Distributed Unstructured Overview
One of Anzo’s differentiators as a leading enterprise knowledge graph and data integration platform is its treatment of unstructured data as a first-class citizen in the knowledge graph. Anzo onboards unstructured data—sources that contain text, such as PDFs, text messages, or text snippets embedded in structured data—directly into the knowledge graph using configurable, scalable pipelines. The pipelines generate a graph model for the unstructured text and extracted metadata, and they create connections between related entities so that the data can be fully integrated into the knowledge graph. In addition, the pipelines build an Elasticsearch index that can be used for highly performant, fully-integrated queries that search both free-text and semantic relationships within the knowledge graph.
The following sections provide an overview of the key features of Anzo’s unstructured data integration capabilities.
- Support for Crawling a Variety of Sources
- Text Processing and Annotation
- Text Indexing and Searching
- Scalability and Progress Tracking
Support for Crawling a Variety of Sources
Unstructured pipelines can process unstructured text from a large variety of data sources and formats. Configurable crawlers determine what unstructured text a pipeline will process. Crawlers can extract text from a variety of file formats, including PDFs, emails, HTML files, and Microsoft Word documents.
Unstructured pipelines can also be configured to crawl the knowledge graph itself for content to index and annotate—whether the graph contains free-text directly or references to document locations. When combined with Anzo’s data virtualization capabilities, this presents a flexible and powerful framework to rapidly process unstructured data and bring it into a knowledge graph from practically any source or repository in a modern data ecosystem.
Text Processing and Annotation
As a baseline, unstructured pipelines extract basic metadata about each document that they process, such as file location, file size, title, author, etc. The metadata is stored within the knowledge graph according to a standardized graph model. The pipelines generate HTML versions of the documents that can be rendered in a browser, and references to the document’s original binary are maintained in the graph. With this integration, unstructured content and its associated metadata can be connected and queried alongside any other information stored in the knowledge graph.
Beyond this baseline processing capability, Anzo enables more advanced annotation of unstructured text. Based on pattern matching and taxonomies or dictionaries of terms that already exist in the knowledge graph, annotators pull out facts or references in the text as annotations. The unstructured text and extracted annotations are also added to the knowledge graph, where they are described by a model (ontology) that is dynamically generated by the pipeline. Additionally, unstructured pipelines align the annotations to the source text and include highlights of the annotated text in the HTML version of the document. Once in the knowledge graph, the unstructured annotation data can easily be discovered, explored, and connected with basic document data as well as any other enterprise data in the graph.
The image below shows an HTML rendering of a document and its highlighted annotations in a Hi-Res Analytics dashboard:
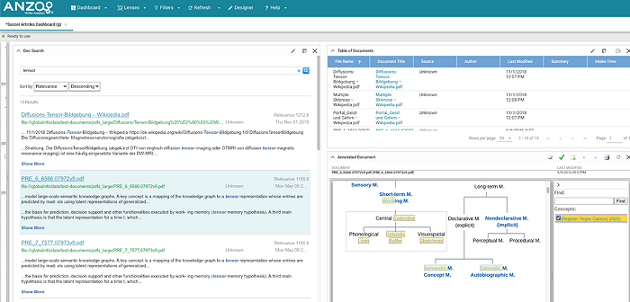
Unstructured pipelines also offer a flexible and agnostic extension framework to support integration with external NLP engines, such as Amazon Sagemaker, spaCy NER, and Amazon Comprehend, that can provide domain-specific or ML-driven text processing capabilities. Anzo’s pipelines provide unstructured plain text to the external components and then bring their output back into the knowledge graph, dynamically generating a graph model and connecting the extracted annotations to the document metadata and related entities. This can serve not only as an effective way to integrate state-of-the-art NLP insights with related data, but also as a flexible and transparent paradigm for validation and analysis of ML-driven NLP development.
Text Indexing and Searching
Unstructured pipelines create an Elasticsearch index of all of the unstructured files that are onboarded. The indexes contain references to URIs of related entities in the knowledge graph so that the indexed data can be joined directly against the rich and highly connected graph. When coupled with AnzoGraph’s native Elasticsearch SPARQL extension, users can seamlessly execute queries that combine scalable, performant free-text search with complex semantic queries against the graph. This integration can serve as a strong and flexible foundation for advanced, complex modern search applications.
