Creating a K8s Cluster with Google Kubernetes Engine
This topic provides instructions for setting up a Kubernetes cluster with Google Kubernetes Engine (GKE) using the Google command line tool, gcloud.
- Configure Your Workstation
- Create IAM Roles for GKE Permissions
- Configure the Networking for the GKE Cluster
- Create the GKE Cluster
- Create Nodepools in the GKE Cluster
Configure Your Workstation
This section describes the requirements for configuring a workstation to use for creating and managing the GKE cluster. This workstation will be used to launch the GKE cluster and its nodepools and connect to the cluster API endpoint.
| Component | Requirement |
|---|---|
| Operating System | The operating system for the workstation must be CentOS 7.6 or higher. |
| Networking | The workstation should be in the same VPC network as the GKE cluster or on a network that is routable from the VPC. For information the GKE cluster network, see Configure the Networking for the GKE Cluster. |
| Software |
|
| CSI-Supplied GKE Scripts | Cambridge Semantics provides scripts and configuration files to use for provisioning the GKE cluster and its nodepools. Download the files to the workstation. Details about the files are provided in GKE Cluster Creation Scripts and Configuration Files below. |
Installing Google Cloud SDK
Follow the instructions below to install Google Cloud SDK on your workstation.
- Run the following command to configure access to the Google Cloud repository:
sudo tee -a /etc/yum.repos.d/google-cloud-sdk.repo << EOM [google-cloud-sdk] name=Google Cloud SDK baseurl=https://packages.cloud.google.com/yum/repos/cloud-sdk-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg EOM
- Run the following command to install Cloud SDK:
sudo yum install kubectl google-cloud-sdk
The following packages are installed:
google-cloud-sdk-app-engine-grpc google-cloud-sdk-pubsub-emulator google-cloud-sdk-app-engine-go google-cloud-sdk-cloud-build-local google-cloud-sdk-datastore-emulator google-cloud-sdk-app-engine-python google-cloud-sdk-cbt google-cloud-sdk-bigtable-emulator google-cloud-sdk-datalab google-cloud-sdk-app-engine-java
- Next, configure the default project and region settings for the Cloud SDK:
- Run the following command to set the default project for the GKE cluster:
gcloud config set project project_ID
Where project_ID is the Project ID for the project in which the GKE cluster will be provisioned.
- If you work with zonal clusters, run the following command to set the default compute zone for the GKE cluster:
gcloud config set compute/zone compute_zone
Where compute_zone is the default compute zone for the GKE cluster. For example:
gcloud config set compute/zone us-central1-a
- If you work with regional clusters, run the following command to set the default region for the GKE cluster:
gcloud config set compute/region compute_region
Where compute_region is the default region for the GKE cluster. For example:
gcloud config set compute/region us-east1
- To make sure that you are using the latest version of the Cloud SDK, run the following command to check for updates:
gcloud components update
- Run the following command to set the default project for the GKE cluster:
GKE Cluster Creation Scripts and Configuration Files
Cambridge Semantics provides a package of files that enable users to manage the configuration, creation, and deletion of GKE clusters and nodepools. The files and their directory structure are shown below.
├── common.sh ├── conf.d │ ├── k8s_cluster.conf │ ├── nodepool_anzograph.conf │ ├── nodepool_anzograph.tuner.conf │ ├── nodepool_common.conf │ ├── nodepool.conf │ ├── nodepool_dynamic.conf │ ├── nodepool_dynamic.tuner.conf │ └── nodepool_operator.conf ├── create_k8s.sh ├── create_nodepools.sh ├── delete_k8s.sh └── delete_nodepools.sh
- The create_k8s.sh and create_nodepools.sh scripts are used to provision the GKE cluster and any number of nodepools in the cluster. And the delete_k8s.sh and delete_nodepools.sh scripts are used to remove the cluster or nodepools.
- The configuration file, k8s_cluster.conf in the conf.d directory, is used with the create_k8s and delete_k8s scripts and supplies the cluster-wide configuration parameters such as network, region, and timeout values.
- The configuration files, nodepool*.conf in the conf.d directory, contain nodepool settings. The files include sample configuration values for different types of nodepools, such as for Spark, Elasticsearch, or AnzoGraph. Each file is used to create one type of nodepool.
- The common.sh script is used by the create and delete cluster and nodepool scripts.
The instructions for Create the GKE Cluster and Create Nodepools in the GKE Cluster provide more details about the scripts and configuration files.
