Incremental Onboarding with the GDI
When loading data from a database or file-based data source with a Graph Data Interface (GDI) query, you can add a few statements to the query to load a portion of the data incrementally rather than all of the data at once. As data is added or changed in the source, new data can be ingested without having to reload all of the previously ingested data. Because incremental ingestion is configured as a filter in a SPARQL query, it is extremely flexible, allowing for various conditions to be defined for diverse data sources. When the data is ingested, the GDI evaluates the current state of the data and then loads only the data that meets the conditions defined in the query.
This topic provides example incremental queries to get you started and includes instructions for configuring a Data Layer as an incremental ingestion workflow.
- Incremental DbSource Example
- Incremental FileSource Example
- Setting Up a Data Layer to Ingest Data Incrementally
Incremental DbSource Example
The following query from a Direct Load Step ingests data from a database. All of the values for the requested columns in the ORDER_DETAILS table will be loaded.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX s: <http://cambridgesemantics.com/ontologies/DataToolkit#>
INSERT {
GRAPH ${targetGraph} {
?s ?p ?o .
}
}
${usingSources}
WHERE {
SERVICE <http://cambridgesemantics.com/services/DataToolkit> {
?data a s:DbSource ;
s:url "jdbc:oracle:thin:@10.10.10.10:1111/XE" ;
s:username "northwind" ;
s:password "NORTHWIND123" ;
s:schema "NORTHWIND" ;
s:table "ORDER_DETAILS" ;
?database ("!") ;
?schema ("!") ;
?table ("!") ;
?OrderID (xsd:int) ;
?ProductID (xsd:int) ;
?UnitPrice (xsd:double) ;
?Quantity (xsd:short) ;
?Discount xsd:double .
BIND(IRI("http://cambridgesemantics.com/orders/{{?OrderID}}") AS ?resource)
?rdf a s:RdfGenerator, s:OntologyGenerator ;
s:as (?s ?p ?o) ;
s:ontology <http://cambridgesemantics.com/ontologies/northwind> ;
s:base <http://cambridgesemantics.com/data> .
}
}
The query below adds statements that configure the same Direct Load Step to ingest data incrementally. It captures the maximum order ID as the incremental value. When the source is updated with records that increase the order ID, only the records with larger order IDs than the previous maximum value will be ingested when the Graphmart is refreshed or reloaded. In the query:
- A ?MaxID variable is bound to the result of MAX(?OrderID):
BIND (MAX(?OrderID) AS ?MaxID). - The ?MaxID variable is defined as the incremental value:
?MaxID a s:IncrementalValue. - A filter clause is added to create a condition that ingests only the records where the order ID is greater than the previously ingested maximum ID:
FILTER (?OrderID > ?MaxID).
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX s: <http://cambridgesemantics.com/ontologies/DataToolkit#>
INSERT {
GRAPH ${targetGraph} {
?s ?p ?o .
}
}
${usingSources}
WHERE {
SERVICE <http://cambridgesemantics.com/services/DataToolkit> {
?MaxID a s:IncrementalValue .
FILTER (?OrderID > ?MaxID)
BIND (MAX(?OrderID) AS ?MaxID)
?data a s:DbSource ;
s:url "jdbc:oracle:thin:@10.10.10.10:1111/XE" ;
s:username "northwind" ;
s:password "NORTHWIND123" ;
s:schema "NORTHWIND" ;
s:table "ORDER_DETAILS" ;
?database ("!") ;
?schema ("!") ;
?table ("!") ;
?OrderID (xsd:int) ;
?ProductID (xsd:int) ;
?UnitPrice (xsd:double) ;
?Quantity (xsd:short) ;
?Discount xsd:double .
BIND(IRI("http://cambridgesemantics.com/orders/{{?OrderID}}") AS ?resource)
?rdf a s:RdfGenerator, s:OntologyGenerator ;
s:as (?s ?p ?o) ;
s:ontology <http://cambridgesemantics.com/ontologies/northwind> ;
s:base <http://cambridgesemantics.com/data> .
