Creating an Anzo Data Store
This topic provides instructions for creating an Anzo Data Store. Creating a data store means that you designate a directory on a shared file store where file-based linked data sets and other files can be created and shared. If you run Spark or unstructured Pipelines, a data store is required. In addition, a data store is required if you use the Direct Data Load automated workflow for structured data and configure the workflow to automatically export the data to a dataset. You can create one data store and configure all pipelines and workflows to write to that store or you can create multiple data stores to use for different datasets.
- In the Administration application, expand the Connections menu and click Anzo Data Store. Anzo displays the Anzo Data Store screen, which lists any existing data stores. For example:

The Server Anzo Data Store is a default data store that points to the local Anzo file system. This store exists so that first-time users can quickly test the onboarding process. It is not meant to be used in production. Do not change the Data Location to a shared file store; reconfiguring this Data Store can cause unexpected consequences when upgrading or migrating the system. It is safe to delete this store so that it is not presented as an option when users configure ingestion pipelines.
- On the Anzo Data Store screen, click the Add Anzo Data Store button and select Add Anzo Data Store. Anzo opens the Create Anzo Data Store screen.

- Type a Title and optional Description for the data store.
- Click in the Data Location field. Anzo opens the File Location dialog box.
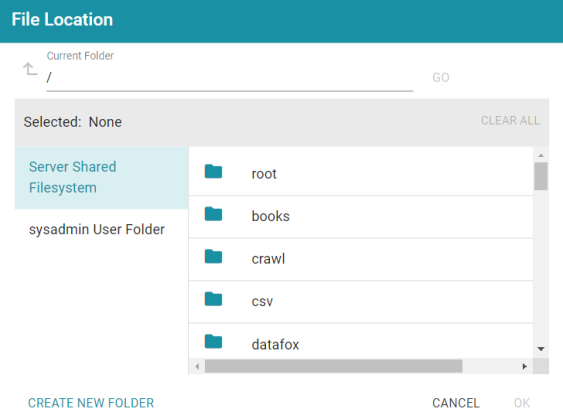
- On the left side of the screen, select the File Store on which to create this data store. On the right side of the screen, navigate to the directory that you want to designate as the data location. Select a directory, and then click OK. Or click Create New Folder to create a new directory. Each time a pipeline is run for this data store, a new subdirectory is created under the specified data location.
The Data Location needs to be a directory on the file store that is shared between Anzo, AnzoGraph, and any Anzo Unstructured, Elasticsearch, or Spark servers. If you want Anzo to generate files for this data store in one location and then load the files into AnzoGraph from another location, specify the file generation location in this field, and then specify the AnzoGraph load location in the Alternate Data Location field that is displayed on the Details screen after you save the data store.
- If necessary, you can modify the maximum limit for the size of the files that are created by pipelines that write to this data store by specifying the size (in bytes) in the Max File Size Before Compression (Bytes) field. The value applies to files before they are compressed. The Spark ETL engine partitions files on output, and the default maximum file size is 100 MB (uncompressed). The Sparkler ETL engine partitions files on input, and the default maximum file size is 128 MB (uncompressed). Since Sparkler files are partitioned on input, the resulting output FLDS files can be significantly larger than 128 MB since the source is converted to Turtle (TTL) format after it is partitioned.
Cambridge Semantics recommends that you do not set this value unless instructed to do so by Cambridge Semantics Support.
- Specify whether to compress the generated load files. By default, the Compress output checkbox is selected, indicating that Anzo generates .ttl.gz files when writing to this graph data source. If you clear the checkbox, Anzo generates uncompressed .ttl files. To preserve disk space and reduce read times when loading data into memory, Cambridge Semantics recommends that you accept the default configuration and compress load files.
- The ETL engine does not remove duplicates by default when running structured pipelines. If the source contains a significant number of duplicate entities, you have two options for deduplicating the data:
- Deduplicate the data during the ETL process: To deduplicate the data while running the jobs that will generate this graph source, select the Dedupe output per executor option. Enabling the dedupe option limits the number of duplicates to one duplicate per executor node. For example, if the Spark configuration has 10 executor nodes, the resulting data set can contain a maximum of 10 duplicate entities.
Deduplication is based on primary keys and URI templates. If the source does not employ templating, do not enable the dedupe option. In addition, enabling this option substantially increases the time it takes to run the jobs for this data store.
- Deduplicate the data after loading it to AnzoGraph: AnzoGraph deduplicates data during a "vacuum" process that runs automatically after data is loaded into memory. If you leave the Dedupe output per executor option disabled, duplicates will be removed by AnzoGraph.
- Deduplicate the data during the ETL process: To deduplicate the data while running the jobs that will generate this graph source, select the Dedupe output per executor option. Enabling the dedupe option limits the number of duplicates to one duplicate per executor node. For example, if the Spark configuration has 10 executor nodes, the resulting data set can contain a maximum of 10 duplicate entities.
- Click Save to create the data store. Anzo saves the configuration and displays the details view. For example:
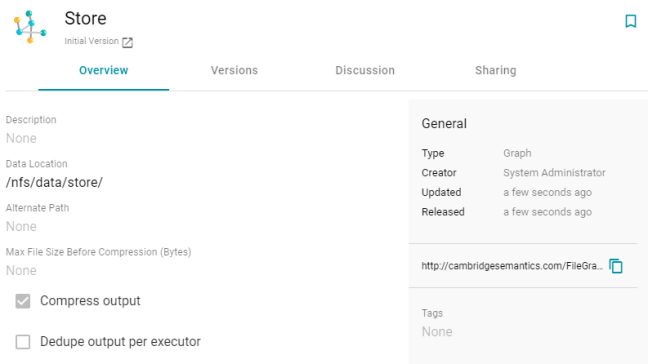
You can click the Edit icon (
 ) to modify any of the options. Click the check mark icon (
) to modify any of the options. Click the check mark icon ( ) to save changes to an option, or click the X icon (
) to save changes to an option, or click the X icon ( ) to clear the value for an option.
) to clear the value for an option. - If you plan to load files into AnzoGraph from a location that is different than the Data Location that you specified, edit the Alternate Data Location field and select the location for AnzoGraph load files.
Once you have create the new data store, you can designate it as the default store so that it is automatically selected when users set up data onboarding workflows. See Configure the Default Anzo Data Store for instructions.