Create IAM Roles for GKE Permissions
Two Google Identity and Access Management (IAM) custom roles need to be created to grant the appropriate permissions to users who will set up and manage the GKE cluster and/or deploy applications using the K8s service:
- GKE Cluster Admin: The cluster administrator is responsible for GKE cluster management tasks such as creating and deleting clusters and nodepools and adding and removing containers in the Google Container Registry (GCR).
- GKE Cluster Developer: The cluster developer uses the GKE cluster that the admin creates. The user needs full access to k8s API objects to manage namespaces and creates K8s objects like pods and services.
The roles to add to Google Cloud are provided below. For information about creating roles, see Creating and Managing Custom Roles in the Google Cloud documentation. For information about the Kubernetes role-based access control (RBAC) system, see Role-Based Access Control in the Kubernetes Engine documentation.
GKE Cluster Admin Role
The following IAM role applies the minimum permissions needed for a cluster administrator who will create and manage the GKE cluster. Save the contents below as a JSON file. For example, /home/centos/gke-cluster-admin.json, and then run the following command to create the role:
gcloud iam roles create --project project_name --file=/path/filename.json
{
"name": "customClusterAdminRole",
"title": "Custom Role for GKE Cluster Admin",
"includedPermissions": [
"compute.networks.delete",
"compute.networks.get",
"compute.networks.list",
"compute.networks.updatePolicy",
"compute.routers.create",
"compute.routers.delete",
"compute.routers.get",
"compute.routers.list",
"compute.routers.update",
"iam.serviceAccounts.actAs",
"iam.serviceAccounts.get",
"iam.serviceAccounts.list",
"resourcemanager.projects.get",
"resourcemanager.projects.list",
"container.clusters.create",
"container.clusters.delete",
"container.clusters.get",
"container.clusters.list",
"container.clusters.update",
"container.operations.*",
"resourcemanager.projects.get",
"Resourcemanager.projects.list"
],
"stage": "BETA"
}
GKE Cluster Developer Role
The following IAM role applies the minimum permissions needed for a GKE cluster developer. Save the contents below as a JSON file. For example, /home/centos/gke-cluster-developer.json, and then run the following command to create the role:
gcloud iam roles create --project project_name --file=/path/filename.json
{
"name": "customClusterDeveloperRole",
"title": "Custom Role for GKE Cluster Developer",
"includedPermissions": [
"container.*",
"resourcemanager.projects.get",
"resourcemanager.projects.list",
"container.apiServices.*",
"container.backendConfigs.*",
"container.bindings.*",
"container.certificateSigningRequests.create",
"container.certificateSigningRequests.delete",
"container.certificateSigningRequests.get",
"container.certificateSigningRequests.list",
"container.certificateSigningRequests.update",
"container.certificateSigningRequests.updateStatus",
"container.clusterRoleBindings.get",
"container.clusterRoleBindings.list",
"container.clusterRoles.get",
"container.clusterRoles.list",
"container.clusters.get",
"container.clusters.list",
"container.componentStatuses.*",
"container.configMaps.*",
"container.controllerRevisions.get",
"container.controllerRevisions.list",
"container.cronJobs.*",
"container.csiDrivers.*",
"container.csiNodes.*",
"container.customResourceDefinitions.*",
"container.daemonSets.*",
"container.deployments.*",
"container.endpoints.*",
"container.events.*",
"container.horizontalPodAutoscalers.*",
"container.ingresses.*",
"container.initializerConfigurations.*",
"container.jobs.*",
"container.limitRanges.*",
"container.localSubjectAccessReviews.*",
"container.namespaces.*",
"container.networkPolicies.*",
"container.nodes.*",
"container.persistentVolumeClaims.*",
"container.persistentVolumes.*",
"container.petSets.*",
"container.podDisruptionBudgets.*",
"container.podPresets.*",
"container.podSecurityPolicies.get",
"container.podSecurityPolicies.list",
"container.podTemplates.*",
"container.pods.*",
"container.replicaSets.*",
"container.replicationControllers.*",
"container.resourceQuotas.*",
"container.roleBindings.get",
"container.roleBindings.list",
"container.roles.get",
"container.roles.list",
"container.runtimeClasses.*",
"container.scheduledJobs.*",
"container.secrets.*",
"container.selfSubjectAccessReviews.*",
"container.serviceAccounts.*",
"container.services.*",
"container.statefulSets.*",
"container.storageClasses.*",
"container.subjectAccessReviews.*",
"container.thirdPartyObjects.*",
"container.thirdPartyResources.*",
"container.tokenReviews.*",
"compute.machineTypes.list",
"storage.buckets.list",
"storage.objects.get",
"storage.objects.list"
],
"stage": "BETA"
}
Configure the Networking for the GKE Cluster
The GKE cluster can be deployed into a new or existing VPC. Any networking components that do not exist, such as subnets for hosting the nodepools and a NAT gateway for outbound internet access, are created by the GKE service when the K8s cluster is deployed. Cambridge Semantics recommends that you enable Network Policies. For information, see Configuring Network Policies for Applications in the Kubernetes Engine documentation.
| Note | If Anzo is currently deployed, Cambridge Semantics recommends that you provision the GKE cluster in the same network as Anzo. |
Create the GKE Cluster
Follow the steps below to configure and then provision the K8s control plane that will manage the nodepools that will be used with Anzo to deploy K8s applications.
