Partitioning a Database Table for Parallel Ingestion
When you ingest data from a database, Anzo creates one ETL job for each table in the schema. When there are multiple jobs in a pipeline, Spark processes the jobs in parallel, one job per executor. If the source has a very large table, however, and one job ingests all of the data for that table, overall pipeline performance can slow down because one Spark executor processes all of the data from that table. To take advantage of parallel ingestion if a data source has one or more large tables, you can use Anzo Semantic Service calls to partition the tables. The resulting ETL job for a partitioned table has smaller sections that can be ingested in parallel by multiple executors.
This topic provides instructions on using the Anzo command line interface to compute a partition and assign the partition to a table so that Anzo can leverage the information during ingestion.
When a pipeline is configured to use the Sparkler ETL engine to compile jobs, Sparkler automatically attempts to partition RDBMS tables if the table has a primary column that is an integer data type and a data source profile has been generated (as described in Generating a Source Data Profile). Sparkler can also be configured to attempt to partition tables without requiring a data profile. For more information, see Configuring a Sparkler Engine.
Computing and Assigning Partitions to a Table
When creating a partition for a table, choose a column with an integer data type to partition on. You add metadata to that column to define the size and number of partitions, and then you call an Anzo service that computes the predicates for the partition. Once the predicates are computed, you call another service to assign the partitions to the table so that Anzo can apply the partitions when generating the ETL job. The steps below guide you through computing and assigning partitions.
When you supply the metadata for computing partitions, you will need to know the row count for the table that will be partitioned. Calculating the row count in Anzo requires generating statistics on the schema. You might want to generate statistics in advance before starting the steps below. For instructions, see Generating a Source Data Profile.
- First, view the metadata for the data source so that you can retrieve the URI for the schema that contains the table to partition. Run the following command to return the data source metadata:
anzo get data_source_uri
The data source URI can be found on the Overview tab for the data source.
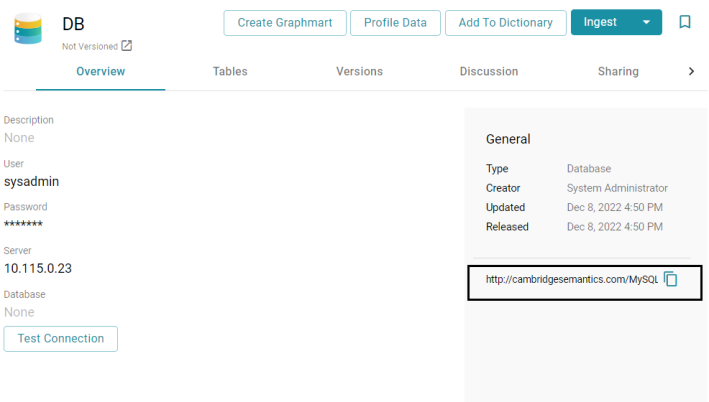
For example:
anzo get http://cambridgesemantics.com/MySQLDatabaseDataSource/690c96c79b0c4383bc908310e6fdba3f
Anzo returns the metadata for the data source.
- In the data source metadata results, look for the schema URI for which you want to create a partition. The schema URI is the object of a triple that follows the pattern below:
data_source_uri <http://cambridgesemantics.com/ontologies/DataSources#dbSchema> schema_uri
For example, the URI below identifies the northwind schema:
data_source_uri <http://cambridgesemantics.com/ontologies/DataSources#dbSchema> <http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind>
- Using the schema URI from the previous step, run the following command to view the metadata for the schema:
anzo get schema_uri
For example:
anzo get http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind
Anzo returns the metadata for the schema.
