Anzo 4.x Releases
If you are upgrading to 4.x from a previous release, see Anzo 4.x Installation and Upgrade Notes for important notes about upgrades to Anzo components.
- Anzo Version 4.4.2
- Anzo Version 4.4.1
- Anzo Version 4.4.0
- Anzo Version 4.3.6
- Anzo Version 4.3.5
- Anzo Version 4.3.4
- Anzo Version 4.3.3
- Anzo Version 4.3.1
- Anzo Version 4.3.0
- Anzo Version 4.2.12
- Anzo Version 4.2.11
- Anzo Version 4.2.0
- Anzo Version 4.1.0
- Anzo Version 4.0.8
- Anzo Version 4.0.7
Anzo Version 4.4.2
This section describes the improvements and issues that were fixed in Anzo Version 4.4.2.
- Elasticsearch Performance Improvements
- Anzo Unstructured Requires AnzoGraph Version 2.0.1
- Elasticsearch Index Merge Used Wrong Directory if FLDS Path Excluded Trailing Slash
- Elasticsearch Timed Out During Long-Running Index Merge
- Non-Unique File Names Generated by Local Spark Engine when Processing Large File
- Inconsistent Results for Unstructured Document Search Lens
- Graphmart Layers Required Refresh after Running an Unstructured Pipeline
- Data Type Selection not Populated in Dashboard Lenses
Elasticsearch Performance Improvements
Version 4.4.2 significantly increases the performance of Elasticsearch unstructured document text searches. In addition, limitations on the number of results that could be searched have been removed so that users can search over all of the results from Elasticsearch.
Anzo Unstructured Requires AnzoGraph Version 2.0.1
The Elasticsearch improvements in this release include changes to AnzoGraph. If you use Elasticsearch and the Anzo Unstructured infrastructure, you must install AnzoGraph Version 2.0.1. For details about the AnzoGraph release, see AnzoGraph Version 2.0.1.
Elasticsearch Index Merge Used Wrong Directory if FLDS Path Excluded Trailing Slash
If an FLDS was created manually by importing RDF files to the catalog or importing a handwritten .trig file, and the path to the FLDS did not include a trailing slash, Elasticsearch used the wrong directory when merging indexes. In Version 4.4.2, Anzo automatically adds the trailing slash to data locations if it is missing.
Elasticsearch Timed Out During Long-Running Index Merge
In some cases, the Elasticsearch service could throw a socket timeout exception during long-running index merges. Version 4.4.2 ensures that Elasticsearch can complete long-running merges without failing due to socket timeout exceptions.
Non-Unique File Names Generated by Local Spark Engine when Processing Large File
In certain circumstances when the embedded Spark ETL engine processed an extremely large CSV file, some records were missing from the resulting FLDS. The issue occurred because non-unique file names were generated in the output in some cases, and records were overwritten. Version 4.4.2 resolves the issue by ensuring that all file names, both permanent and temporary, are unique.
Inconsistent Results for Unstructured Document Search Lens
In some cases the unstructured document search lens returned inconsistent results depending on the configuration of the underlying Anzo Unstructured (AU) infrastructure. Version 4.4.2 resolves the issue so that the document search lens has the same behavior regardless of the AU infrastructure configuration.
Graphmart Layers Required Refresh after Running an Unstructured Pipeline
In some cases after an unstructured pipeline completed, all data layers that referenced the unstructured FLDS became "dirty" and required refresh even though the underlying data did not change. Version 4.4.2 corrects the issue so that layers in an unstructured graphmart remain pristine if the data does not change and an unstructured pipeline is run.
Data Type Selection not Populated in Dashboard Lenses
In a Hi-Res Analytics dashboard, when a user tried to add a data type to a lens from Properties > Add a New Data Type, the list of data types was not populated and a type could not be selected. Version 4.4.2 resolves the issue so that the data types list is populated and users can add a new data type to a lens.
Anzo Version 4.4.1
This section describes the improvements and issues that were fixed in Anzo Version 4.4.1.
Anzo Unstructured Improvements
- New Binary Store Options for Unstructured Pipelines
- Remove Staging FLDS after Pipeline Completion
- Workers Make Fewer Calls to Anzo
- Limit Number of Requests in Queue
- Add Files to the Binary Store without Extracting Text
- Process Empty Documents without Error
General Improvements
- Improved Performance for OData Queries with $expand Operator
- Improved Performance when Publishing ETL Jobs with Large Models
- Graphmart Exports and Versions Include Data Set Configuration
- AnzoGraph Accepts S3 Credentials
Fixed Issues
- Authentication Failed for SAML SSO POST Binding Type
- Could Not Export or Version Mappings with Formula-Based Type Definitions
- Query Builder Displayed Results from Previous Query
- Elasticsearch Could Not Find Archived Snapshots
- Too Many Open Files when Running Unstructured Pipeline
- Unstructured Pipeline Continued to Run after Being Stopped
- Initial Documents in Unstructured Pipeline Fail with VFS Error
- Post-Processing Phase Not Started for Some Unstructured Pipelines
- Document Metadata Types Unavailable for Unstructured Dashboards
- Error when Viewing Model with Circular Reference
- Export Failed for Current Version of a Model
- Style Changes Not Applied to Heat Map Lens
New Binary Store Options for Unstructured Pipelines
Version 4.4.1 introduces two new options for configuring and managing binary store objects that are created during unstructured pipeline processing. Both of these options can be used to reduce the time it takes to process an unstructured pipeline:
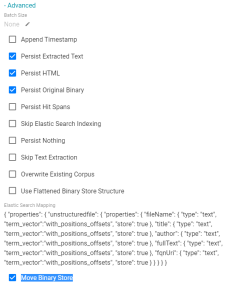
Move the Binary Store Instead of Making a Copy
When the Anzo Unstructured worker nodes process documents, they write binary store data to a staging location. At the end of the pipeline process, the binary store in the staging directory is copied to the final location. Since the binary store can be large and have a nested structure, copying the data can take a very long time. In Version 4.4.1, a new Move Binary Store option was added to the unstructured pipeline Advanced configuration settings (highlighted in the image below). Enabling this option moves the binary store from staging to the final directory rather than copying it. Since moving files is almost instantaneous, the final processing time is significantly reduced.
Use a Flattened Binary Store Structure
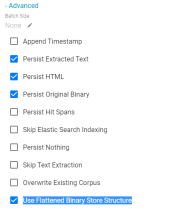
In addition to the Move Binary Store option, Version 4.4.1 adds a Use Flattened Binary Store Structure option. Enabling this option configures Anzo Unstructured to flatten binary stores instead of using a nested structure. This aids performance when binary store files are copied to other locations outside of the unstructured pipeline workflow.
Remove Staging FLDS after Pipeline Completion
In addition to the binary store options for improving unstructured pipeline performance, Version 4.4.1 moves the deletion of the staging FLDS files to a background process. This means that the pipeline no longer waits for the staging files to be deleted before completing the pipeline. The deletion occurs in the background.
Workers Make Fewer Calls to Anzo
To increase pipeline performance, Version 4.4.1 reduces the number of times the Anzo Unstructured worker nodes run queries against and communicate with the Anzo server.
Limit Number of Requests in Queue
When running an unstructured pipeline that processes a large number of documents that have a high per-document processing time, the unprocessed request queue could become very large and strain available resources. Version 4.4.1 introduces the option to specify a maximum number of unprocessed requests that can be queued at one time.
Follow the instructions below to modify the unprocessed request limit value in the Anzo Unstructured Distributed bundle.
- In the Anzo user interface, expand the Administration menu and click Advanced Configuration.
- Search for the Anzo Unstructured Distributed bundle and view its details.
