Adding a Parquet Data Source
Follow the instructions below to create a Parquet data source. You can onboard one file or multiple files with the identical format (schema) per source.
If your Parquet Data Source is consistently updated with new or changed files, you can configure the Data Source to process the data incrementally. For details, see Configuring a CSV or Parquet Data Source for Incremental Processing.
- In the Anzo application, expand the Onboard menu and click Structured Data. Anzo displays the Data Sources screen, which lists any existing sources. For example:
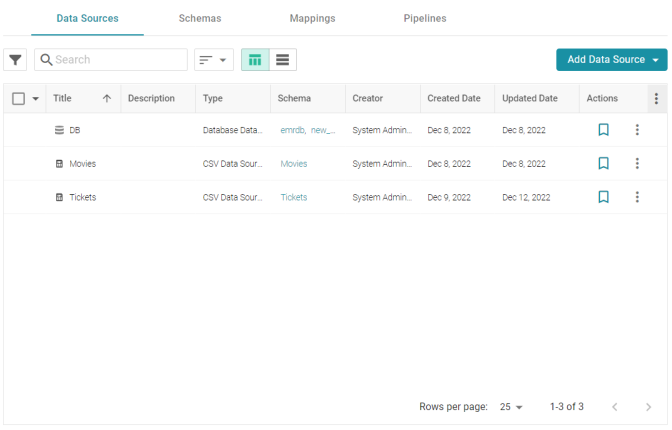
- Click the Add Data Source button and select File Data Source > Parquet Data Source. Anzo opens the Create Parquet Data Source screen.
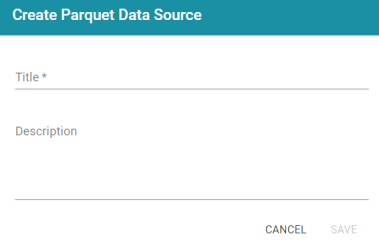
- Specify a name for the source in the Title field, and type an optional description in the Description field. Then click Save. Anzo saves the source and displays the Overview tab. For example:
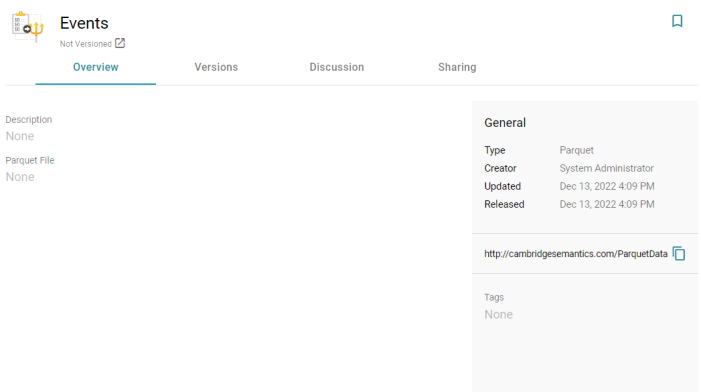
- On the Overview tab, click in the Parquet File field to make the value editable. Then click Browse to open the File Location dialog box and select the file to import.
- In the File Location dialog box on the left side of the screen, select the file store for the Parquet file. On the right side of the screen, navigate to the directory that contains the file to import. The screen displays the list of files in the directory. For example:

- Select the file that you want to import. If you have multiple files with the identical format you can select the Insert Wildcard option. Then type a string using asterisks as wildcard characters to find the files with similar names. Files that match the specified string will be imported as one file and will result in one job being created in the pipeline to ingest all of the files that are selected by the specified string. You can specify up to 16,000 files using a wildcard. After typing a string, click Apply to include that string in the Selected list.
The image below shows a directory with multiple Parquet files. The events.parquet and events-2.parquet file have the identical format and can be imported as one file. The Insert Wildcard option is selected, and event*.parquet is specified to identify the two files.
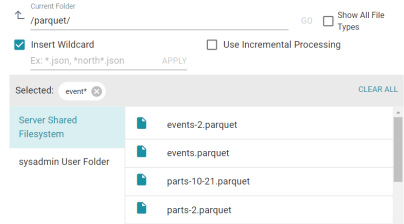
- After selecting the file, click OK to close the File Location dialog box. Then click the checkmark icon (
 ) to save the change. The Create Graphmart, Profile Data, and Ingest buttons become available.
) to save the change. The Create Graphmart, Profile Data, and Ingest buttons become available.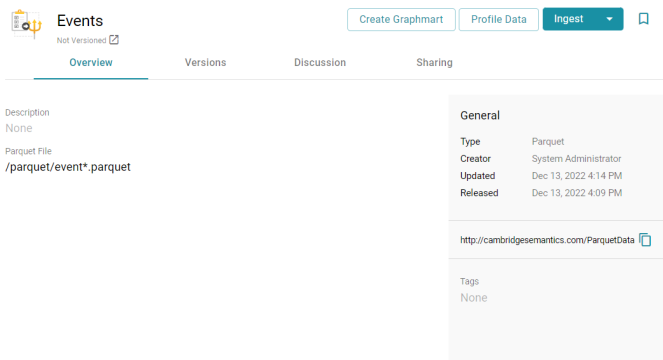
The source data can now be onboarded to Anzo. If you use the Spark ETL pipeline workflow, see Ingesting Data Sources via ETL Pipelines. If you do not use Spark, see Directly Loading Data Sources via Graphmarts for next steps.