Anzo Concepts and Vocabulary
This topic introduces you to key features, concepts, and vocabulary to know when working with Anzo. The diagram below shows a high-level overview of Anzo components and concepts. Details about the components in the image are described below, followed by a glossary that defines common Anzo terms and phrases.
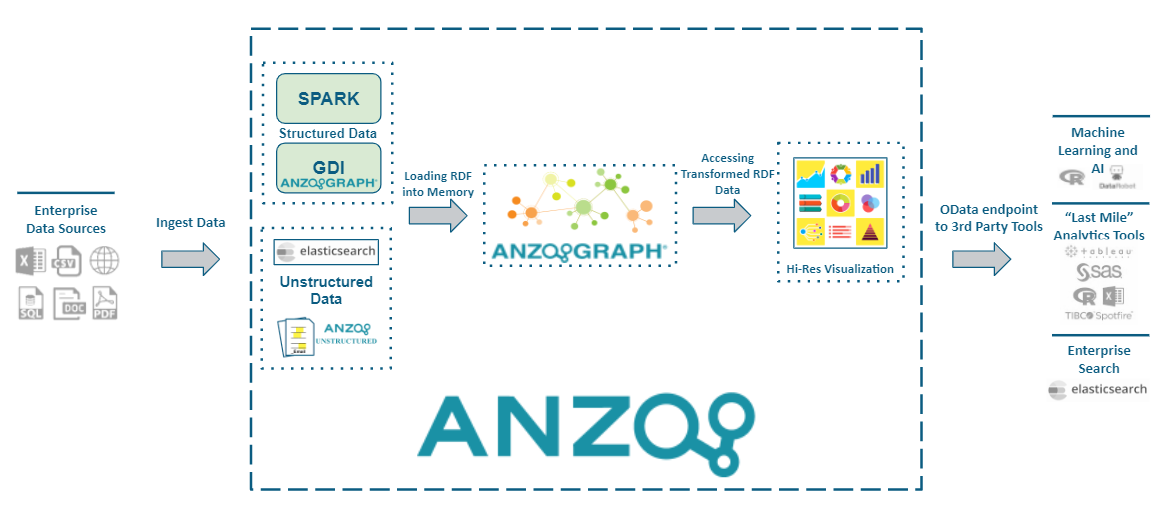
| Component | Description |
|---|---|
| Enterprise Data Sources | Anzo supports ingesting data from structured, semi-structured, and unstructured data sources. Anzo connects to relational database sources via ODBC and JDBC drivers and supports loading data from CSV, JSON, XML, SAS, and Parquet files. Unstructured data sources such as documents, PDFs, text snippets, web pages, and content from knowledgebases are also supported. |
| Ingest Data | Structured and semi-structured data sources like relational databases and flat files can be directly loaded using AnzoGraph's Graph Data Interface (GDI) or Anzo’s built-in ETL pipelines. Unstructured data sources are onboarded using configurable unstructured pipelines. These pipelines onboard unstructured source files, integrate metadata about those files, and make the full text in those files as well as key facts available as part of graph data models. |
| Loading RDF into Memory | Whether data is ingested with the GDI, ETL pipelines, or unstructured pipelines, it is converted from its original format to a new format that describes the data as a graph model. This format, Resource Description Framework (RDF), simplifies access to complex data and flexibly accommodates new data sources and use cases. The RDF data is added to Graphmarts and loaded to AnzoGraph, Anzo’s in-memory massively parallel processing (MPP) graph OLAP engine, for further transformation and analytics. |
| Accessing Transformed RDF Data | Users have several options for accessing and analyzing graph data. Anzo’s Hi-Res Analytics application enables users to create dashboards for exploring and visualizing the data without needing to have specialized query knowledge. And, in line with Anzo's open standard architecture, Graphmarts can be accessed using modern application program interfaces (APIs) as well as SPARQL-compliant query endpoints. Anzo also offers standards-compliant Open Data Protocol (OData)-based REST endpoints as part of its Data on Demand service. The Data on Demand service provides access to data from business intelligence tools. |
Glossary
The table below defines commonly used Anzo terms and phrases.