- In the schema metadata results, find the URI for the table that you want to partition. The table URI is the object of a triple that follows the pattern below:
schema_uri <http://cambridgesemantics.com/ontologies/DataSources#schemaTable> table_uri
For example, the URI below identifies the ORDERS table in the northwind schema:
schema_uri <http://cambridgesemantics.com/ontologies/DataSources#schemaTable> <http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS>
- Next, identify the URI for the column that you want to use for computing the partitions. The column that you choose should have an integer data type. You can view the column URIs as well as metadata for the columns in the output of the previous step, or you can run the following command to narrow the results to the list of columns for the table. This command finds all of the results for which the table URI is the subject:
anzo find -sub table_uri
For example:
anzo find -sub http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS
The column URIs are the object of a triple that follows the pattern below:
table_uri <http://cambridgesemantics.com/ontologies/DataSources#tableColumn> column_uri
For example, the URI below identifies the ORDERID column in the ORDERS table:
table_uri <http://cambridgesemantics.com/ontologies/DataSources#tableColumn> <http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS/ORDERID>
- Once you retrieve the column URI, create a .trig file that includes the metadata for the column. You will add new partition properties to the file. Run the following command to output a .trig file that contains the column metadata:
anzo find -sub column_uri --output-file /path/filename.trig
For example, the following command retrieves all of the results for which ORDERID is the subject. It outputs the results to a file called ComputePartitions.trig in the current directory:
anzo find -sub http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS/ORDERID --output-file ComputePartitions.trig
The output below shows the contents of the resulting ComputePartitions.trig file.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . <http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind> { <http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS/ORDERID> a <http://cambridgesemantics.com/ontologies/DataSources#Column> , <http://cambridgesemantics.com/ontologies/DataSources#DataField> ; <http://cambridgesemantics.com/ontologies/DataSources#columnAutoIncrement> "false"^^xsd:boolean ; <http://cambridgesemantics.com/ontologies/DataSources#columnCaseSensitive> "false"^^xsd:boolean ; <http://cambridgesemantics.com/ontologies/DataSources#columnDerivedOwlProperty> <http://cambridgesemantics.com/ont/autogen/Fu/DB/northwind#Orders_OrderID> ; <http://cambridgesemantics.com/ontologies/DataSources#columnIndex> "1"^^xsd:int ; <http://cambridgesemantics.com/ontologies/DataSources#columnJdbcType> "integer" ; <http://cambridgesemantics.com/ontologies/DataSources#columnName> "OrderID" ; <http://cambridgesemantics.com/ontologies/DataSources#columnNullable> "false"^^xsd:boolean ; <http://cambridgesemantics.com/ontologies/DataSources#columnPrimaryKey> "true"^^xsd:boolean ; <http://cambridgesemantics.com/ontologies/DataSources#columnRemarks> "" ; <http://cambridgesemantics.com/ontologies/DataSources#columnSize> "10"^^xsd:int ; <http://cambridgesemantics.com/ontologies/DataSources#columnType> xsd:int ; <http://cambridgesemantics.com/ontologies/DataSources#columnTypeName> "INT" . } - Modify the .trig file from the previous step to specify the partitioning metadata. The metadata to add includes the number of partitions to create as well as the total number of rows in the data source table. To provide the required metadata, edit the file as follows:
- At the top of the file, replace the schema URI with the following service URI:
<http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputePartitioningPredicatesRequest>
In the example above,
<http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind>is replaced by<http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputePartitioningPredicatesRequest> - Towards the bottom of the file, at the end of the column metadata and inside the ending brace ( } ), add the following contents:
# PARTITIONING METADATA <http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputePartitioningPredicatesRequest> <http://cambridgesemantics.com/ontologies/2015/08/SDIService#numberOfPartitions> "number_of_partitions"^^<http://www.w3.org/2001/XMLSchema#int> ; <http://cambridgesemantics.com/ontologies/2015/08/SDIService#numberOfRows> "number_of_rows"^^<http://www.w3.org/2001/XMLSchema#long> ; <http://cambridgesemantics.com/ontologies/2015/08/SDIService#tableColumn> column_uri ; a <http://cambridgesemantics.com/ontologies/2015/08/SDIService#BaseComputePartitioningPredicatesRequest> , <http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputeColumnBasedPartitioningRequest> .
- In the new triples, replace the placeholders with the appropriate values for your environment:
- number_of_partitions: Specify the number of partitions to create for the table. Choose the value based on the number of Spark nodes or executors that are available. If you do not know the number, 12 is recommended.
- number_of_rows: Specify the total number of rows for the table. After generating source data metrics, you can view the row count by viewing the Tables tab for the schema and clicking the table to show the metrics for that table. For example:

- column_uri: The URI for the partition column from step 5. You can copy the URI from the top of the file.