Follow the Google Cloud Best Practices
Before provisioning the cluster, Cambridge Semantics recommends that you implement the following best practices:
- Disable the Kubernetes Dashboard if it is enabled.
- Enable Stackdriver Logging. For information, see Stackdriver Logging in the Google Cloud documentation.
Configure the Cluster
Before creating the GKE cluster, specify the networking and control plane configuration to use by creating a configuration file based on the sample k8s_cluster.conf file in the conf.d directory. Follow the instructions below to configure the cluster.
- In the conf.d directory, copy k8s_cluster.conf to create a file to customize. You can specify any name for the .conf file.
Note: If you want to create multiple GKE clusters, you can create multiple .conf files. When you create a cluster (using create_k8s.sh), you specify the name of the .conf file to use for that cluster.
- Open the new .conf file for editing. The file includes the list of parameters and sample values. Modify the values as needed. The table below describes each setting.
Parameter Description Sample Value NETWORK_BGP_ROUTING The Compute Engine resource type for the cluster. Valid values are "global," "regional," or "zonal." regional NETWORK_SUBNET_MODE Specifies the method to use to create subnets. For example, "automatically" or "manually." custom NETWORK_ROUTER_NAME The name to assign to the Cloud Router. csi-cloudrouter NETWORK_ROUTER_MODE The route advertisement mode for the Cloud Router. custom NETWORK_ROUTER_ASN The Border Gateway Protocol (BGP) autonomous system number. 64512 NETWORK_ROUTER_DESC A description of the Cloud Router. Cloud router for K8S NAT. NETWORK_NAT_NAME The name to assign to the NAT gateway. csi-natgw NETWORK_NAT_UDP_IDLE_TIMEOUT The timeout value to use for UDP connections to the NAT gateway. 60s NETWORK_NAT_ICMP_IDLE_TIMEOUT The timeout value to use for ICMP connections to the NAT gateway. 60s NETWORK_NAT_TCP_ESTABLISHED_IDLE_TIMEOUT The timeout value to use for TCP established connections to the NAT gateway. 60s NETWORK_NAT_TCP_TRANSITORY_IDLE_TIMEOUT The timeout value to use for TCP transitory connections to the NAT gateway. 60s K8S_CLUSTER_NAME The name to give to the cluster. cloud-k8s-cluster K8S_CLUSTER_PODS_PER_NODE The maximum number of pods that can be hosted on each EC2 instance. 10 K8S_CLUSTER_ADDONS A comma-separated list of the addons to enable for the cluster. HttpLoadBalancing,
HorizontalPodAutoscalingGKE_MASTER_VERSION The Kubernetes version to use to deploy the GKE cluster. 1.13.7-gke.8 GKE_MASTER_NODE_COUNT_PER_LOCATION The number of master nodes to create in each of the cluster's zones. 1 GKE_NODE_VERSION The Kubernetes version to use to deploy nodes. 1.13.7-gke.8 GKE_IMAGE_TYPE The base operating system for the nodes in the cluster. COS GKE_MAINTENANCE_WINDOW The time of day to perform maintenance on the cluster. 06:00 GKE_MASTER_ACCESS_CIDRS The list of CIDR blocks (up to 50) that have access to the Kubernetes master via HTTPS. 10.128.0.0/9 K8S_PRIVATE_CIDR The IP address range (in CIDR notation) for the pods in this cluster. 172.16.0.0/20 K8S_SERVICES_CIDR The IP address range for the services. 172.17.0.0/20 GCLOUD_NODES_CIDR The CIDR for new subnet that will be created for the K8s cluster. 192.168.0.0/20 K8S_API_CIDR The IPv4 CIDR range to use for the master network. The range should have a subnet mask of /28 and should be used in conjunction with the --enable-private-nodesflag.192.171.0.0/28 K8S_HOST_DISK_SIZE The size of the boot disks on the nodes. 50GB K8S_HOST_DISK_TYPE The type of boot disk to use. pd-standard K8S_HOST_MIN_CPU_PLATFORM The minimum CPU platform to use. Not set K8S_POOL_HOSTS_MAX The maximum number of nodes to allocate for the default initial nodepool. 1000 K8S_METADATA The compute engine metadata (in the format key=val,key=val) to make available to the guest operating system running on nodes in the nodepool. disable-legacy-endpoints=true K8S_MIN_NODES The minimum number of nodes in the nodepool. 1 K8S_MAX_NODES The maximum number of nodes in the nodepool. 3 GCLOUD_RESOURCE_LABELS Labels to apply to the Google Cloud resources in use by the GKE cluster (unrelated to Kubernetes labels). deleteafter=false,
