Configuring a Templated Step
Templated steps enable users to create reusable templates for creating additional query steps in different Data Layers or Graphmarts. In templated queries, key-value pairs are represented by parameters in a query. When reusing the step, users do not need to rewrite the query to target a different Data Source. Instead, they modify the values for the keys.
This type of query template step uses key-value pairs that are user-defined. Creating the key-value pairs requires familiarity with the data and properties defined in the model. To create a query template that enables you to run a query and automatically generate the key-value pairs, see Configuring a Query-Driven Templated Step.
The sections below describe each of the tabs and configuration options that are available when you create or edit a Templated Step.
Details
The Details tab includes options such as the name of the Step, the source data to act upon, and the Data Model to create the template against.
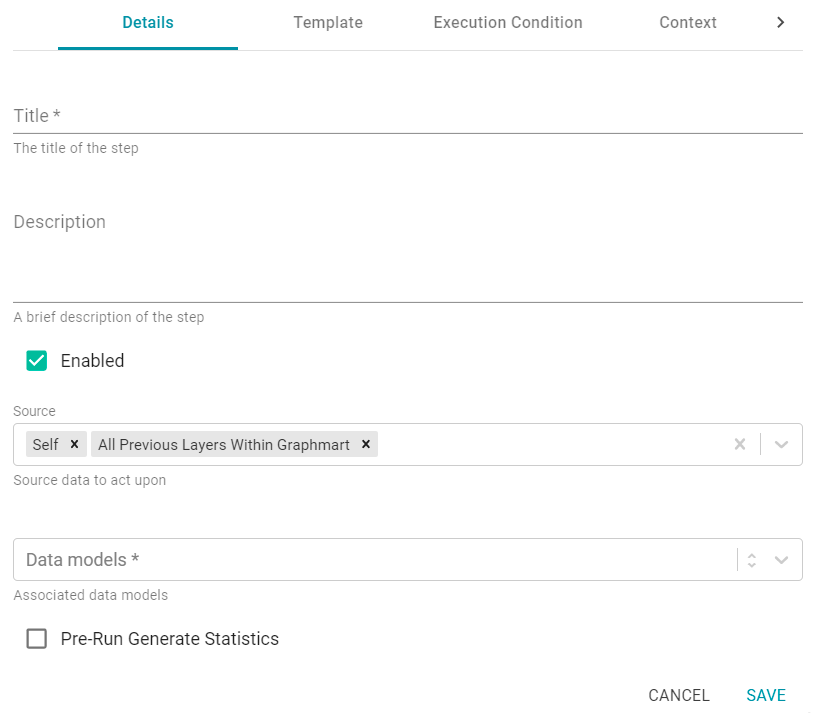
Title
The required name of the Step.
Description
And optional description of the Step.
Enabled
When creating a new Step, the Enabled option is selected by default, indicating that the Step is enabled and will run when the Data Layer is loaded or refreshed. If you want to disable the Step so that it is not processed, clear the Enabled checkbox.
Source
The Source is the source data that this Step should act upon. Steps can build upon the data generated by Steps in other Data Layers or can be self-contained, applying changes that relate only to the data defined in the Layer that contains this Step. You can select any number of the following options:
- Self: This option is selected by default and means that the Query runs against only the data that is generated in the Layer this Step belongs to.
- All Previous Layers Within Graphmart: This option means that the Query runs against the data that is generated by all of the successful Layers in the Graphmart that precede the Layer this step is in. Any failed Layers are ignored.
- Previous Layer Within Graphmart: This option means that the Query runs against only the data that is generated by the one Layer that precedes the Layer this Step is in.
- Layer Name: The Source drop-down list also includes options for specific Layer names. You can choose a specific Layer to run the Query against that Layer only.
Data Models
This required field specifies the Data Model or Models that you want to create this query template against. The list displays all of the Models for all of the Datasets in the Dataset catalog. By default, the field is set to Exclude System Data ( ). If you want to choose a system Model, click the toggle button on the right side of the field to change it to Include System Data (
). If you want to choose a system Model, click the toggle button on the right side of the field to change it to Include System Data (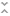 ). The Data Models drop-down list will display the system Models in addition to the Dataset Models.
). The Data Models drop-down list will display the system Models in addition to the Dataset Models.
Pre-Run Generate Statistics
This option controls whether to initiate AnzoGraph's internal statistics gathering queries before running this Step. The statistics gathering helps ensure that the AnzoGraph query planner generates ideal query execution plans for queries that are run against the Graphmart.
Template
The Template tab defines the template query and the key-value pairs.