- Click the Services tab and expand the service. For example:

- Modify the com.cambridgesemantics.anzo.unstructured.distributed.unprocessedRequestLimit property as needed and save the change.
- Restart the Anzo Unstructured Distributed bundle to apply the configuration change.
Add Files to the Binary Store without Extracting Text
Version 4.4.1 introduces the option to configure an unstructured pipeline so that it adds files to the binary store without extracting text. To configure a pipeline so that it does not extract text from files:
- In the Anzo user interface, view the Overview tab for the pipeline and click Advanced to display the advanced settings.
- Find the Rich Text Extractor setting. Click the Edit icon (
 ) for that field, and then remove all of the extractors. Save the change.
) for that field, and then remove all of the extractors. Save the change.
- In the list of settings directly below Advanced, clear any selected checkboxes. Then select Persist Original Binary, Persist Nothing, and Skip Text Extraction.
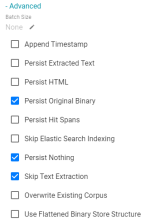
After the pipeline is run, the binary store in the FLDS directory will contain only the original documents and not the full text or full HTML versions of the documents.
Process Empty Documents without Error
In Version 4.4.1, a new Allow Empty Documents option was added to the unstructured pipeline Advanced configuration settings (highlighted in the image below). When this option is enabled, zero-byte documents will be processed instead of logging an error when the pipeline is run.
![]()
Improved Performance for OData Queries with $expand Operator
Version 4.4.1 modifies the query generator for OData queries to improve performance for queries that include the $expand string operator.
Improved Performance when Publishing ETL Jobs with Large Models
Version 4.4.1 improves performance when publishing ETL jobs with large data models.
Graphmart Exports and Versions Include Data Set Configuration
Version 4.4.1 adds data set configuration information to the list of related entities when exporting or versioning a graphmart.
AnzoGraph Accepts S3 Credentials
In previous releases, AnzoGraph could not load files from an S3 file store unless the bucket had public permissions. In Version 4.4.1, Anzo sends the file store credentials to AnzoGraph and AnzoGraph uses the credentials to access the FLDS.
Note: AnzoGraph Version 2.0.0 or later is required.
Authentication Failed for SAML SSO POST Binding Type
A previous Anzo version introduced an authentication binding type property for SAML SSO provider configurations. The authentication binding type value was set to HTTP Redirect and could not be changed, causing authentication to fail for systems using HTTP POST binding. In Version 4.4.1, the authentication binding type property is configurable and supports HTTP POST binding.
To configure HTTP POST binding, modify the SAML configuration to add the following value for the <http://cambridgesemantics.com/ontologies/SSOProvider#:authReqBinding> property:
"urn:oasis:names:tc:SAML:2.0:bindings:HTTP-POST"
Could Not Export or Version Mappings with Formula-Based Type Definitions
In previous Anzo versions, mappings could not be exported or versioned if they contained Type definitions that used formulas. Version 4.4.1 ensures that mappings with formula-based Type definitions can be exported and versioned.
Query Builder Displayed Results from Previous Query
Version 4.4.1 fixes an issue where the Query Builder failed to clear the results of one query before displaying the results of the subsequent query.
Elasticsearch Could Not Find Archived Snapshots
If Overwrite FLDS was enabled in an Export Step so that the existing FLDS was archived before the current data was exported, the Elasticsearch service failed to find the latest FLDS snapshot because it did not search in the archives directory. In Version 4.4.1, Elasticsearch finds the snapshot in the archives directory if it does not exist in the current FLDS directory.
Too Many Open Files when Running Unstructured Pipeline
Version 4.4.1 fixes an issue where unstructured pipelines failed to terminate some processes when creating an FLDS, causing a "too many open files" error.
Unstructured Pipeline Continued to Run after Being Stopped
In some cases, an unstructured pipeline continued to run after a user clicked End Pipeline to stop it. Version 4.4.1 ensures that a pipeline stops running if a user clicks the End Pipeline button.
Initial Documents in Unstructured Pipeline Fail with VFS Error
Version 4.4.1 fixes a sporadic issue where an unstructured pipeline failed to process the first few documents that were read. The documents failed with a virtual filesystem error.
Post-Processing Phase Not Started for Some Unstructured Pipelines
In certain circumstances when the Anzo Unstructured worker nodes processed documents very quickly, a pipeline finished processing all of the documents but the post-processing phase failed to start. Version 4.4.1 ensures that post-processing is initiated in these cases.
Document Metadata Types Unavailable for Unstructured Dashboards
Version 4.4.1 fixes an issue that prevented some of the document metadata data types from being displayed on unstructured dashboards.
Error when Viewing Model with Circular Reference
In previous versions, viewing a data model that included one or more self-referential classes caused the user interface to freeze. Version 4.4.1 ensures that models with self-referential inheritance can be viewed in the model editor.
Export Failed for Current Version of a Model
In some cases, users were unable to export the current version of a data model. The Export Current State dialog box did not respond. Version 4.4.1 ensures that users are able to export the current state of a model by clicking the Export icon (![]() ) in the Model editor.
) in the Model editor.
Style Changes Not Applied to Heat Map Lens
Version 4.4.1 fixes an issue in the Hi-Res Analytics application where changes to the colors displayed in a heat map were not applied to the lens.
Anzo Version 4.4.0
This section describes the improvements and issues that were fixed in Anzo Version 4.4.0.
New Features
- Mandatory Anzo for Office Mapping Tool Upgrade
- Onboard Data from Databases Incrementally
- SSO Provider Configuration in the User Interface
- SAS Data Source Support
- Export Data in Memory to FLDS
- Ability to Version and Export/Import Graphmart Configurations
- Modify ACLs for Exported Entities
- Import Exported Versions from a Computer
- Modify Values and ACLs on Import
- Configure Default Access Policies
- Ability to Reverse Order of Suggested Foreign Keys
- Create Object Properties from Model View
- Configure Maximum Page Size for OData Feeds
User Interface Improvements
- Redesigned Anzo Login Page
- Dialog Boxes Can Be Resized and Moved
- Collapsible Main Menu
- Redesigned Sharing Tab
- Redesigned Mapping Tool Login Screen
- Pipeline History Logs Show Most Recent Information
- Warning when Inherited Models are Missing from Working Set
- Clarify Object Counts in Dashboards
- Redesigned Volume Manager
- Removed Import Button from Model Working Set Screen
Anzo Unstructured Improvements
- Option to Overwrite Existing FLDS for Unstructured Pipelines
- Option to Trust Elasticsearch Certificates
- Anzo Unstructured Worker Clients Default to SSL
- Unstructured Pipeline Progress Errors Display More Information
- FLDS Crawler Processes Document Metadata
Other Improvements
- Specify Root Element Name for JSON Data Sources
- Option to Split Audit Log by Type
- Connect Mappings by Base Class in ETL Job
- Option to Include or Exclude Rules in RDFS+ Inference Steps
- Server Filesystem Defaults to Globally Accessible
- Upgrade to Spark 2.4
- Option to Generate AnzoGraph Statistics after Loading Graphmart
Fixes
- Updates to Existing Anzo Data Store are Applied
- Display Time Values Consistently for all Pipeline History Views
- Ensure URIs are Created when Template has NULL values
Mandatory Anzo for Office Mapping Tool Upgrade
Pre-4.4.0 versions of the Anzo for Office (AFO) mapping tool are incompatible with Anzo 4.4.0. The server's default access control list format was changed, and the AFO client was modified to read the new format from the server. If you use a 4.3.x or earlier version of the AFO mapping tool with Anzo Version 4.4.0, mappings will be read-only. After upgrading Anzo, upgrade AFO to the latest version included with your installation. For instructions, see Installing the Anzo for Excel and Office Plugins in the Anzo Deployment and User Guide.