The example below shows the complete ComputePartitions.trig file after completing steps a, b, and c.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . <http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputePartitioningPredicatesRequest> { <http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS/ORDERID> a <http://cambridgesemantics.com/ontologies/DataSources#Column> , <http://cambridgesemantics.com/ontologies/DataSources#DataField> ; <http://cambridgesemantics.com/ontologies/DataSources#columnAutoIncrement> "false"^^xsd:boolean ; <http://cambridgesemantics.com/ontologies/DataSources#columnCaseSensitive> "false"^^xsd:boolean ; <http://cambridgesemantics.com/ontologies/DataSources#columnDerivedOwlProperty> <http://cambridgesemantics.com/ont/autogen/Fu/DB/northwind#Orders_OrderID> ; <http://cambridgesemantics.com/ontologies/DataSources#columnIndex> "1"^^xsd:int ; <http://cambridgesemantics.com/ontologies/DataSources#columnJdbcType> "integer" ; <http://cambridgesemantics.com/ontologies/DataSources#columnName> "OrderID" ; <http://cambridgesemantics.com/ontologies/DataSources#columnNullable> "false"^^xsd:boolean ; <http://cambridgesemantics.com/ontologies/DataSources#columnPrimaryKey> "true"^^xsd:boolean ; <http://cambridgesemantics.com/ontologies/DataSources#columnRemarks> "" ; <http://cambridgesemantics.com/ontologies/DataSources#columnSize> "10"^^xsd:int ; <http://cambridgesemantics.com/ontologies/DataSources#columnType> xsd:int ; <http://cambridgesemantics.com/ontologies/DataSources#columnTypeName> "INT" . # PARTITIONING METADATA <http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputePartitioningPredicatesRequest> <http://cambridgesemantics.com/ontologies/2015/08/SDIService#numberOfPartitions> "12"^^<http://www.w3.org/2001/XMLSchema#int> ; <http://cambridgesemantics.com/ontologies/2015/08/SDIService#numberOfRows> "830"^^<http://www.w3.org/2001/XMLSchema#long> ; <http://cambridgesemantics.com/ontologies/2015/08/SDIService#tableColumn> <http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS/ORDERID> ; a <http://cambridgesemantics.com/ontologies/2015/08/SDIService#BaseComputePartitioningPredicatesRequest> , <http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputeColumnBasedPartitioningRequest> .}
- At the top of the file, replace the schema URI with the following service URI:
- When the .trig file is complete, save and close the file. It becomes input to the Anzo Compute Column Based Table Partitioning Predicates service. The service returns the response to use to assign the partitions that can be used during ingestion. Run the following command to call the partitioning service:
anzo call http://cambridgesemantics.com/semanticServices/SDIService#computeColumnBasedTablePartitioningPredicates /path/filename.trig > /path/output_file.trig
Where filename.trig is the file from step 7 and output_file.trig is the new file to create. For example, the following command calls the partitioning service and saves the response in a file called AssignPartitions.trig in the current directory.
anzo call http://cambridgesemantics.com/semanticServices/SDIService#computeColumnBasedTablePartitioningPredicates ComputePartitions.trig > AssignPartitions.trig
The service returns the list of partition predicates. The number of predicates depends on the number of partitions that were specified in the compute file. For example, a portion of the resulting AssignPartitions.trig file is shown below. You can see the complete file by clicking here.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . <http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputePartitioningPredicatesResponse> { _:u0d4a3eab-713f-4dbe-b5ad-da5676d6b721 a <http://cambridgesemantics.com/ontologies/DataSources#PartitionPredicate> ; <http://cambridgesemantics.com/ontologies/DataSources#value> "<http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS/ORDERID> >= 69 && <http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS/ORDERID> < 138" . _:u255f046c-73a1-44ef-b446-c5a6126c9cc1 a <http://cambridgesemantics.com/ontologies/DataSources#PartitionPredicate> ; <http://cambridgesemantics.com/ontologies/DataSources#value> "<http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS/ORDERID> >= 414 && <http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS/ORDERID> < 483" . ... } - Modify the .trig file from the previous step to specify the metadata that the Anzo Assign Table Partitioning Predicates service will use to assign the partitions. To provide the required metadata, edit the file as follows:
- At the top of the file, replace the ComputePartitioningPredicatesResponse URI with the following Assign service URI:
<http://cambridgesemantics.com/ontologies/2015/08/SDIService#AssignTablePartitioningPredicatesRequest>
In the example above,
<http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputePartitioningPredicatesResponse>is replaced by<http://cambridgesemantics.com/ontologies/2015/08/SDIService#AssignTablePartitioningPredicatesRequest> - At the bottom of the file inside the ending brace ( } ), locate the following triple pattern:
<http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputePartitioningPredicatesResponse> <http://cambridgesemantics.com/ontologies/2015/08/SDIService#partitioningPredicates> list_of_predicate_uris .Where list_of_predicate_uris is a comma-separated list of all of the predicate URIs from the file. For example, this is the relevant statement from the AssignPartitions.trig file shown above:
<http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputePartitioningPredicatesResponse> <http://cambridgesemantics.com/ontologies/2015/08/SDIService#partitioningPredicates> _:u0d4a3eab-713f-4dbe-b5ad-da5676d6b721 , _:u255f046c-73a1-44ef-b446-c5a6126c9cc1 , _:u2aa40e92-e60d-4b11-9d75-24e84c91ec06 , _:u3472d783-ce53-4aa3-acc2-a9e57d3f318b , _:u3bdca1ac-be4e-4374-b8b9-ce22c18c179a , _:u3eea38d2-8f40-4cb4-b297-8378d68d90e6 , _:u5752b0a1-4262-403a-a029-8a2f54a18f2f , _:u60d4dea2-f06f-45d5-87bf-242e295494ff , _:u702c4eed-2531-4578-a7e7-5ea4120e86ce , _:ub35b741b-6020-4f7d-9a71-7d6c17adf9c9 , _:ub4a0d80b-7e17-4d88-8648-e5c05cea2069 , _:ub8b7ef03-3bbc-41c4-ba43-360bc69620a0 . - Like the substep a above, replace the ComputePartitioningPredicatesResponse URI with the Assign service URI.
