Auto-Ingesting Imported Data
This topic provides instructions for onboarding data from structured data sources using the auto-ingest process. When you auto-ingest data, Anzo automatically generates mappings, a model, and an ETL pipeline. You can also link new data to an existing model.
- In the Anzo console, expand the Onboard menu and click Structured Data. Anzo displays the Data Sources screen.
- Click the Schemas tab. Anzo displays the Schemas screen, which lists the existing schemas. For example:
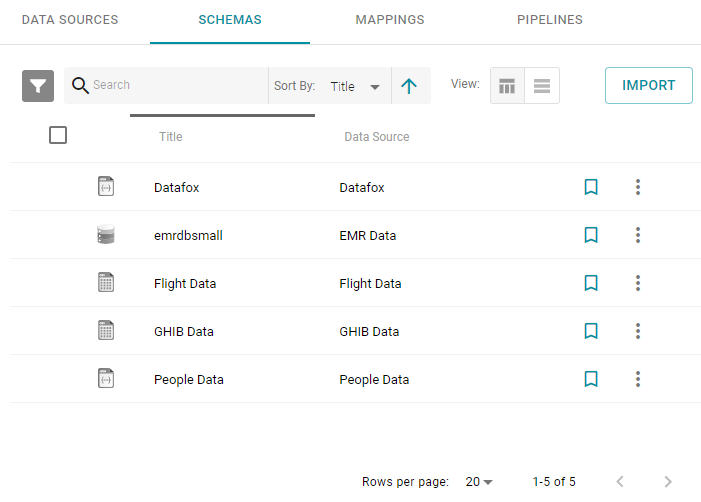
- On the Schemas screen, click the name of the schema for the data that you want to auto-ingest. Anzo displays the Tables screen for the source. For example:
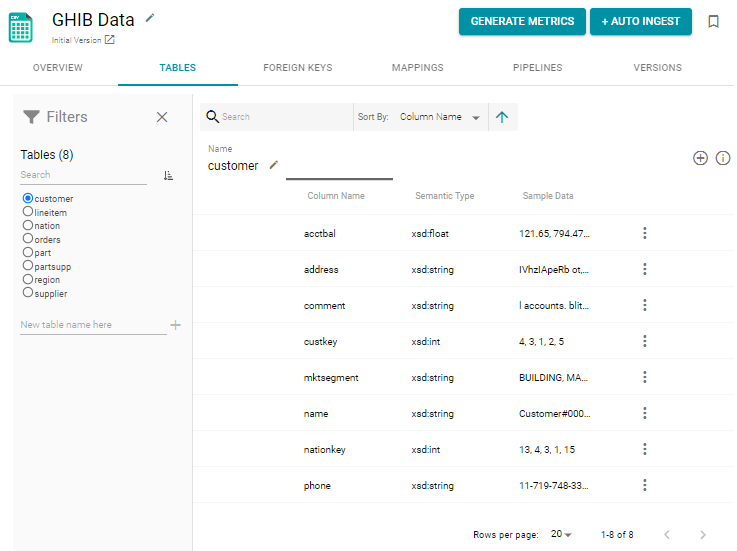
- Click the Auto Ingest button. Anzo opens the Auto Ingest dialog box and automatically populates the data source as well as the graph data source if only one graph source is configured. In addition, Anzo selects the ETL engine if only one engine is configured.