Onboard Data from Databases Incrementally
Version 4.4.0 introduces the ability to onboard only the data that has been added to a database data source since the last time the data was onboarded. For more information, see Onboarding Data from a Database Incrementally in the Anzo Deployment and User Guide.
Note: Anzo onboards new source data only; it does not process data that was updated or deleted in the source database. Running the ETL job for an incremental schema query replaces the existing data with the new data.
SSO Provider Configuration in the User Interface
Version 4.4.0 adds to the user interface the ability to configure single sign-on (SSO) access for the following SSO providers:
- Direct and Indirect Basic
- Direct and Indirect Kerberos
- JSON Web Tokens (JWT) Header and Parameter
- OpenID Connect (OIDC)
- Security Assertion Markup Language (SAML)
Known Limitation
Certain changes to SSO provider support in Version 4.4.0 are incompatible with SSO configurations from previous Anzo releases. If you are upgrading to Version 4.4.0 and have an existing SSO configuration, Cambridge Semantics recommends that you follow the instructions below to remove the configuration before upgrading. After the upgrade, use the Anzo user interface to re-configure the SSO provider. For instructions, see Configuring SSO Access in the Anzo Deployment and User Guide.
Removing an SSO Configuration Using the Anzo CLI
Using the .trig file that was imported to create the existing SSO provider, run the following command to remove the SSO configuration:
anzo update --remove filename.trig
SAS Data Source Support
Version 4.4.0 adds support for onboarding data from SAS files. For information, see Importing Data from SAS Files in the Anzo Deployment and User Guide.
Note: When importing data from SAS files, Anzo excludes any metadata that is defined in the files.
Export Data in Memory to FLDS
Version 4.4.0 introduces a new Export Step that enables users to export the graphmart data in memory to a file-based linked data set (FLDS) on the file store. For information, see Adding a Step that Exports Data to an FLDS in the Anzo Deployment and User Guide.
Note: If you export unstructured data and choose to add it to an existing FLDS, the Elasticsearch index for the newly exported data will not be merged with the original index.
Ability to Version and Export/Import Graphmart Configurations
Version 4.4.0 adds versioning, export, and import capability to graphmarts. A versioned snapshot or export of a graphmart includes data layer and step configuration details only. It does not export or version the data that is in the graphmart, nor does it include other entities such as data source or pipeline configuration information.
Modify ACLs for Exported Entities
Version 4.4.0 adds the option to modify permissions on exported entities. When the Include Metadata option is enabled when exporting an artifact, the Advanced option includes the Sharing tab, where users can modify the permissions for the exported objects. For example:
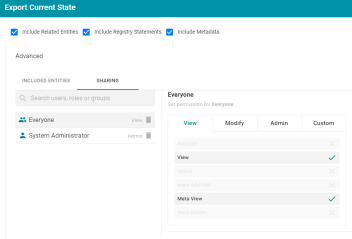
For more information, see Exporting Versions in the Anzo Deployment and User Guide.
Import Exported Versions from a Computer
When migrating entities between servers in previous versions of Anzo, the exported .zip file had to be placed on a connected file store so that it could be imported to Anzo. Version 4.4.0 introduces the option to upload exported files from a computer. When specifying the Version Location for the file to import, the File Location dialog box now includes an Upload Files tab, where users can browse to a file on their computer, and a Select Files tab, where users can select a file on the file store.
![]()
For more information about importing files, see Importing Exported Versions in the Anzo Deployment and User Guide.
Modify Values and ACLs on Import
Version 4.4.0 introduces the ability to modify replaceable property values and the ACL configuration as part of the import process. For more information, see Importing Exported Versions in the Anzo Deployment and User Guide.
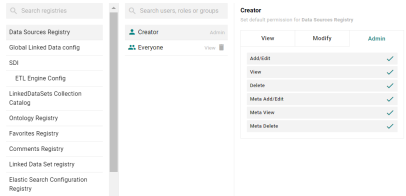
Configure Default Access Policies
Version 4.4.0 adds to the Administration menu a screen that enables administrators to manage the Default Access Policies for Anzo registries.
Ability to Reverse Order of Suggested Foreign Keys
Version 4.4.0 adds the option to reverse the primary/foreign key order for the keys that Anzo suggests after generating metrics for CSV, JSON, or XML data sources. The Suggested Keys screen now includes a Reverse button in addition to the Activate button. For example:
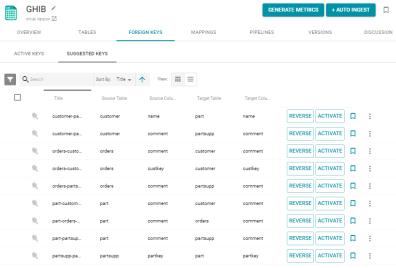
For information about generating metrics to create foreign key suggestions, see Generating Data Quality Metrics for a Data Source in the Anzo Deployment and User Guide.
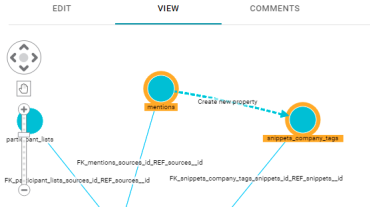
Create Object Properties from Model View
In Version 4.4.0, users can create new object properties in a model by selecting two nodes in the model view. From the View tab in the model manager, press and hold the Shift key and click two nodes to select them. Anzo adds a Create new property arrow between the objects. For example:
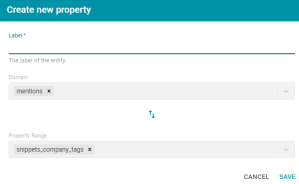
Clicking the arrow opens the Create new property dialog box where users can specify the label for the new property and reverse the Domain and Property Range direction if needed. For example:
Configure Maximum Page Size for OData Feeds
When a user sends a request to an Anzo Data on Demand endpoint, they do not necessarily know the total number of results that will be returned. In some cases, the result set can be hundreds of millions of values, and the request times out before the results can be returned. Version 4.4.0 introduces the option to configure the Data on Demand service to specify a maximum limit on the number of results that can be returned for a single OData feed request. If a user sends a request and the result set is larger than the maximum value, Anzo will limit the results to the configured maximum value. Follow the instructions below to configure the Anzo Data on Demand bundle to enforce a maximum page size:
- In the Anzo console, expand the Administration menu and click Advanced Configuration.
- Search for the Anzo DataOnDemand bundle and view its details.
- Click the Services tab and expand DataOnDemandServiceActivator.
- At the bottom of the list of properties, click Add Property. Anzo opens the Add Property dialog box.

- In the Name field, specify com.cambridgesemantics.anzo.dataondemand.enforcePageSize, and set the Value to true. Then click Save.
- Click Add Property again. In the Name field, specify com.cambridgesemantics.anzo.dataondemand.maxPageSize, and set the Value to the maximum number of results that to return per request. Then click Save. The two settings are displayed on the Services screen. For example:

- Restart the Anzo DataOnDemand bundle to apply the configuration changes.
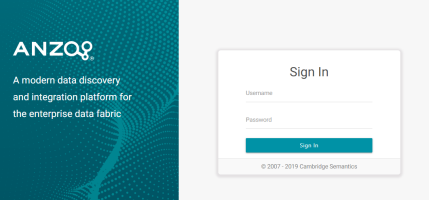
Redesigned Anzo Login Page
Version 4.4.0 introduces a redesigned Anzo login screen:
Dialog Boxes Can Be Resized and Moved
In Version 4.4.0, all dialog boxes in the Anzo user interface can be resized and repositioned on the screen.