}
}
Incremental FileSource Example
The following query from a Direct Load Step ingests data from all of the CSV files in the /nfs/data/fmcsa directory:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX s: <http://cambridgesemantics.com/ontologies/DataToolkit#>
DELETE {
GRAPH ${targetGraph} {
}
}
INSERT {
GRAPH ${targetGraph} {
?s ?p ?o .
}
}
WHERE {
SERVICE <http://cambridgesemantics.com/services/DataToolkit> {
?data a s:FileSource ;
s:model "fmcsa" ;
s:url "/nfs/data/fmcsa" ;
s:pattern "*.csv" .
?rdf a s:RdfGenerator , s:OntologyGenerator ;
s:as (?s ?p ?o) ;
s:ontology <http://cambridgesemantics.com/ontologies/fmcsa> ;
s:base <http://cambridgesemantics.com/data/> .
}
}
The query below adds statements that configure the same Direct Load Step to ingest data incrementally. It uses a "last modified" strategy to determine what files are new or modified and should be ingested the next time the Graphmart is refreshed or reloaded. In the query:
- The modified timestamp metadata on the files is captured with
?Modified ("!"). - The ?LastRun variable is bound to the result of the NOW() function:
BIND (NOW() AS ?LastRun). - A filter clause is added to check whether the modified timestamp is later than the timestamp from the last time the query was run:
FILTER (?Modified > ?LastRun). - ?LastRun is defined as the incremental value:
?LastRun a s:IncrementalValue.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX s: <http://cambridgesemantics.com/ontologies/DataToolkit#>
DELETE {
GRAPH ${targetGraph} {
}
}
INSERT {
GRAPH ${targetGraph} {
?s ?p ?o .
}
}
WHERE {
SERVICE <http://cambridgesemantics.com/services/DataToolkit> {
?LastRun a s:IncrementalValue .
FILTER (?Modified > ?LastRun)
BIND (NOW() AS ?LastRun)
?data a s:FileSource ;
s:model "fmcsa" ;
s:url "/nfs/data/fmcsa" ;
s:pattern "*.csv" ;
?Modified ("!") .
?rdf a s:RdfGenerator , s:OntologyGenerator ;
s:as (?s ?p ?o) ;
s:ontology <http://cambridgesemantics.com/ontologies/fmcsa> ;
s:base <http://cambridgesemantics.com/data/> .
}
}
Setting Up a Data Layer to Ingest Data Incrementally
- Create a new empty dataset in the Anzo Data Store. For instructions, see Adding an Empty Dataset for an Export Step.
- In the Graphmart where you want to add a GDI query that ingests data incrementally, add a new Data Layer.
- In the new layer, add a Load Dataset Step as the first step. The Linked Dataset for this step should be the empty dataset that you created in the first step.
- Now, add a Direct Load Step as the next step in the layer. Edit the query template in the step to compose the incremental query.
- As the last step in the layer, add an Export Step. The Target FLDS for the step should also be the empty dataset that you created in the first step. For example, the image below shows a Graphmart with a layer that is set up to ingest data incrementally.
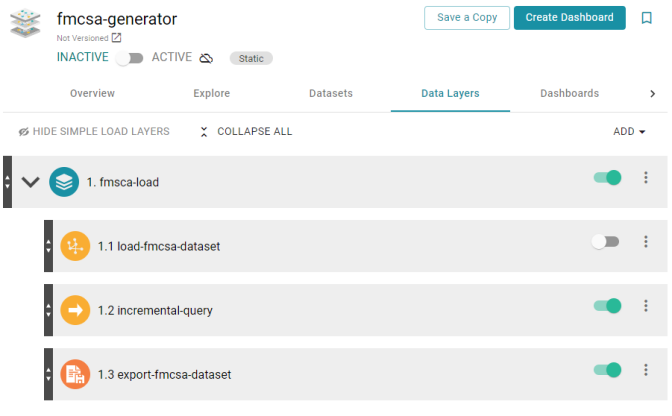
- Activate the Graphmart to ingest the data and export it to an FLDS. Once the Graphmart is activated, enable the Load Dataset Step.