| Phrase | Description |
|---|---|
| Anzo Data Store | An Anzo data store (previously known as a graph data source) defines an endpoint for writing data. It specifies the directory on the file store where Anzo can generate file-based linked data sets (see File-Based Linked Data Set). It also defines write properties such as the maximum file size and whether files should be compressed. |
| AnzoGraph | AnzoGraph is Anzo’s in-memory massively parallel processing (MPP) graph OLAP engine. |
| Data Layers | Data layers enable users to enhance graphmarts dynamically. Users can create layers to load additional data sets, clean, conform, or transform data, infer new information, or export data to a file-based linked data set (FLDS). |
| Dataset Catalog | Anzo’s Dataset catalog combines traditional technical, operational, and business metadata with a semantic layer to describe all aspects of enterprise data elements. The catalog enables Anzo’s unique use of semantics and graph models and is the system of record for data in Anzo. Anzo collects and generates metadata at every stage in the data discovery and integration process. Metadata in the catalog documents how data is converted during the onboarding process from its original format into a graph model. Subsequent data blending, transformation, and preparation steps are captured as additional metadata. Anzo also captures new metadata to describe all actions taken against data withinAnzo. Anzo uses the metadata to enable users to visualize their data, understand business contexts, identify connections, and blend and prepare data. |
| ELT | In addition to traditional ETL, Anzo’s data layers capability enables users to transform, blend, and prepare any data that has been added to the catalog into analytics-ready data sets using an extract, load, transform (ELT) flow. Data layers are Anzo's mechanism for flexibly transforming data in memory. |
| ETL | The extract, transform, and load (ETL) process takes source data and converts it to the graph data model using a source to target mapping. Anzo’s mapping tool enables users to define field-level transformations, including type casting, date conversions, unit conversions, etc., as data is onboarded to Anzo. |
| File-Based Linked Data Set | When the onboarding process is complete, Anzo creates a data set in the Dataset catalog. The data set in the catalog is registered in the Anzo system data source (see Journal or Volume) and includes metadata about the data, including a pointer to the data store location for the RDF files generated by the ETL pipeline. The catalog data set and the files on disk are known as a file-based linked data set (FLDS). |
| File Store | The Anzo platform components, AnzoGraph, Spark, Elasticsearch, etc., share a file system for maintaining onboarded data and supporting files. A file store is the shared file storage system, such as NFS, HDFS, or cloud storage, that is shared between the servers. |
| Graph Data Interface | AnzoGraph's Graph Data Interface (GDI) is an extension that enables users to query data from external endpoints that are accessible over JDBC or HTTP. Information from the external sources can augment data in the Dataset catalog without having to onboard the data to Anzo. |
| Graphmart | Graphmarts are collections of datasets that users can blend and enhance. Graphmarts can combine any subset of data in Anzo for analysis. |
| IRI | An Internationalized Resource Identifier (IRI) is similar to URI but allows a greater range of characters. URI and IRI are often used interchangeably. |
| Journal or Volume | A journal, also known as a volume, refers to data that is stored in Anzo's embedded graph store. The graph store is transactional and is used to persist metadata, which is written to disk in a .jnl file. The system volume (or system data source) is the default, required volume where Anzo stores ontologies as well as system configuration, data set, catalog, registry, and access control metadata. Users can create secondary local volumes that are used for more compartmentalized data and can be created and deleted without affecting the core system. |
| Linked Data Set | A linked data set (LDS) is a fundamental concept. Anzo organizes all data, including system data, into linked data sets. An LDS is associated with a data model and can be searched, discovered, shared, and protected with access control. For example, graphmarts are organized in a linked data set or registry of graphmarts, pipelines are organized in a linked data set, the Activity Log is a linked data set, data source configurations exist in a linked data set, and so on. |
| Model | Anzo establishes the semantic layer by enabling users to convert diverse enterprise data models into graph data models and then enhance the data by adding new business definitions, names, and tags. Further insight is added when data from separate graph data maps are linked, connecting shared business definitions across previously siloed sources. Anzo employs open World Wide Web Consortium (W3C) standards, including Web Ontology Language (OWL), RDF, and SPARQL to model, connect, and query interconnected graphs. |
| NLP | Anzo performs named-entity recognition (NER) using knowledge bases and can interface with natural language processing (NLP) tools. It serves as a platform that enables text analytics through interplay between best-of-breed NLP tools. |
| OData | Open Data Protocol (OData) facilitates the creation of interoperable RESTful APIs. The Anzo Data on Demand service provides OData-based feeds that can be used to query Graphmart data from third-party business intelligence tools. |
| OSGi | The Open Service Gateway Initiative (OSGi) is the open-standard architecture upon which Anzo is built. It is a Java framework for developing and deploying software programs and libraries. OSGi enables Cambridge Semantics to compartmentalize Anzo into "bundles" that can be deployed, activated, and removed independently without affecting other bundles in the system. |
| Registry | Anzo manages configurations in system-level registries. Each registry is a collection of application and system component configurations of the same type. Like data, registries are stored and managed with RDF named graphs according to ontologies. Technically, a registry is a Linked Data Set. |
| URI | A Uniform Resource Identifier (URI) is a globally unique identifier for a piece of information. A URL (Uniform Resource Locator) is a URI that specifies a location, such as a web address. |