Query
The left side of the screen includes the query template that this Step will run. The template includes the syntax for writing SPARQL INSERT and DELETE queries and includes source and target graph parameters that Anzo replaces at runtime. Edit the template text as needed. In the query, include the parameters in the format ${key_name} that you intend to replace at runtime with the value that you define for the key. For example, the following INSERT query includes several parameters that represent properties and functions:
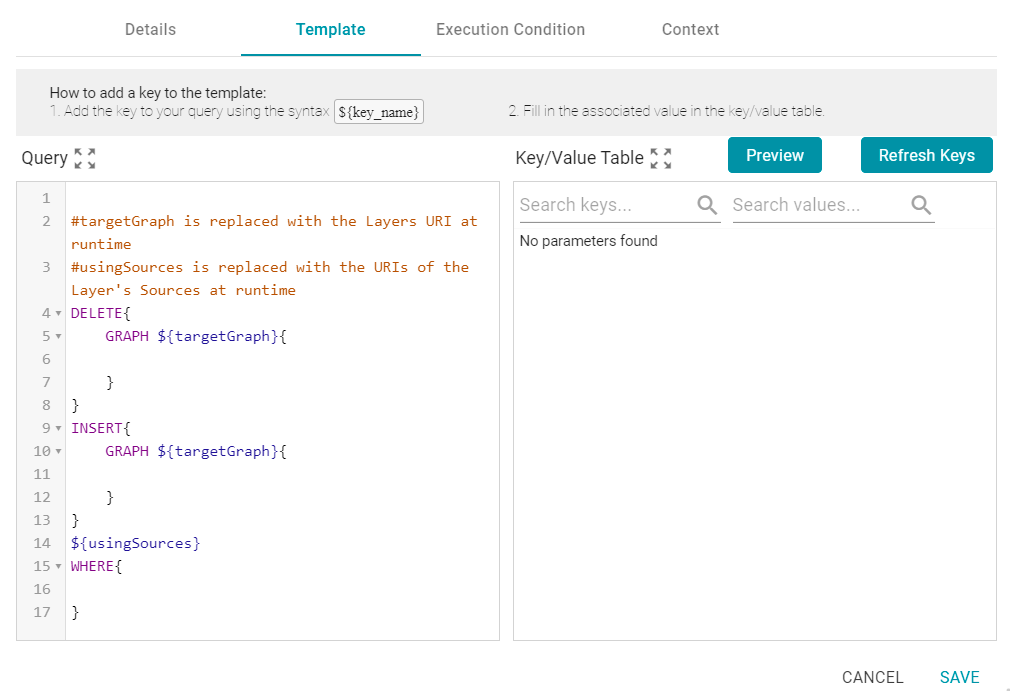
INSERT {
GRAPH ${targetGraph}{
?lsubj ${linkProperty} ?rsubj
}
}
${usingSources}
WHERE {
?lsubj <${sourceProperty}> ?lobj .
?rsubj <${targetProperty}> ?robj .
FILTER (${lFunction}(?lobj) ${operator} ${rFunction}(?robj))
}
See SPARQL Query Templates and Best Practices for guidance on writing SPARQL queries.
Key/Value Table
Once the template query has been defined, populate the Key/Value Table with the keys from the query and the values that should replace the parameters that are specified in the query. Clicking the Refresh Keys button adds each key in the template to the table. For example, using the example query above, the Key/Value table is populated with the following keys:
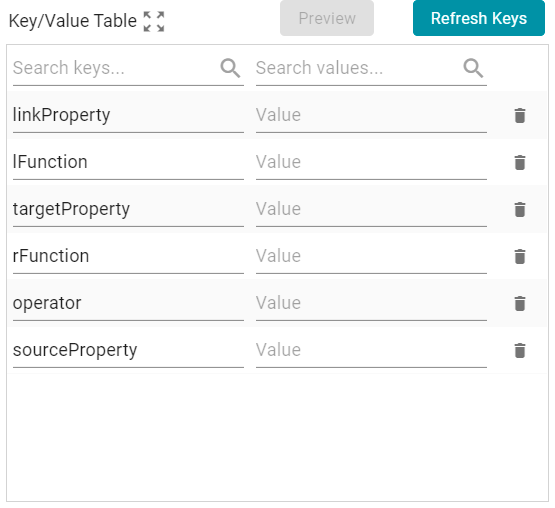
In each row, specify the desired Value for the key. For example, in the image below, the property URI http://cambridgesemantics.com/ont/autogen/c89d/Tickets#tickit_events_eventid is specified as the Value for the linkProperty key.

Execution Condition
If you want this Step to be executed conditionally, based on the result of a specified Validation Condition, you can configure an Execution Condition on the Execution Condition tab that is available when creating or editing a Step. The image below shows the Execution Condition tab.
In order to set up an Execution Condition, the Graphmart needs to have at least one Validation Step that defines a Condition Variable. Condition Variables can be used across all Data Layers in the Graphmart. For guidance on configuring a Validation Step, see Configuring a Validation Step.

Enable Layer Based on Boolean Condition
This setting indicates whether to enable this Step only if the returned value from the Validation Condition is either true or false. You specify true or false in the Conditional Variable If Result field. If the Validation Condition fails, the Step is disabled.