owner=userGCLOUD_VM_LABELS Kubernetes labels to apply to all nodes in the nodepool. deleteafter=false,
description=k8s_cluster,
owner=user,
schedule=keep-aliveGCLOUD_VM_TAGS A comma-separated list of tags to add to the cluster. tag1,tag2 GCLOUD_VM_MACHINE_TYPE The machine type to use for the cluster master nodes. n1-standard-1 GCLOUD_VM_SSD_COUNT The number of local SSD disks to provision on each node. 0 GCLOUD_PROJECT_ID The Project ID for the GKE cluster. cloud-project-1592 GCLOUD_NETWORK The compute engine network for the GKE cluster. devel-network GCLOUD_NODES_SUBNET_SUFFIX The suffix to use for subnets. nodes GCLOUD_CLUSTER_REGION The region for the GKE cluster. us-central1 GCLOUD_NODE_LOCATIONS The zones to replicate the nodes in. us-central1-f GCLOUD_NODE_TAINTS Indicates the schedule settings for the nodes. key1=val1:NoSchedule,
key2=val2:PreferNoScheduleGCLOUD_NODE_SCOPE The permissions or access scopes the nodes should have. gke-default - Save and close the configuration file, and then proceed to Create the Cluster.
Create the Cluster
To create a GKE cluster that is configured according to the file you created in Configure the Cluster, run the create_k8s.sh script with the following command:
$ ./create_k8s.sh cluster_config_filename [ -f ] [ -h ]
| Argument | Description |
|---|---|
| cluster_config_filename | Required name and extension of the configuration file that supplies the parameter values for this cluster. You do not need to specify the path to the conf.d directory. |
| -f | Optional flag. If specified, the script will prompt for confirmation before proceeding with each stage involved in creating the cluster and its components. |
| -h | Optional flag. If specified, the help will be displayed. |
For example:
$ ./create_k8s.sh k8s_cluster.conf
This script creates a GKE cluster along with the networking specifications described by the .conf file. The script deploys the infrastructure, such as a new subnets, using the CIDRs specified in the .conf file. It also creates a cloud router and NAT gateway.
When cluster creation is complete, proceed to Create Nodepools in the GKE Cluster to add one or more nodepools to the cluster.
Create Nodepools in the GKE Cluster
Follow the steps below to configure and then provision the nodepools in the GKE cluster that will be used to deploy K8s applications with Anzo.
Configure a Nodepool
Before creating a nodepool, supply the configuration values to use for that nodepool based on a sample nodepool*.conf file in the conf.d directory. Follow the instructions below to configure a nodepool.
- Depending on the application that you want to deploy with this nodepool, determine the configuration file to copy and customize from the nodepool*.conf sample files in the conf.d directory:
- nodepool_anzograph.conf: The sample values in this file configure an autoscaling group for an AnzoGraph nodepool. The specified instance type offers high CPU and memory resources.
- nodepool_anzograph.tuner.conf: The sample values in this file include the Linux kernel configuration settings that are ideal for AnzoGraph. The parameters disable Transparent Huge Pages (THP) for best performance and increase the memory mapping (mmap) limit to help avoid out of memory situations.
- nodepool_common.conf: The sample values in this file configure a common nodepool, with a relatively small instance type that can be used for smaller workloads. This type of configuration is typically used to deploy K8s services that manage the instances in the cluster.
- nodepool.conf:
- nodepool_dynamic.conf: The sample values in this file configure an autoscaling group for a dynamic nodepool, where the instance type offers medium to large CPU and memory resources that are reasonable for deploying Elasticsearch and Spark applications.
- nodepool_operator.conf: The sample values in this file configure an autoscaling group for an operator nodepool that can be used to deploy services.
- Copy the appropriate configuration file to create the version to customize. You can specify any name for the .conf file.