Collapsible Main Menu
Version 4.4.0 enables users to collapse the main menu and navigate using icons and floating submenus. For example:
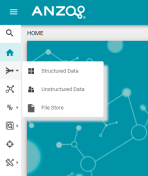
Redesigned Sharing Tab
In Version 4.4.0, the Sharing tab for all entities has been redesigned to complement the new registry access policy editor (see Configure Default Access Policies). For example:
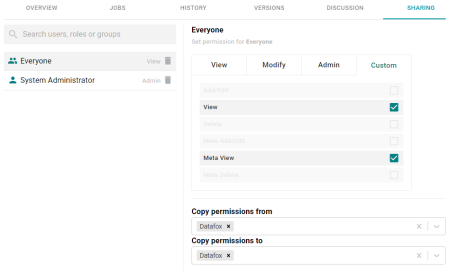
When modifying permissions, make the changes to the Custom tab. The changes will be reflected on the View and/or Modify tabs.
Redesigned Mapping Tool Login Screen
The login screen for the Anzo For Office mapping tool has been redesigned to complement the Anzo login screen:
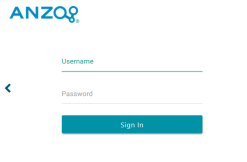
Pipeline History Logs Show Most Recent Information
In previous versions, when users viewed the pipeline history logs, they had to scroll to the bottom of the file to see the most recent information. In Version 4.4.0, the end of a file is displayed when the dialog opens so that users do not need to scroll to the end.
Warning when Inherited Models are Missing from Working Set
In Version 4.4.0, if a user adds a model to the working set and that model has inherited models that are not included the working set, Anzo displays a warning to let the user know that models are missing. Clicking the warning adds the missing model to the working set.
Clarify Object Counts in Dashboards
To make object counts on dashboards (such as in the Data Types panel) easier to read, Version 4.4.0 adds comma separators to large numbers.
Redesigned Volume Manager
Version 4.4.0 redesigns the Volume Manager in the Administration menu to make it consistent with other areas of the user interface when a user creates a new volume.
For this release, users must use the alternate Anzo Admin console to mount existing volumes. For instructions, see Mounting an Existing Volume in the Anzo Deployment and User Guide.
Removed Import Button from Model Working Set Screen
Previous versions included Import and Upload Models buttons on the Manage Data Model Working Set screen. Having both options available could create confusion about which option to use. In Version 4.4.0, the Import button was removed from the Working Set screen. When users want to upload a model that is external to Anzo, they click the Upload Models button on the Manage Data Model Working Set screen. When users want to import a version of a model that was exported from Anzo, they click the Import Version button on the Versions tab for the model that is being imported.
Option to Overwrite Existing FLDS for Unstructured Pipelines
Version 4.4.0 adds an Overwrite Existing Corpus option in the Advanced settings for unstructured pipeline configurations. If you want Anzo to replace the existing FLDS when you run a pipeline, select the Overwrite Existing Corpus checkbox. When Overwrite Existing Corpus is enabled, Anzo archives the existing files in a new timestamped directory under the archives directory at the same level as the FLDS. The FLDS will contain only the data from the most recent run.
Option to Trust Elasticsearch Certificates
Version 4.4.0 adds the option to trust all Elasticsearch certificates when configuring a connection to an Elasticsearch instance.
Anzo Unstructured Worker Clients Default to SSL
In the previous Anzo version, Anzo Unstructured worker instances did not communicate with Anzo over SSL by default. In Version 4.4.0, worker clients communicate with the Anzo server over SSL by default.
Unstructured Pipeline Progress Errors Display More Information
In the previous Anzo version, the Progress screen showed limited information for errors that occurred while running unstructured pipelines. In Version 4.4.0, users have the option to view the stack trace for each error. For example:
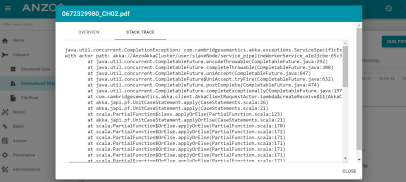
FLDS Crawler Processes Document Metadata
In Version 4.4.0, the Anzo Unstructured FLDS Crawler includes options that enable users to configure the crawler to process and store document metadata. After an FLDS Crawler is added to an unstructured pipeline, users can edit the crawler to specify the document metadata and metadata properties.
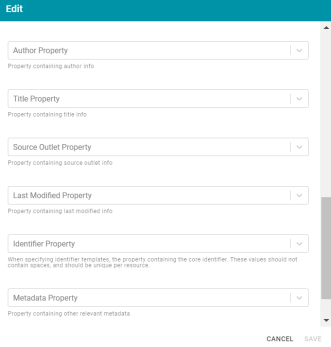
When editing the crawler, populate at least one of the document metadata fields with a datatype property: Author Property, Title Property, Source Outlet Property, or Last Modified Property. And populate the Metadata Property field with an additional datatype property.
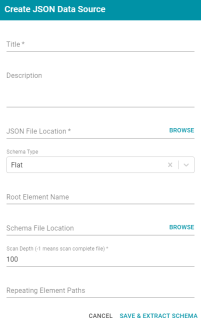
Specify Root Element Name for JSON Data Sources
In previous versions, when data was onboarded from a JSON data source with a relational schema, the root object was named "json" and could not be changed. Version 4.4.0 adds an optional Root Element Name field to the Create JSON Data Source screen so that users have the option to specify a name that can be used in place of "json" for the root element.
Option to Split Audit Log by Type
Version 4.4.0 introduces the option to create and store smaller audit logs by configuring Anzo to generate several logs in subdirectories that are sorted by event type, such as userEvents, queryEvents, accessEvents, etc. Follow the instructions below to configure this option:
- In the Anzo console, expand the Administration menu and click Advanced Configuration.
- Search for the Anzo Audit Logging Framework bundle and view its details.
- Click the Services tab and expand com.cambridgesemantics.anzo.AuditLog.
- Select the com.cambridgesemantics.anzo.auditlog.rdfLog property to enable the option.
- Make sure that the com.cambridgesemantics.anzo.auditlog.splitByType property is selected/enabled (it is enabled by default).
- Restart the server to apply the configuration change.
Once new audit events are triggered, the audit/audit-flds subdirectory is created in the <install_path>/Server/logs directory. And audit logs will be created in the userEvents, queryEvents, accessEvents, etc. subdirectories.
Connect Mappings by Base Class in ETL Job
In previous versions, users could connect mappings in an ETL job if the two mappings shared the same class, but they were unable to connect two mappings by base class. Version 4.4.0 enables users to connect mappings in an ETL job when one mapping includes a class that is a subclass of a class in the other mapping.
Option to Include or Exclude Rules in RDFS+ Inference Steps
Version 4.4.0 adds the option to customize the inference rules that are run in an RDFS+ Inference Step. For information, see Adding a Step that Generates RDFS-Plus Inferences in the Anzo Deployment and User Guide.
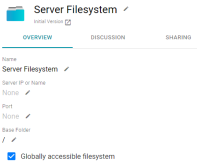
Server Filesystem Defaults to Globally Accessible
In Version 4.4.0, the default Server Filesystem connection is configured as a globally accessible filesystem.
Upgrade to Spark 2.4
In Version 4.4.0, the embedded Spark ETL engine was upgraded to version 2.4.
Option to Generate AnzoGraph Statistics after Loading Graphmart
In Version 4.4.0, when configuring the connection to an AnzoGraph instance, there is a Advanced option that enables users to choose whether to trigger AnzoGraph's internal statistics gathering queries immediately after loading a graphmart. For more information, see Configuring an AnzoGraph Connection in the Anzo Deployment and User Guide.