Conditional Variable
This field specifies the variable that you want to base this Execution Condition on. The variable is the result of a Validation Step Query in the Graphmart.
Conditional Variable If Result
If you enabled the Enable Layer Based on Boolean Condition setting, select true or false from the drop-down list. The Step will be enabled only if the result of the Validation Step Query matches the value that you specified. If Enable Layer Based on Boolean Condition is disabled, leave this field blank.
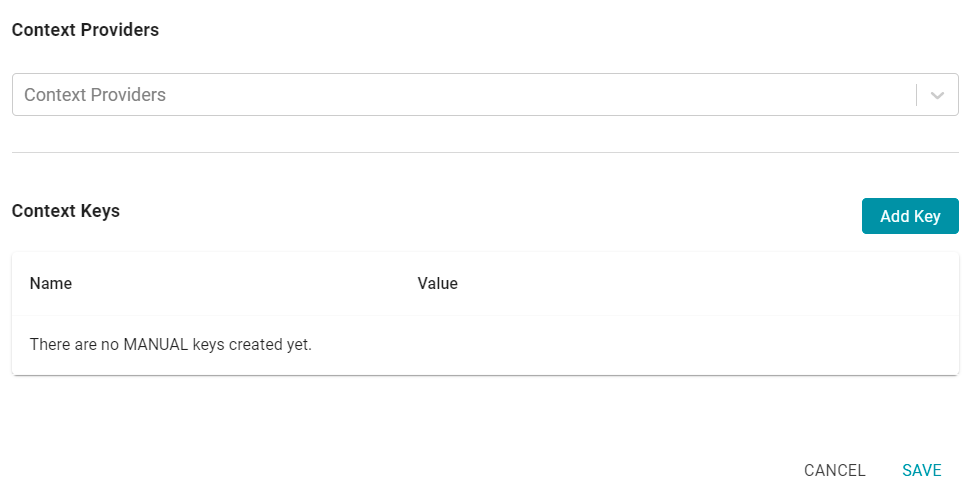
Context
When you use the Graph Data Interface (GDI) for Data Virtualization, you may connect to Data Sources that require input of sensitive connection and authorization information such as keys, tokens, and user credentials. The Context tab gives you the option to configure a Context to store the sensitive information as key-value pairs. Queries can then reference the keys from the Context so that the sensitive details are abstracted from any requests that are sent to the Data Source.
Context Providers
Connections in Anzo implement the Context Provider interface. For example, File Store connections, Anzo Data Store connections, and Data Source connections provide contexts (in the form of JSON objects) that contain key-value pairs which define connection details such as URLs, database names, usernames and passwords, tokens, etc. These contexts are passed to the Data Source when a request is made against that source. To use one of the Anzo-generated Context Providers that was created for a pre-existing connection, select that provider from the drop-down list.
If you specify a Context Provider, the key-value pairs from the selected provider are not populated in the Context Key list on the screen. However, the keys are used automatically when a query is run against that provider.
Context Keys
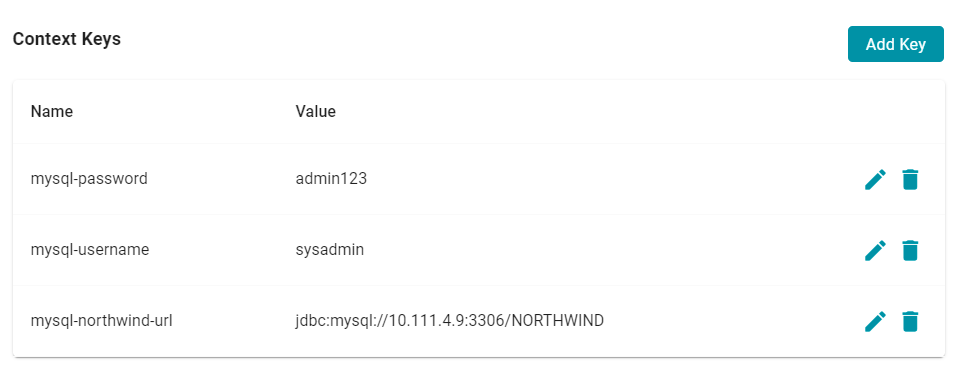
Context Keys are user-defined key-value pairs that are not associated with a particular Context Provider. To add a key and define its value, click the Add Key button. Then specify the Key Name and Key Value in the Create Context Key dialog box. Click Create to add the key-value pair to the Context.

The image below, for example, creates URL, username, and password Context Keys.
The format that you use for referencing a Context Key in a query depends on the type of AnzoGraph plugin or extension that is being called by the query. Generally, Contexts are only used in Steps that contain Graph Data Interface (GDI) queries. When referencing Context Keys in GDI queries, use the following format:
{{@<context_key_name>}}