasets and graphmarts are profiled. And it includes the Graph Data Interface (GDI) plugin, which is used to ingest (or virtualize) and transform all of the structured (and semi-structured) data that is onboarded to Graph Studio. For more information about Graph Lakehouse, see Graph Lakehouse Architecture.
Distributed Unstructured
An Graph Studio Distributed Unstructured (DU) cluster consists of one leader instance and one or more worker instances. When a user runs an unstructured pipeline, Graph Studio sends the requests to the leader instance. The leader queues the requests and distributes them to the worker instances to process in parallel. In order to onboard unstructured data, a DU cluster and Elasticsearch are required components. For more information about DU and unstructured data processing, see Distributed Unstructured Overview.
Graphmarts
Whether data is ingested with the GDI or unstructured pipelines, it is converted from its original format to a new format that describes the data as a graph model. This format, Resource Description Framework (RDF), simplifies access to complex data and flexibly accommodates new data sources and use cases. The RDF data is added to graphmarts and loaded to Graph Lakehouse for further transformation and analytics. Graphmarts are collections data products or knowledge graphs that users can blend and enhance. Any subset of data can be combined in a graphmart for analysis. For more information about graphmarts, see Graphmart Concepts.
Data Access
Users have several options for accessing and analyzing knowledge graphs. Graph Studio’s Hi-Res Analytics application enables users to create dashboards for exploring and visualizing the data without needing to have specialized query knowledge. And, in line with Graph Studio's open standard architecture, graphmarts can be accessed using modern application program interfaces (APIs) like the Graph Studio REST API as well as SPARQL-compliant query endpoints. Graph Studio also offers standards-compliant Open Data Protocol (OData)-based endpoints as part of its Data on Demand service. The Data on Demand service provides access to data from business intelligence tools.
See Platform Requirements for an overview of the platform requirements as well as the specific requirements and recommendations for each of the platform components.