Graph Lakehouse Architecture
Graph Lakehouse uses massively parallel processing (MPP) to perform analytic operations on graph data conforming to RDF and RDF* standards. You can scale Graph Lakehouse to run in environments ranging from a single server to multiple servers in a cluster, in either on-premises or cloud environments.
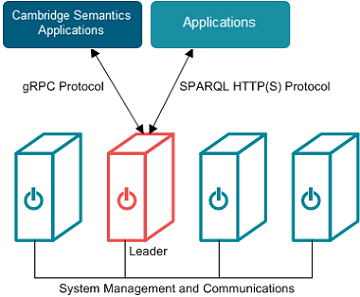
Though all servers in an Graph Lakehouse cluster store the system metadata and have the ability to perform leader operations, one server acts as the leader for the cluster. All client applications should connect to this server.
In-Memory Data Storage Architecture
To provide the highest performance possible, Graph Lakehouse stores all graph data and performs all analytic operations entirely in memory. At startup, Graph Lakehouse sets the number of shards (called "slices" in Graph Lakehouse) per node to the number of cores on a single server. To utilize massively parallel processing of queries, Graph Lakehouse distributes (as evenly as possible) the data into memory across all of the slices. When data is loaded, Graph Lakehouse hashes on subjects to determine how the data is distributed. Distributing on subject allows the database to avoid distributing data over the network under certain conditions. Every slice contains several blocks that store the triples.
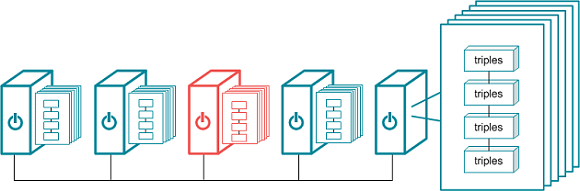
When installed in a cluster, Graph Lakehouse requires that all servers provide the same equivalent hardware and quality of service.
Leader and Query Processing
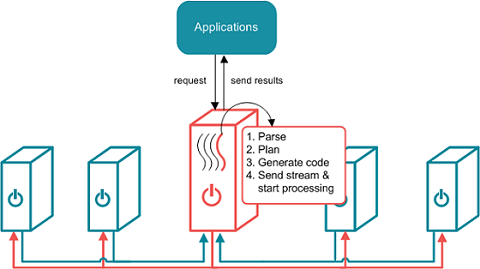
When an application sends a request, the leader node dedicates a thread to process the request. All other threads remain ready for subsequent requests. The leader routes the query through parsing and planning. The planner determines the steps that the query requires, for example, whether a hash join, merge join, or an aggregation step is needed. The planner passes the final query plan to the code generator, which assembles the groups of steps into segments. The code generator then packages all of the segments for the query into a stream. The leader sends the stream to all of the nodes in the cluster and to its own slices. The nodes process the stream in parallel; each node dedicates a thread to process each segment. The nodes then return the results to the leader to send to the application.
For information about server requirements and recommendations, see Planning and Deployment Guidelines.