Updates to Existing Anzo Data Store are Applied
In previous versions, if a user modified the configuration of an existing Anzo Data Store, such as to deselect Compress output, Anzo continued to use the old settings when creating new file-based linked data sets (FLDS) in that data store. In Version 4.4.0 Anzo correctly applies Anzo Data Store configuration changes to new FLDSes.
Display Time Values Consistently for all Pipeline History Views
In previous versions, certain Pipeline History views displayed pipeline start and end times as the user's local time while others displayed the server time. In Version 4.4.0, Anzo displays the user's local time for all Pipeline History views.
Ensure URIs are Created when Template has NULL values
In previous versions, if a mapping used the URI template to concatenate values from multiple columns and create a URI, Anzo could incorrectly merge rows if one or more of the columns did not contain a value. For example, using the URI template urn://csi.com/person/LastName/FirstName for the following source data could result in two URIs instead of three because the rows for "Steve" were merged into a single URI:
| LastName | FirstName | EyeColor |
| Jones | Jerry | Brown |
| Steve | Blue | |
| Steve | Brown |
In Version 4.4.0, Anzo includes a GUID in place of missing values so that a unique URI is created for rows with missing values.
Anzo Version 4.3.6
This section describes the improvements and issues that were fixed in Anzo Version 4.3.6.
- Ensure Data on Demand uses Correct SKOS Ontology
- Apply OData $top, $skip and SQL LIMIT, OFFSET when Paging Enabled
- Parse OData Queries with Filters on Multi-Valued Properties
Ensure Data on Demand uses Correct SKOS Ontology
In previous versions, if an application accessed a Data on Demand endpoint for a graphmart that included a version of the SKOS ontology, the results failed to display all of the available classes. The Data on Demand schema was using the default Anzo SKOS ontology instead of the version of SKOS that was included in the graphmart. Version 4.3.6 resolves the issue to ensure that the Data on Demand schema uses the ontologies that are associated with the graphmart and data layers as well as any referenced ontologies.
Apply OData $top, $skip and SQL LIMIT, OFFSET when Paging Enabled
In previous versions, if client or server side paging was enabled and users queried Data on Demand endpoints via OData or JDBC, the $top and $skip OData parameters and LIMIT and OFFEST query options were ignored and all of the data was returned. Version 4.3.6 ensures that the OData and query options described above are considered when client or server side paging is enabled and the appropriate results are returned.
Parse OData Queries with Filters on Multi-Valued Properties
In previous versions, if the WHERE clause in an OData query included a filter on a multi-valued property (such as in the example below), Anzo was unable to parse the query due to the way it was translated by the JDBC driver.
SELECT a b FROM Gene_Value WHERE a = 'ALK'
Version 4.3.6 resolves the issue and enables Anzo to parse OData queries with filters on multi-valued properties.
Anzo Version 4.3.5
This section describes the improvements and issues that were fixed in Anzo Version 4.3.5.
Normalize Uppercase and Lowercase LDAP Names
In previous versions, duplicate user accounts were created in Anzo if an LDAP distinguished name had both a lowercase and uppercase version. Version 4.3.5 adds the option to configure the system to normalize distinguished name strings so that values that differ only in capitalization are treated as the same value.
To configure Anzo to normalize distinguished name strings:
- In the Anzo console, expand the Administration menu and click Advanced Configuration. Click I understand and accept the risk.
- Search for the Anzo OSGI Default System Configuration bundle and view its details.
- Click the Services tab and expand the Anzo OSGI Default System Configuration service.
- At the bottom of the list of properties, click Add Property. Anzo opens the Add Property dialog box.

- In the Name field, specify org.openanzo.security.ldap.normalizeDnStrings, and set the Value to true. Then click Save.
- Restart Anzo to apply the configuration changes.
After making the service configuration change and restarting Anzo, all of the existing LDAP users or roles must be removed and then added to Anzo again.
Anzo Version 4.3.4
This section describes the improvements and issues that were fixed in Anzo Version 4.3.4.
Improved Performance when Publishing ETL Jobs with Large Models
Version 4.3.4 improves performance when publishing ETL jobs with large data models.
Improved Performance for OData Queries with $expand Operator
Version 4.3.4 modifies the query generator for OData queries to improve performance for queries that include the $expand string operator.
Anzo Version 4.3.3
This section describes the improvements and issues that were fixed in Anzo Version 4.3.3.
Authentication Failed for SAML HTTP POST Binding Type
Version 4.3.0 introduces an authentication binding type property for SAML SSO provider configurations. The authentication binding type value was set to HTTP Redirect and could not be changed, causing authentication to fail for systems using HTTP POST binding. In Version 4.3.3, the authentication binding type property is configurable and supports HTTP POST binding.
To configure HTTP POST binding, modify the SAML configuration to add the following value for the <http://cambridgesemantics.com/ontologies/SSOProvider#authReqBinding> property:
"urn:oasis:names:tc:SAML:2.0:bindings:HTTP-POST"
Anzo Version 4.3.1
This section describes the improvements and issues that were fixed in Anzo Version 4.3.1.
Unable to Run ETL Steps for Individual Jobs
In Anzo Version 4.3.0, if a user tried to Generate, Compile, or Deploy an individual ETL job via the Publish Job dialog box (example shown below) or the Publish drop-down button, the user interface became blank and the user could not navigate back to the screen. In addition, the relevant ETL files for the chosen step were not created.
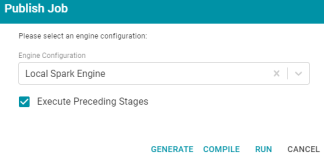
Version 4.3.1 fixes the issue and users are able to run each of the publishing steps for individual jobs.
Anzo Version 4.3.0
This section describes the improvements and issues that were fixed in Anzo Version 4.3.0.
Anzo Unstructured Improvements
- New Distributed Environment for Unstructured Data Processing
- New User Interface for Unstructured Pipelines
- PowerPoint Rich Text Extractor Change
User Interface Updates
- User Interface Reorganization
- Query Builder Improvements
- Progress Indicator for Exports and Versions
- Delete Roles from User Records in Bulk
- Option to Hide Auto-Generated Entities
- Anzo System Information Includes Memory Details
Onboarding, Graphmart, and Data Layer Improvements
- Guidance on Flat Versus Relational Schema Type for JSON and XML Imports
- Relationships Generated for JSON and XML Relational Schema Types
- Suggested Foreign Keys for Imported Files
- Inferred CSV Schema Types are Updated when Metrics are Generated
- New Options for Regenerating Artifacts in Auto-Ingest Workflow
- Ability to Leave Graphmarts Online During Refresh
- RDFS+ Inference Steps Generate Inferences for All Data Layers
- Updated JSON Driver
Export, Import, and Versioning Improvements
- Option to Change the Environment Version Variable
- Ability to Export Current Version of Entities
- Retain Related Environment Version ID in Exported Files
- Import Files from Any Supported File Connection
- Exported Table Lens Maintains Column Order
Additional Updates
- Additional Kerberos SSO Provider Properties
- Revised Permissions for Modifying Registries
- Increase Login Count Only for Requests from New User
- Updated SKOS to the Latest Version
- Updated Third Party Libraries
New Distributed Environment for Unstructured Data Processing
Version 4.3.0 overhauls Anzo's unstructured pipeline architecture and processing. The feature has been rewritten, simplified, and tailored to focus on key customer use cases. In addition, it has a new user interface that is incorporated into the Anzo console. Version 4.3.0 also introduces a distributed architecture, where a scalable cluster of unstructured worker nodes divide document processing to increase the performance of pipelines. This division of labor also makes it easier to isolate and identify problem documents without affecting the entire pipeline. In addition, Version 4.3.0 removes the embedded Elasticsearch version 2.4 server. Instead, Anzo is now compatible with later versions of Elasticsearch that are installed separately (7.1.1. is the preferred version). For more information, see Deploying the Anzo Unstructured Infrastructure in the Anzo Deployment and User Guide.
