Re-Ingesting an Updated Data Source
Follow the instructions below to re-ingest the data for a data source whose schema has been updated. The procedure below focuses on configuring the workflow to reuse the existing model and update the mappings and ETL jobs for the existing pipeline. For instructions on ingesting a new data source, see Ingesting a New Data Source.
If the source data is updated but the schema does not change, or if the model or mappings are modified and the schema is not affected, you do not need to re-ingest the source using the Ingest workflow. You can simply republish the pipeline or the affected jobs in the pipeline. See Publishing a Pipeline or Subset of Jobs for more information.
For information about updating a CSV data source if a file is updated, see How do I update Anzo if a file in my CSV data source changes?
- In the Anzo application, expand the Onboard menu and click Structured Data. Anzo displays the Data Sources screen, which lists the available data sources. For example:
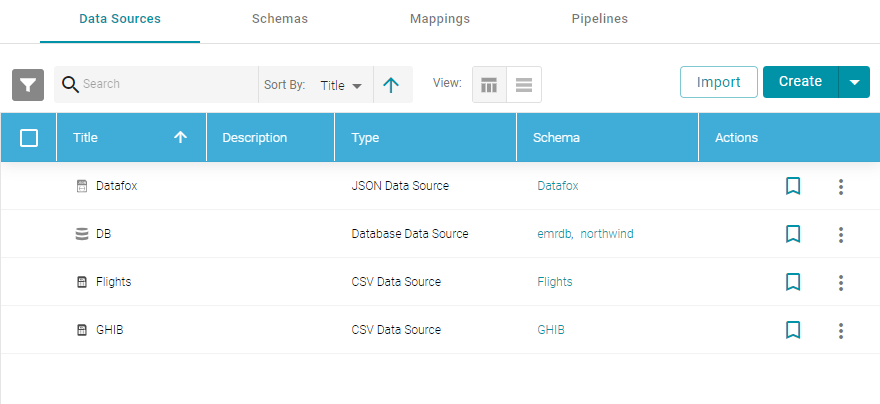
- On the Data Sources screen, click the name of the data source to re-ingest. Anzo displays the Tables screen. For example:
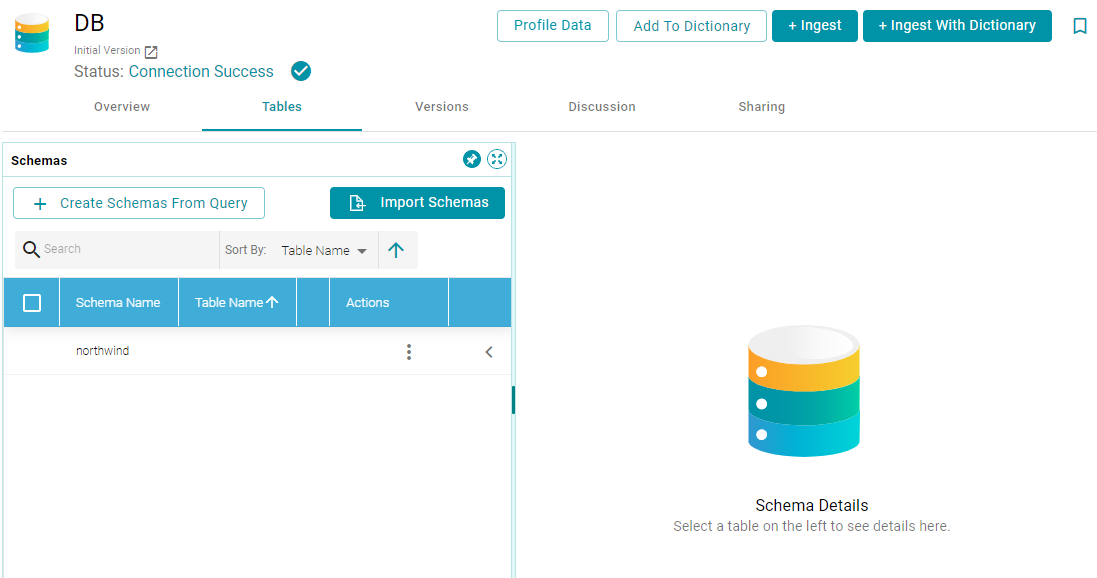
- Reload any changed schemas into Anzo by clicking the menu icon (
 ) in the Actions column for the schema and selecting Reload Schema. For example:
) in the Actions column for the schema and selecting Reload Schema. For example: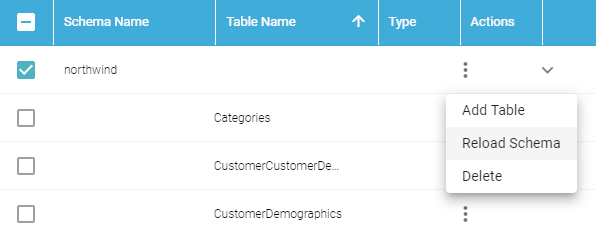
Repeat this step as needed to reload additional schemas.
- Click the Ingest button. If the source has more than one schema, Anzo displays the select schema dialog box. In the drop-down list, select the schema to use, and then click OK. For example:
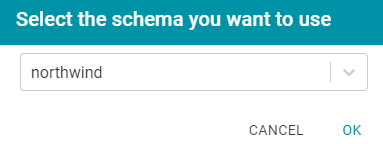
Anzo opens the Ingest dialog box. The options are populated with the values from the previous workflow configuration. For example:

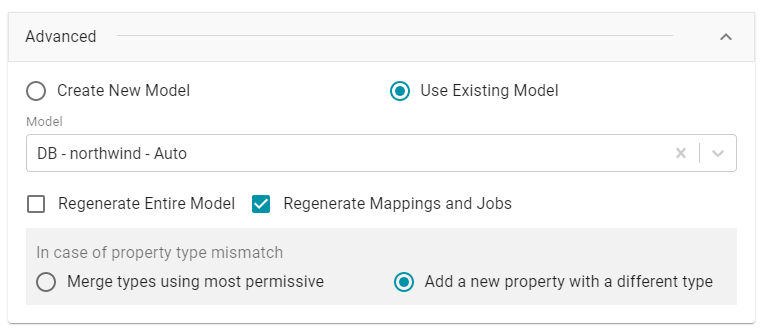
- Click Advanced to view additional configuration options. By default, the Ingest workflow is configured to use the existing model, and additional options are presented for controlling the regeneration of artifacts and the handling of property type mismatches. For example:
This list below describes the advanced options:
- Regenerate Entire Model: Selecting this option means that Anzo deletes all entities from the existing model and recreates them. The model that results from the current ingestion process will contain only the data from the current process. For example, if a previous run generated a model that contains classes A, B, and C, and the current data contains Classes C, D, and E, selecting Regenerate Entire Model results in a model that contains only classes C, D, and E. If Regenerate Entire Model is NOT selected, the resulting model will contain classes A, B, C, D, and E.
- Regenerate Mappings and Jobs: Selecting this option means that Anzo deletes all entities from the existing mappings and jobs and recreates them. The artifacts that result from the current ingestion process will contain only the data from the current process. For example, if a previous run generated mappings and jobs that contain tables A and B and the current run is ingesting tables C and D, selecting Regenerate Mappings and Jobs results in artifacts that contain only tables C and D. If Regenerate Mappings and Jobs is NOT selected, the resulting artifacts contain tables A, B, C, and D.
- Merge types using most permissive: Anzo looks at the inferred types in both schemas and chooses the type that covers all inputs. In most cases Anzo sets the type to String.
- Add a new property with a different type: If Anzo encounters a type mismatch, it adds a new property with the new type to the existing model.
When associating column names in the new schema with the existing model, the match is case-insensitive. Anzo matches the names based on the spelling. For example, "myInt" matches "MYint."
- Click Save. Anzo updates the pipeline and regenerates or updates the model and mappings according to the options you specified.
- In the main navigation menu under Onboard, click Structured Data. Then click the Pipelines tab.
- Click the name of the pipeline to run. Anzo displays the pipeline overview screen. For example:

- If you would like to see the jobs that Anzo created for this data source, click the Jobs tab. The jobs are listed on the left side of the screen. A job exists for each of the tables that were imported. If this pipeline has not been published previously, the right side of the screen remains blank. After the jobs are run, selecting a job from the list displays its history on the right. For example, the image below shows a new pipeline that has not been published:

This image shows an example of a pipeline that has been published previously and has job history:

- To run all of the jobs, click the Publish All button at the top of the screen. To publish a subset of the jobs, select the checkbox next to each job that you want to run and then click the Publish button above the list of jobs. Anzo runs the pipeline and generates the resulting file-based linked data set in a new subdirectory under the specified Anzo data store.
When the pipeline finishes, this run of the pipeline becomes the Default Edition. The Default Edition always contains the latest successfully published data for all of the jobs in the pipeline. If one or more of the jobs failed, those jobs are excluded from the Default Edition. If you publish the failed jobs at a later date or you create and publish additional jobs in the pipeline, the data from those jobs is also added to the Default Edition. For more information about editions, see Managing Pipeline Editions.
The new data set also becomes available in the Dataset catalog. From the catalog, you can generate graph data profiles and create graphmarts. See Blending Data for next steps.