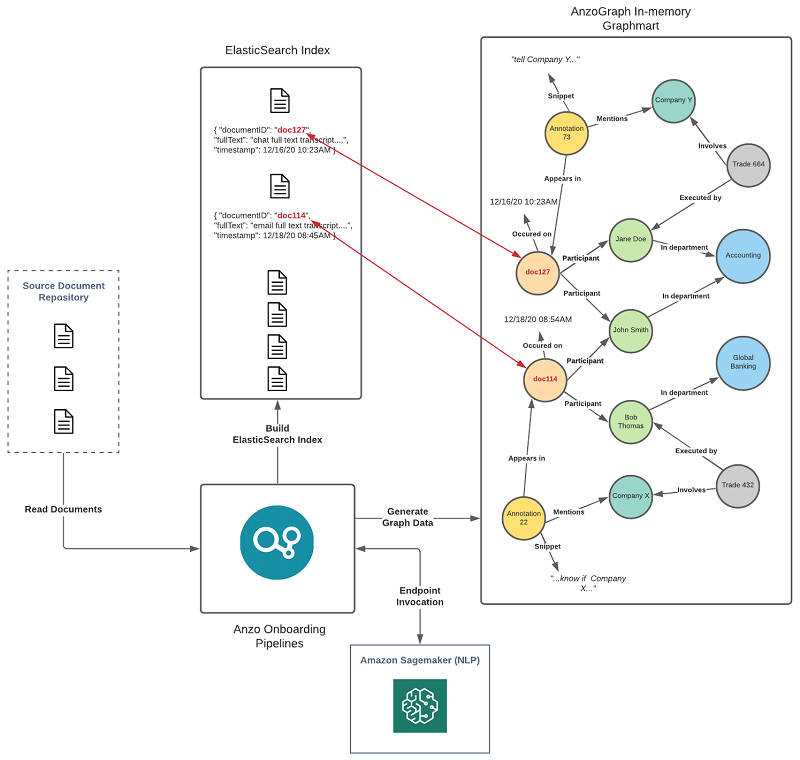
The diagram below shows an overview of the Elasticsearch integration during pipeline processing:
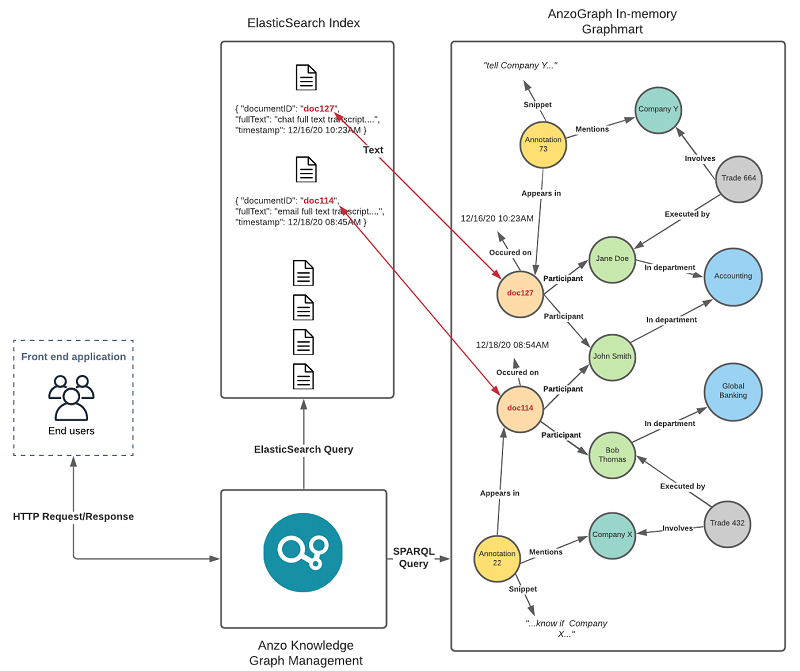
The following diagram shows an overview of Elasticsearch integration during querying and analysis:
Scalability and Progress Tracking
Unstructured pipelines run using a highly distributed and performant microservice cluster built using Akka. Worker nodes, which perform text processing in parallel, can be scaled up to increase the processing throughput of the pipeline. With this parallelization and scalability, pipelines are capable of processing tens of thousands of unstructured documents per minute. The pipeline processing services can be deployed statically on standard hardware or cloud instances, or they can be spun up dynamically using Anzo’s native Kubernetes integration
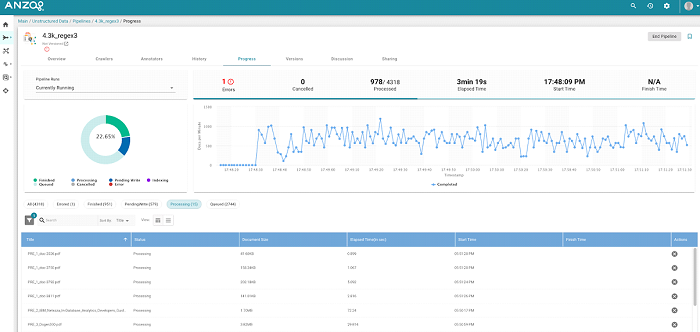
To track the progress of unstructured pipelines, Anzo offers a user interface that reports status information about each document as well as any issues encountered. The user interface also shows global statistics about a given pipeline run, including overall processing throughput, percentage complete, and time elapsed. This reporting module gives administrators a centralized view of progress and an easy way to oversee the pipeline as it operates.
The image below shows the unstructured pipeline reporting interface:
For more information about unstructured pipeline processing and the resulting artifacts, see Unstructured Onboarding Process Overview.