Configuring a CSV or Parquet Data Source for Incremental Processing
If you have a CSV or Parquet data source that is consistently updated with new or changed files, you can configure the source to process the data incrementally. When a source is set up to onboard data incrementally and new files are added to the data source directory, those new files are ingested and added to the existing dataset. This topic describes how incremental processing works, gives recommendations for organizing the source files, and provides instructions for configuring incremental processing.
- How Incremental Processing Works
- Organizing the Data Source Directory
- Configuring Incremental Processing
How Incremental Processing Works
When you configure file-based incremental processing, there are two methods to choose from:
File Name Strategy
The first method is called the File Name Strategy. When this strategy is chosen, Anzo saves the names of the files that are onboarded. Subsequent workflow runs ingest any files whose names are not saved. This method is useful when you know that new files will be added to the data source directory but the existing files will not be edited. If the contents of a previously ingested file changes but the file name does not, that file will not be reprocessed during the next run.
Last Modified Strategy
The second method is called the Last Modified Strategy. When this strategy is chosen, Anzo saves the last modified timestamps for the files that are ingested when the workflow is run. Subsequent runs ingest any files whose last modified timestamps are greater than the saved timestamps. Each time an incremental workflow run, the job-specific last modified date will be updated to the latest modified date of the files processed. This method is useful when you know that the contents of previously ingested files may change in addition to adding new files. Since the last modified date is updated when a file is changed, the changes will be processed during the next run.
Organizing the Data Source Directory
Regardless of the strategy you use to process data incrementally, it is important to consider the schema when organizing the data source files on the file store. In order to enable incremental processing, the source files to import must be specified using wildcard characters (*). That means the list of files that are targeted by the wildcard need to have the same schema.
CSV Data Sources
For CSV data sources, you have two options. You can create one subdirectory per schema and then add files multiple times, once for each schema. With this structure, you would import the files in each directory separately and could specify the wildcard like *.csv to import all of the files in a directory. You can also place all of the files into a single directory and use more detailed text when specifying wildcards. For example, when you add files you apply multiple wildcard values such as patients_*.csv and medication_*.csv.
Parquet Data Sources
For Parquet data sources, you can only choose one schema per source. You must create a separate data source for each schema type. You may want to create one directory per schema. Then each Parquet source can target one directory and specify a wildcard value such as *.parquet.
Configuring Incremental Processing
When adding or modifying a CSV or Parquet data source, you configure incremental processing when you are adding files to the source from the file store. This section provides instructions for adding files to a source and configuring incremental processing. For instructions on adding a new data source, see Adding a CSV Data Source or Adding a Parquet Data Source.
- When selecting the source files on the file store, select the Insert Wildcard checkbox. Enabling the wildcard option activates the Use Incremental Processing option.
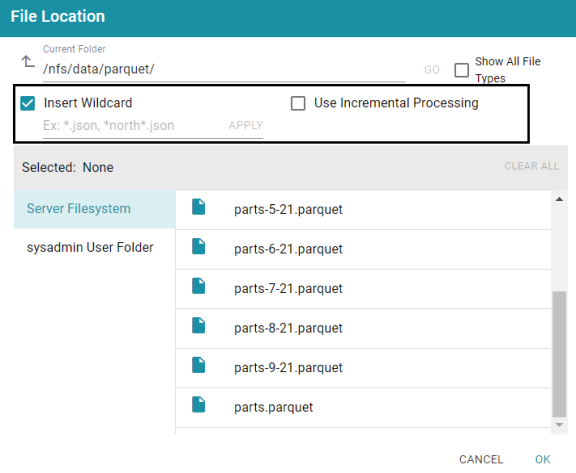
- Below the checkbox, type a string using asterisks (*) as wildcard characters to find the files to be processed. Then click Apply to apply the string. If you are configuring a CSV data source, you can apply multiple wildcard strings to target files with different schemas. The image below shows an example for a Parquet source. The string
parts*is applied to select all of the files with names that start with "parts."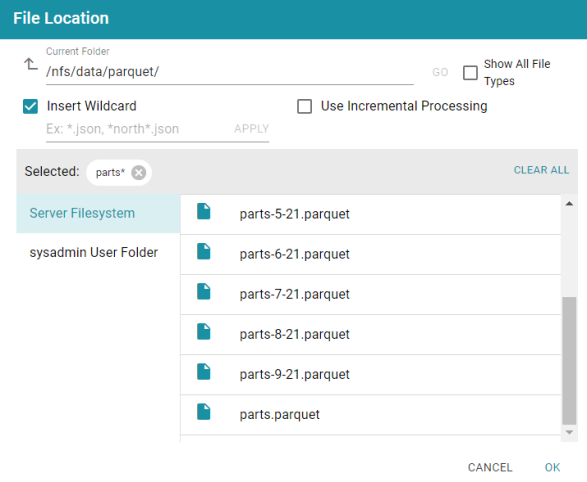
- Next, select the Use Incremental Processing checkbox. The Configure Incremental Processing dialog box is displayed:
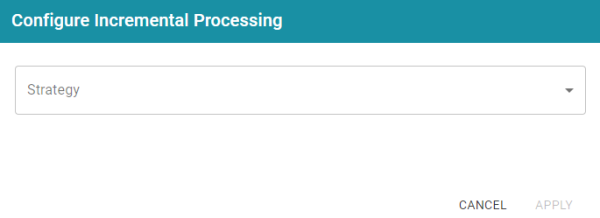
- Click the Strategy drop-down list and select the strategy to use for incremental processing. The following list describes the options. For more details about the strategies, see How Incremental Processing Works above.
- File Name Strategy: Select this option if file names should be used to target the new source data to process each time the graphmart that contains this source is reloaded or refreshed.
- Last Modified Strategy: Select this option if the last modified date should be used to target the new source data to process each time the graphmart that contains this source is reloaded or refreshed.
- If you chose File Name Strategy, click Apply and then click OK or Next to proceed. The source is now configured to process data incrementally. If you chose Last Modified Strategy, proceed to the next step.
- If you chose Last Modified Strategy, the Baseline options are displayed. The Baseline determines when the last modified date begins.
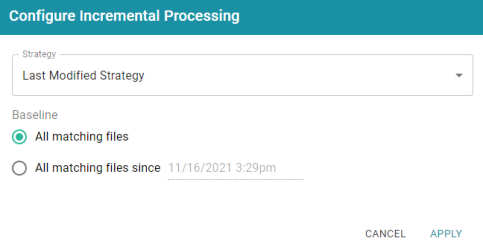
- By default All matching files is selected as the Baseline. This means all files in the directory that are matched by the wildcard string will be ingested when the graphmart is reloaded or refreshed. If you have older files that you do not want to be ingested, you can select All matching files since. Then click the timestamp field and specify the date and time to use as the Baseline.
- When you have finished configuring the Strategy, click Apply. Then click OK or Next to proceed and finish configuring the data source if necessary.
When the graphmart is created, all of the data that matches the wildcard string and meets the baseline requirements will be onboarded. When new files are added to the data source directory, reloading or refreshing the graphmart will update the data.
The source data can now be onboarded to Anzo. If you use the Spark ETL pipeline workflow, see Ingesting Data Sources via ETL Pipelines. If you do not use Spark, see Directly Loading Data Sources via Graphmarts for next steps.