In the example above,
<http://cambridgesemantics.com/ontologies/2015/08/SDIService#ComputePartitioningPredicatesResponse>is replaced by<http://cambridgesemantics.com/ontologies/2015/08/SDIService#AssignTablePartitioningPredicatesRequest> - At the end of the list of predicate URIs, change the period (.) to a semicolon (;), and then add the following new statements after the semicolon :
<http://cambridgesemantics.com/ontologies/2015/08/SDIService#tableURI> table_uri ; a <http://cambridgesemantics.com/ontologies/2015/08/SDIService#AssignTablePartitioningPredicatesRequest> .
Where table_uri is the table URI from step 4. For example:
<http://cambridgesemantics.com/ontologies/2015/08/SDIService#tableURI> <http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS> ; a <http://cambridgesemantics.com/ontologies/2015/08/SDIService#AssignTablePartitioningPredicatesRequest> .
For example, the end of the AssignPartitions.trig file now looks like this:
... <http://cambridgesemantics.com/ontologies/2015/08/SDIService#AssignTablePartitioningPredicatesRequest> <http://cambridgesemantics.com/ontologies/2015/08/SDIService#partitioningPredicates> _:u0d4a3eab-713f-4dbe-b5ad-da5676d6b721 , _:u255f046c-73a1-44ef-b446-c5a6126c9cc1 , _:u2aa40e92-e60d-4b11-9d75-24e84c91ec06 , _:u3472d783-ce53-4aa3-acc2-a9e57d3f318b , _:u3bdca1ac-be4e-4374-b8b9-ce22c18c179a , _:u3eea38d2-8f40-4cb4-b297-8378d68d90e6 , _:u5752b0a1-4262-403a-a029-8a2f54a18f2f , _:u60d4dea2-f06f-45d5-87bf-242e295494ff , _:u702c4eed-2531-4578-a7e7-5ea4120e86ce , _:ub35b741b-6020-4f7d-9a71-7d6c17adf9c9 , _:ub4a0d80b-7e17-4d88-8648-e5c05cea2069 , _:ub8b7ef03-3bbc-41c4-ba43-360bc69620a0 ; <http://cambridgesemantics.com/ontologies/2015/08/SDIService#tableURI> <http://cambridgesemantics.com/DatabaseDataSource/aff6a2f7a1354140871b763dffefaab4/Schema/northwind/ORDERS> ; a <http://cambridgesemantics.com/ontologies/2015/08/SDIService#AssignTablePartitioningPredicatesRequest> . }If you would like to view the complete sample file, click here.
- At the top of the file, replace the ComputePartitioningPredicatesResponse URI with the following Assign service URI:
- When the .trig file is complete, save and close the file. It becomes input to the Assign Table Partitioning Predicates service. The service assigns the partitions to the data source to inform the ingestion process. Run the following command to call the assigning service:
anzo call http://cambridgesemantics.com/semanticServices/SDIService#assignTablePartitioningPredicates filename.trig
Where filename.trig is the file you edited in the previous step. For example:
anzo call http://cambridgesemantics.com/semanticServices/SDIService#assignTablePartitioningPredicates AssignPartitions.trig
When the prompt returns, the process is complete. If you view the metadata for the table that was partitioned (e.g., run
anzo find -sub table_uri), the metadata contains a new <http://cambridgesemantics.com/ontologies/DataSources#tablePredicates> URI that lists the partition predicates.
Once the partitioning is complete, the source data can be onboarded to Anzo. For instructions on onboarding the data, see Ingesting Data Sources via ETL Pipelines.