Important: Any existing Anzo Unstructured pipelines are incompatible with the new infrastructure and will not work after upgrading to Anzo 4.3.0. Cambridge Semantics Support will assist you with re-creating your unstructured pipelines after the upgrade.
New User Interface for Unstructured Pipelines
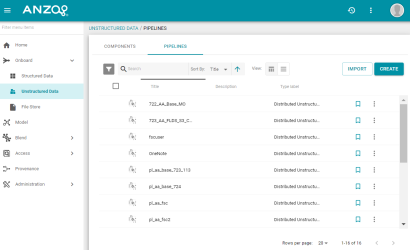
Version 4.3.0 introduces a new and improved user interface for creating and managing unstructured data pipelines. From the new Unstructured Data menu item under Onboard:
- Users can create and view unstructured pipelines.
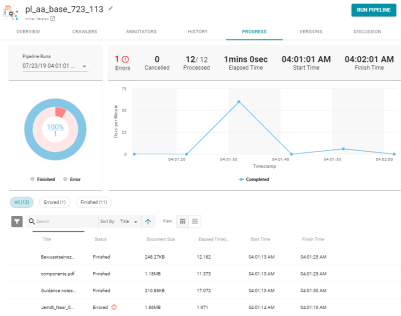
- Users can view history and progress details. For example:
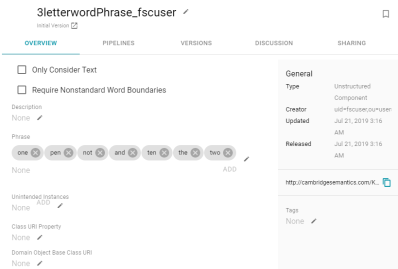
-
And users can view and configure components. For example:
For more information about the new user interface and creating unstructured pipelines, see Onboarding Unstructured Data in the Anzo Deployment and User Guide.
PowerPoint Rich Text Extractor Change
In Version 4.3.0, Anzo Unstructured (AU) pipelines are not configured to include the PowerPoint Rich Text Extractor by default. If you want AU to render Microsoft PowerPoint content in HTML, add the PowerPoint Rich Text Extractor to the unstructured pipeline. When the extractor is not included, AU will process the PPT data and the content will be displayed as text. Including the extractor renders the content in HTML.
To add the extractor:
- View the pipeline overview in the Anzo console, and click Advanced to display the advanced settings. For example:
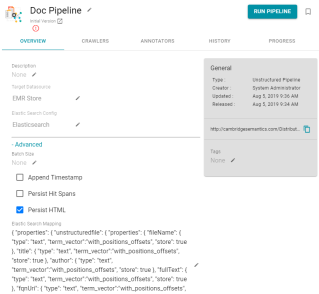
- Scroll down to the Rich Text Extractor setting, and click the Edit icon (
 ) to edit the field. For example:
) to edit the field. For example: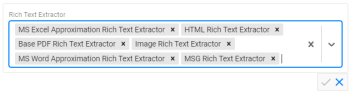
- Click the down arrow on the right side of the field to open the Rich Text Extractor drop-down list.
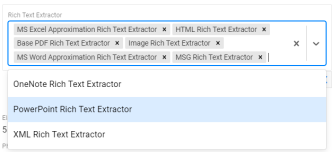
- Select PowerPoint Rich Text Extractor to add it to the Rich Text Extractor field. Then click the check mark icon (
 ) to save the change.
) to save the change.
User Interface Reorganization
Because the Unstructured Data pipeline manager is now incorporated into the Anzo application interface, Version 4.3.0 moves and renames some of the menu items in the Anzo user interface. The list below describes the changes:
- The Onboard menu is reorganized to group the previously existing Data Sources, Data Source Metadata (now named Schemas), Mappings, and Pipelines menu items. These components are now accessed via tabs in the new Structured Data menu item under Onboard.
- The Onboard menu now includes the new Unstructured Data menu item.
- Users used to create and manage graph data sources from Data Sources in the Onboard menu. This functionality was renamed Anzo Data Store and is moved to the Administration menu.
- File System Locations is renamed to File Store.
- The Administration menu now includes the Elasticsearch Config screen for configuring a connection to an Elasticsearch instance. For more information, see Configuring an Elasticsearch Connection in the Anzo Deployment and User Guide.
Query Builder Improvements
Version 4.3.0 adds the following Query Builder improvements:
- The syntax assistance has been improved to include type-ahead suggestions when typing entity names from a model. For example:
- The Query Builder now reports the number of results and the query execution time. For example:
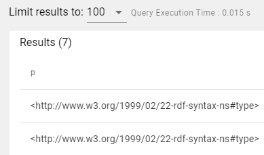
Progress Indicator for Exports and Versions
Version 4.3.0 adds progress indicators to the user interface so that users can view the progress when files are exported or when archive versions are created.
Delete Roles from User Records in Bulk
Version 4.3.0 introduces the ability to delete all system roles from a user record. The Edit User screen now includes a delete icon (X) on the right side of the Roles field. Clicking the X removes all of the roles from the field. For example:

Option to Hide Auto-Generated Entities
Version 4.3.0 introduces the option to quickly hide entities that were automatically generated as part of the auto-ingest process. When viewing a list of the existing schemas, mappings, and pipelines, users have the option to select the new Hide auto generated data setting under Filters. For example:
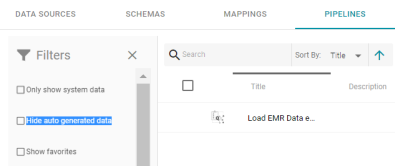
Selecting the Hide auto generated data option removes auto-generated entities from the list in the main part of the screen.
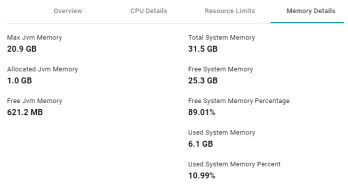
Anzo System Information Includes Memory Details
In Version 4.3.0 the System Information screen includes a Memory Details tab that provides information about Anzo server memory usage. For example:
Guidance on Flat Versus Relational Schema Type for JSON and XML Imports
In Version 4.3.0 Anzo performs a pre-processing step before creating the schema for JSON or XML import files. If the Schema Type that is specified for the source would result in poor performance or require extensive resources, Anzo displays a warning and prompts the user to change the type before proceeding with the schema creation. The image below shows an example of the new warning message:

For more information about onboarding data from JSON and XML files, see Importing Data from JSON Files and Importing Data from XML Files in the Anzo Deployment and User Guide.
Relationships Generated for JSON and XML Relational Schema Types
In Version 4.3.0, when the Relational schema type is chosen for data that is imported from JSON or XML files, Anzo now creates the relationships. In relational mode, the relationships go from the child node to the parent node.
