Publishing a Pipeline or Subset of Jobs
This topic provides guidance on publishing a pipeline or specific jobs in a pipeline.
- In the Anzo application, expand the Onboard menu and click Structured Data. Then click the Pipelines tab. Anzo displays the Pipelines screen, which lists the existing pipelines. For example:
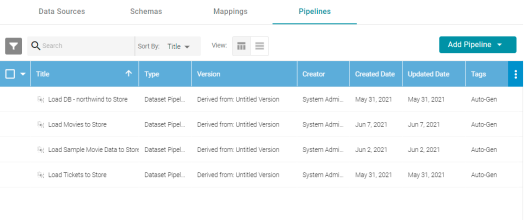
- Click the name of the pipeline that you want to publish. Anzo displays the pipeline overview screen. For example:

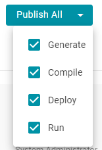
- To publish all of the jobs in the pipeline, click the Publish All button. To see the steps that will be executed when Publish All is clicked, click the arrow to the right of the name. For example, the image below shows that the ETL engine is configured to perform all steps when Publish All is clicked:
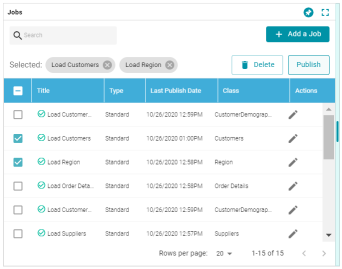
- To publish a subset of jobs instead of the entire pipeline, click the Jobs tab. The jobs are listed on the left side of the screen. For example:

In the list of jobs, select the checkbox next to each job that you want to publish, and then click the Publish button at the top of the table. For example:
When the pipeline or jobs finish, this run of the pipeline becomes the Default Edition. The Default Edition always contains the latest successfully published data for all of the jobs in the pipeline. If one or more of the jobs failed, those jobs are excluded from the Default Edition. If you publish the failed jobs at a later date or you create and publish additional jobs in the pipeline, the data from those jobs is also added to the Default Edition. For more information about editions, see Managing Dataset Editions.
The new or updated data set also becomes available in the Dataset catalog. From the catalog, you can generate graph data profiles and create graphmarts.