- Open the new .conf file for editing. The file includes the list of parameters and sample values. Modify the values as needed. The table below describes the settings.
Parameter Description Sample Value DOMAIN Name of domain that hosts the K8s nodepool. acme KIND The type of pods that will be hosted on this nodepool. anzograph GCLOUD_CLUSTER_REGION The region that the GKE cluster is deployed in. us-central1 GCLOUD_NODE_TAINTS Indicates the schedule settings for the nodes. cambridgesemantics.com/dedicated=anzograph:NoSchedule,
cloud.google.com/gke-preemptible="false":PreferNoScheduleGCLOUD_PROJECT_ID The Project ID for the nodepool. cloud-project-1592 GKE_IMAGE_TYPE The base operating system for the nodes. cos_containerd K8S_CLUSTER_NAME The name of GKE cluster to add the nodepool to. acme-k8s-cluster NODE_LABELS A list of Kubernetes labels to apply to all nodes in the nodepool. cambridgesemantics.com/node-purpose=anzograph,
cambridgesemantics.com/description=k8snode,
schedule=keep-alive,owner=user1,
deleteafter=noMACHINE_TYPES A space-separated list of the instance types that can be used for the nodes. n1-standard-16 n1-standard-32 TAGS A comma-separated list of the Compute Engine tags to apply to all nodes in the nodepool. csi-sdl METADATA The compute engine metadata (in the format key=val,key=val) to make available to the guest operating system running on nodes in the nodepool. disable-legacy-endpoints=true MAX_PODS_PER_NODE The maximum number of pods that can be hosted on each instance. 8 MAX_NODES The maximum number of instances that can be deployed in the nodepool. 8 MIN_NODES The minimum number of instances in the nodepool. 0 NUM_NODES The number of nodes in the nodepool in each of the cluster's zones. 1 DISK_SIZE The size of the boot disks on the nodes. 200Gb DISK_TYPE The type of boot disk to use. pd-standard - Save and close the configuration file, and then proceed to Create a Nodepool. Repeat the steps above to configure additional nodepools.
Create a Nodepool
To create a nodepool that is configured according to a file you created in Configure a Nodepool, run the create_nodepools.sh script with the following command:
$ ./create_nodepools.sh nodepool_config_filename [ -f ] [ -h ]
| Argument | Description |
|---|---|
| nodepool_config_filename | Required name and extension of the configuration file that supplies the parameter values for this nodepool. You do not need to specify the path to the conf.d directory. |
| -f | Optional flag. If specified, the script will prompt for confirmation before proceeding with each stage involved in creating the nodepool and its components. |
| -h | Optional flag. If specified, the help will be displayed. |
For example:
$ ./create_nodepools.sh anzograph_nodepool.conf
This script creates the nodes in the nodepool according to the specifications provided in the .conf file. Repeat the process to create additional nodepools.
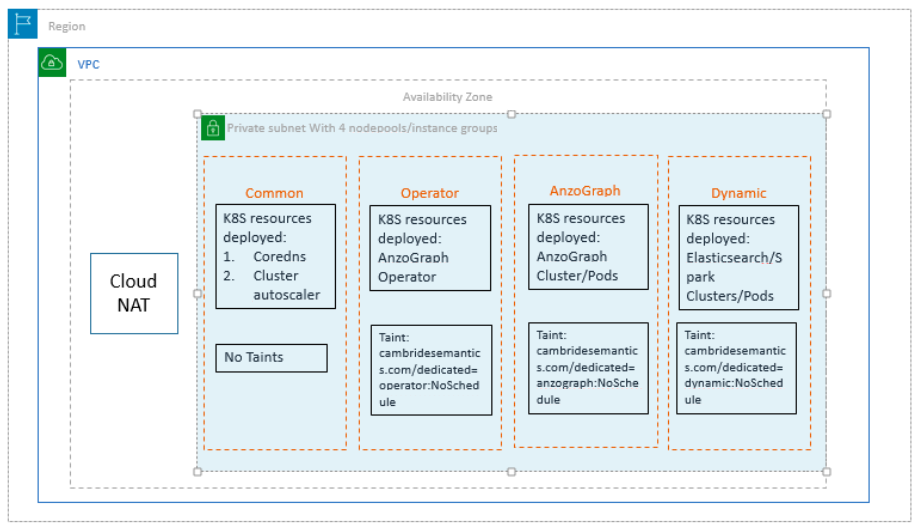
The diagram below shows the architecture for a sample deployment with four nodepools.
The next step is to create a Cloud Location in Anzo so that Anzo can connect to the GKE cluster and deploy applications. See Managing Cloud Locations.