Suggested Foreign Keys for Imported Files
In Version 4.3.0, Anzo provides a list of suggested foreign keys when metrics are generated for CSV, JSON, and XML data sources. After generating metrics for a data source, users can view the foreign key suggestions from the new Suggested Keys tab that is available when viewing the foreign keys for a schema. For example:
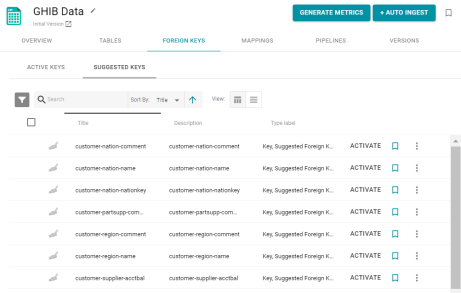
To apply a foreign key, click Activate in the row for the key that you want to apply. When Anzo creates suggested keys between tables, the table that has the relevant column listed first becomes the target table and that column becomes the primary key. The column becomes the foreign key in the second table, the child table. Users can edit suggested foreign keys before or after activating them. If a user activates a suggested key for which a primary key was already defined, Anzo displays a warning and does not activate the new key.
Inferred CSV Schema Types are Updated when Metrics are Generated
To help improve accuracy of inferred data type assignment for CSV data sources, Anzo Version 4.3.0 now automatically updates any mismatched types when metrics are generated for the data source. Unlike the initial import when Anzo scans a sample of the file before inferring data types, Anzo reads the entire file when generating metrics. Once metrics are generated, Anzo can double-check and accurately assign each data type. For information about generating metrics, see Generating Data Quality Metrics for a Data Source in the Anzo Deployment and User Guide.
New Options for Regenerating Artifacts in Auto-Ingest Workflow
Anzo Version 4.2.0 introduced the ability to reuse an existing model when auto-ingesting data. In that version, users could either choose to "Regenerate all Artifacts" or not. In Version 4.3.0, users have more control over which, if any, artifacts are regenerated. The advanced settings in the auto-ingest workflow now include options to Regenerate Entire Model and Regenerate Mappings and Jobs:
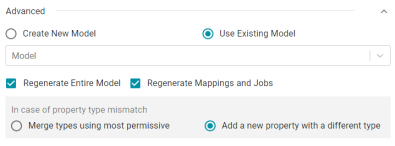
For more information about the auto-ingest workflow and advanced options, see Auto-Ingesting Data in the Anzo Deployment and User Guide.
Ability to Leave Graphmarts Online During Refresh
Version 4.3.0 includes a new graphmart setting that enables users to specify whether to leave a graphmart and its data layers online while that graphmart is being refreshed in AnzoGraph. The Overview screen for each graphmart displays a Leave Graphmart Online During Refresh setting.
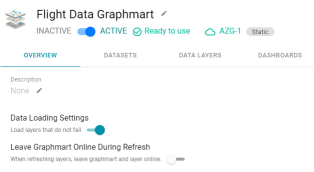
When Leave Graphmart Online During Refresh enabled, Anzo copies the graphmart and data layers into temporary graphs so that the data remains online while the original graphmart is refreshed. When the refresh is complete, the temporary graphs are deleted.
RDFS+ Inference Steps Generate Inferences for All Data Layers
In previous Anzo versions, RDFS+ Inference Steps generated inferences only for the data that was contained in the data layer that included the Inference step. Users could not configure an inference layer that ran against the union of all of the data that was generated by all of the previous data layers. In Version 4.3.0, RDFS+ Inferencing steps can be configured to generate inferences for any combination of the data layers in the graphmart.
Updated JSON Driver
Version 4.3.0 upgrades the JSON driver to improve performance and add stability.
Option to Change the Environment Version Variable
Version 4.3.0 adds a Versioning Environment server setting that enables an administrator to change the variable value for the environment tag that is added to archived versions of entities. For more information, see Changing the Variable for Environment Version IDs in the Anzo Deployment and User Guide.
Ability to Export Current Version of Entities
Previously, Anzo artifacts could only be exported from archived versions of the artifact. In Version 4.3.0, the current version of an artifact can be exported in addition to any archived versions. To export the current version of an artifact from the Anzo console, click the Export icon (![]() ) under the artifact name at the top of the screen. For example:
) under the artifact name at the top of the screen. For example:
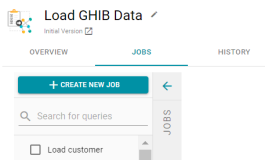
Retain Related Environment Version ID in Exported Files
In Version 4.3.0, when an archived version of an artifact is exported, the export includes the related environment version ID for the artifact. If the exported version is imported into a different environment, Anzo will now display the version information for both environments so that users can see the lineage of versions across different systems.
Import Files from Any Supported File Connection
In previous Anzo versions, zip files that contained previously exported files could only be imported from the local file system. In Version 4.3.0, Anzo supports importing exported files from each of the supported file connections.
Exported Table Lens Maintains Column Order
In previous Anzo versions, when a table lens was exported to CSV from a Hi-Res Analytics dashboard, the resulting CSV file did not maintain the order of the columns if the order had been changed in the lens. In Version 4.3.0, the order of the columns is maintained when a table lens is exported.
Additional Kerberos SSO Provider Properties
Version 4.3.0 introduces two new Kerberos properties to the SSO Provider registry: IndirectKerberosSSOProvider and LoginCapable. If you upgrade to Anzo Version 4.3.0 and have an existing Kerberos instance configured, add the following statements to the graph that contains the <URI> rdf:type <http://cambridgesemantics.com/ontologies/SSOProvider#KerberosSSOProvider> statement:
<URI> rdf:type <http://cambridgesemantics.com/ontologies/SSOProvider#IndirectKerberosSSOProvider> <URI> rdf:type <http://cambridgesemantics.com/ontologies/SSOProvider#LoginCapable>
Revised Permissions for Modifying Registries
In previous Anzo versions, all users could remove entities from registries. In Version 4.3.0, only the Anzo Administrator user role can remove from registries entities that they did not create. This change does not affect the actual entities or their data; it only affects how the entities are registered in the system.
Increase Login Count Only for Requests from New User
In previous versions, Anzo increased the login count each time an Anzo endpoint request was made using browser-based basic authentication or access tokens such as JSON web tokens. In Version 4.3.0, Anzo increases the login count once when a new user makes a request. Subsequent requests to the endpoint from the same user do not increase the count.
In addition, 4.3.0 changes the authentication behavior when anonymous access is enabled. If anonymous access is enabled and a user's credentials fail the SSO provider authentication, Anzo displays an error and rejects the request.
Updated SKOS to the Latest Version
Version 4.3.0 updates the SKOS vocabulary to the latest W3C specifications. In addition, the SKOS model is no longer a system ontology. The model is available to select in the Model Working Set.
Updated Third Party Libraries
In Version 4.3.0, third party libraries are updated to ensure compatibility with Java 11.
Anzo Version 4.2.12
This section describes the improvements and issues that were fixed in Anzo Version 4.2.12.
Optimize AnzoGraph Status Checks
Occasionally, Anzo and AnzoGraph could disconnect when AnzoGraph memory usage was high. The issue occurred because Anzo was periodically checking AnzoGraph's status. In a low-memory situation, AnzoGraph's system manager could fail to authenticate, which made AnzoGraph appear offline to Anzo. To complement the changes to AnzoGraph to resolve the issue, Anzo Version 4.2.12 streamlines the AnzoGraph status checks to reuse authorization keys and reduce the number of system management requests.
Anzo Unresponsive after Concurrent OData Queries on Large Data Sets
Anzo became unresponsive after several concurrent OData queries were run against large data sets. The issue occurred because Anzo encountered serialization errors when writing results back to the OData client. Instead of canceling the queries, Anzo continued to process the solutions, which used a large amount of system resources until Anzo was eventually restarted. Version 4.2.12 resolves the issue by optimizing the serialization of OData results and making sure that queries are canceled when serialization errors occur.
Anzo Version 4.2.11
This section describes the improvements and issues that were fixed in Anzo Version 4.2.11.