- If necessary, click the Graph Data Source field and select the graph data source for this data. For information about creating a graph data source, also known as an Anzo data store, see Creating an Anzo Data Store.
- If necessary, click the Auto Map Engine Config field and select the ETL engine to use for the project.
- By default, Anzo selects the Select all tables radio button to ingest the data for all tables in the schema. If you do not want to add all tables, click the Custom select radio button and then select each of the tables to add.
- By default, the auto-ingestion process is configured to create a new data model. If you want to customize the URIs or transform property names in the new model or if you want to associate this data source with an existing model, click Advanced to view additional configuration options. If you do not want to change options, continue to the next step. Click a description below to view instructions for configuring the auto-ingest workflow accordingly:
 Create a new model with the specified URIs and/or property name conversion
Create a new model with the specified URIs and/or property name conversionFollow the instructions below to customize the model that Anzo creates.
- Select the Create New Model radio button. Additional options become available:
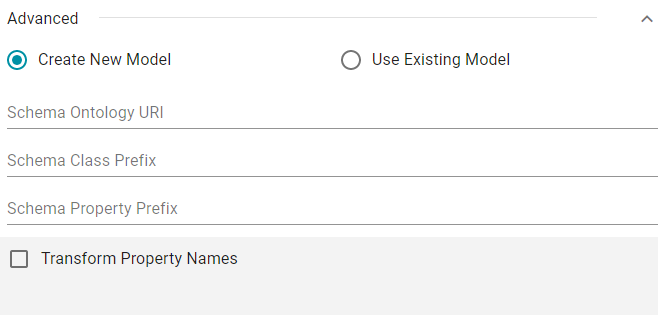
- If you want to define the model, class, or property URIs, type the desired prefixes in the Schema Ontology URI, Schema Class Prefix, and Schema Property Prefix fields:
- Schema Ontology URI: The URI for the data model. When the Schema Ontology URI field is blank, Anzo generates the model URI for this schema with the following format:
http://cambridgesemantics.com/ont/autogen/xx/schema_name
Where xx is a hash snippet based on the model's globally unique identifier (GUID). If you want Anzo to use a specific URI format when creating the model for this schema, you can type that URI into the Schema Ontology URI field. For example, you can specify a URI such as
http://mycompany.com.ontology/movies. This format results in an ontology URI ofhttp://mycompany.com.ontology/movies.Important: Make sure that you type a unique Schema Ontology URI for each schema. Schemas with the same model URI overwrite each other when the projects run.
- Schema Class Prefix: The URI prefix format to use for classes in the data model. When the Schema Class Prefix field is blank, Anzo generates the ontology's class URIs using the following format:
http://cambridgesemantics.com/ont/autogen/xx/schema_name#class_name
Where xx is a hash snippet based on the model's GUID. If you want Anzo to use a specific URI format when creating classes in the model, you can type that URI into the Schema Class Prefix field. For example, you can specify a URI such as
http://mycompany.com.ontology/class. This format results in class URIs likehttp://mycompany.com.ontology/class#className.Tip: To generate models from multiple sources and use the same class URIs across models, you can set the Schema Class Prefix to the same value across schemas.
- Schema Property Prefix: The URI prefix format to use for properties in the data model. When the Schema Property Prefix field is blank, Anzo generates the ontology's property URIs using the following format:
http://cambridgesemantics.com/ont/autogen/xx/schema_name#class_name_property_name
Where xx is a hash snippet based on the model's GUID. If you want Anzo to use a specific URI format when creating properties in the model, you can type that URI into the Schema Property Prefix field. For example, you can specify a URI such as
http://mycompany.com.ontology/property. This format results in property URIs likehttp://mycompany.com.ontology/property#className_propertyName.Tip: To generate models from multiple sources and use the same property URIs across models, you can set the Schema Property Prefix to the same value across schemas.
- Schema Ontology URI: The URI for the data model. When the Schema Ontology URI field is blank, Anzo generates the model URI for this schema with the following format:
- If you want to transform property names to upper or lower case letters, select the Transform Property Names checkbox. Then select the To lowercase radio button if you want to convert property names to lowercase or select the To UPPERCASE radio button if you want to convert property names to uppercase.
Use an existing model for this workflowFollow the instructions below to associate this source with an existing model.
- Select the Use Existing Model radio button. Additional options become available:
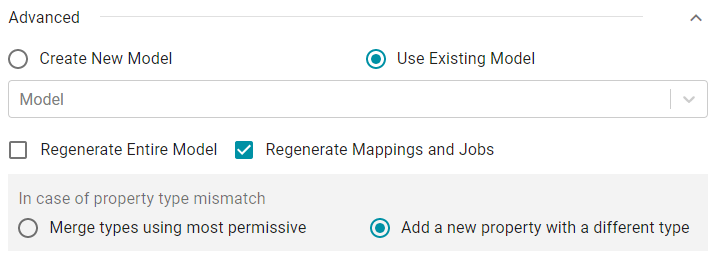
- Select the model to use from the Model drop-down list.
Specify whether to regenerate artifacts and which artifacts to regenerate. The list below describes each of the options:
- Regenerate Entire Model: Selecting this option means that Anzo deletes all entities from the existing model and recreates them. The model that results from the current ingestion process will contain only the data from the current process. For example, if a previous run generated a model that contains classes A, B, and C, and the current data contains Classes C, D, and E, selecting Regenerate Entire Model results in a model that contains only classes C, D, and E. If Regenerate Entire Model is NOT selected, the resulting model will contain classes A, B, C, D, and E.
- Regenerate Mappings and Jobs: Selecting this option means that Anzo deletes all entities from the existing mappings and jobs and recreates them. The artifacts that result from the current ingestion process will contain only the data from the current process. For example, if a previous run generated mappings and jobs that contain tables A and B and the current run is ingesting tables C and D, selecting Regenerate Mappings and Jobs results in artifacts that contain only tables C and D. If Regenerate Mappings and Jobs is NOT selected, the resulting artifacts contain tables A, B, C, and D.
- Specify what Anzo should do if there is a property type mismatch between the existing model and the new schema:
- Merge types using most permissive: Anzo looks at the inferred types in both schemas and chooses the type that covers all inputs. In most cases Anzo sets the type to String.
- Add a new property with a different type: If Anzo encounters a type mismatch, it adds a new property with the new type to the existing model.
Note: When associating column names in the new schema with the existing model, the match is case-insensitive. Anzo matches the names based on the spelling. For example, "myInt" matches "MYint."
- Select the Create New Model radio button. Additional options become available:
- Click Create. Anzo creates a pipeline (or updates the existing one) and generates or updates the model and mappings according to the options you specified.
- In the main navigation menu under Onboard, click Structured Data. Then click the Pipelines tab.
- Click the name of the pipeline to run. Anzo displays the pipeline overview screen. For example:

- If you would like to see the jobs that Anzo created for this data source, click the Jobs tab. The jobs are listed on the left side of the screen. A job exists for each of the tables that were imported. For example:

- To run the jobs, click Publish. Anzo runs the pipeline and generates the resulting RDF files in a new subdirectory under the specified base directory for the data store.
When the pipeline finishes, you can add the new data set to a graphmart and load it to AnzoGraph so that you can explore and analyze the data using Hi-Res Analytics. See Creating Graphmarts and Loading Data to AnzoGraph for instructions. For information about modifying the auto-generated components, see Working with Mappings, Modeling Data, Working with Schemas, and Working with Pipelines.