- Improved Performance for OData Queries with $expand Operator
- Added Anzo System Monitor Service
- Option to Whitelist File Types in File Based Dataset Crawler
Improved Performance for OData Queries with $expand Operator
Version 4.2.11 modifies the query generator for OData queries to improve performance for queries that include the $expand operator.
Added Anzo System Monitor Service
To aid in monitoring the state of the Java virtual machine (JVM), Version 4.2.11 adds the Anzo System Monitoring service. This service can be configured to poll the state of the JVM. If the configured thresholds are reached, thread and heap dumps are written to disk automatically and repeatedly, depending on the configured interval.
Option to Whitelist File Types in File Based Dataset Crawler
In previous versions, the File Based Dataset crawler could be configured to exclude certain file types, such as .zip or other compressed files. However, the list of file types to ignore could get extensive, and users could not specify a minimal list of file types to include instead. Version 4.2.11 adds the option to whitelist file types. Instead of configuring the crawler to exclude a long list of types, users can specify the file types to include.
Anzo Version 4.2.0
This section describes the improvements and issues that were fixed in Anzo Version 4.2.0.
General User Interface Improvements
- Reorganized and Renamed Navigation Menu Items
- Redesigned Resource Selection Screens
- Query Playground Improvements and New Name
- Renamed System Role and Permission Categories
Data Source and Data Onboarding Changes
- XML Data Source Support
- Create a New Data Set from External Files
- Option to Import Multiple Files with the Same Schema as One File
- Reuse an Existing Model when Auto-Ingesting Data
- Option to Scan Larger Percentage of CSV Files Before Inferring Data Types
- Display Size of Imported CSV Files
- Save Inferred CSV Delimiter Values
- Invalid Schema Queries are Saved for Editing
- Users with Access Can Run Jobs that Include Data Sources Imported from Computer
- CData Type Statement Added to JSON Data Sources
Spark and Pipeline Improvements
- Job Creation and Publishing Improvements
- Local Spark Engine Runs Multi-Threaded by Default
- Job Title Required When Creating New Pipeline
- Avoid Spaces in Hive Target Table and Column Names
Graphmarts, Data Layers, and Data-on-Demand Improvements
- Customize Entity Name Values for Data-on-Demand Endpoints
- Preview Templated Step Queries
- Display Elapsed Load Time on Graphmarts Screen
- Option to Hide Simple Load Data Layers
- Statement and Instance Counts Not Displayed Until Final
- Ability to Delete Existing Data Layer Steps and Views
Hi-Res Analytics Improvements
Management of Existing Artifacts
- Ability to Export any Artifact and its Related Entities
- Option to Replace Values During Entity Export
- Import Entities via the User Interface
- Error Displayed when Deleting a Component with Related Entities
- Component Names Show Version They Are Derived From
Preservation of Custom Configurations after Anzo Restart or Upgrade
- Custom Database Types Preserved after Anzo Upgrade
- Spark Configuration Changes Preserved after Anzo Upgrade
- Changes to Script Environment Configuration Preserved after Anzo Restart
Mapping Tool Improvements
System Administration Changes
Reorganized and Renamed Navigation Menu Items
Version 4.2.0 re-orders and renames some of the menu items in the Anzo user interface. The list below describes the changes:
- The Ingestion menu is now Onboard.
- The Datasets screen under the Onboard menu, which lists data sets or schemas is now Data Source Metadata.
- Catalog is now Datasets and is moved under the new Blend menu.
- Graphmarts is now under the new Blend menu.
- Data Models is now Model.
- Hi-Res Analytics is now under the new Access menu.
- Query Playground is now Query Builder and is moved from the Administration menu to the Access menu.
- Activity Log no longer appears in the navigation menu. To view the Activity Log, click the clock icon (
 ) on the top right of the screen in the main title bar.
) on the top right of the screen in the main title bar.
Redesigned Resource Selection Screens
Version 4.2.0 redesigns the screens from which users select the resource or component that they want to view details about. As shown in the image below, the Search and Sort functionality is at the top of the screen:

Clicking the Filter button ( ) opens the filter options on the left side of the screen. In addition, Version 4.2.0 adds View options that enable users to choose from a Table View (
) opens the filter options on the left side of the screen. In addition, Version 4.2.0 adds View options that enable users to choose from a Table View ( ), List View (
), List View ( ), or Graph View (
), or Graph View ( ) of the list of resources. The view and sorting that a user sets on one list screen remains the same for the other screens.
) of the list of resources. The view and sorting that a user sets on one list screen remains the same for the other screens.
Note: The Graph View option is not available on all screens. It is shown when the view is relevant, such as on the Model Working Set screen. For example:
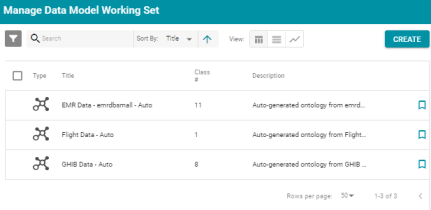
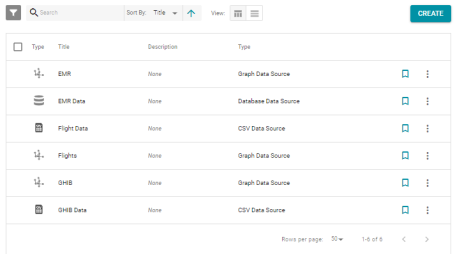
The Graph View is not available on the Data Sources screen. For example:
Query Playground Improvements and New Name
Version 4.2.0 changes the name of the Query Playground to Query Builder and moves the Query Builder out of the Administration menu so that it is accessible to non-admin users. Query Builder is now under the Access menu and provides the following new features:
- Syntax assistance to alert users to syntax errors.
- A Format Query option that spaces the query for readability and automatically adds prefixes to abbreviate URIs.
- The option to select a graphmart or specific data layer to target.
- The ability to save queries for later use.
Renamed System Role and Permission Categories
Version 4.2.0 renames some of the default system roles and permission categories to align them with the navigation menu changes:
- In the Permissions table, the category Smart Data Lake is now Anzo Application.
- The Data Lake Administrator system role is now Anzo Administrator.
XML Data Source Support
Version 4.2.0 adds support for ingesting data from XML files. For information, see Importing Data from XML Files in the Anzo Deployment and User Guide.
Create a New Data Set from External Files
Version 4.2.0 introduces the option to import data from an external file-based linked data set (FLDS) or from TTL or TTL.GZ files directly into the onboarded dataset catalog as a new FLDS. For more information and instructions, see Importing Data from External Files in the Anzo Deployment and User Guide.
Option to Import Multiple Files with the Same Schema as One File
Version 4.2.0 introduces the option to import multiple CSV, JSON, or XML files with the same schema by specifying a wildcard character to match multiple file names. Anzo treats the selected files as one file on import. For example, when the data is auto-ingested, Anzo produces a single mapping and pipeline job for the data in the files instead of creating a mapping and job for each file.
To specify multiple files with a wildcard, select the new Insert Wildcard option on the Select import files screen. The option is available when importing files from the file system. It is not available when importing files from your computer. For example:
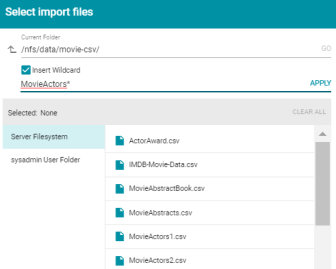
The files must follow the same schema, i.e., contain the same columns listed in the same order. If any of the files use a different schema, the import fails.
Reuse an Existing Model when Auto-Ingesting Data
Version 4.2.0 adds the option to choose an existing model to associate with new data that is being auto-ingested. In Version 4.2.0 the Auto Ingest screen includes Advanced options that enable users to specify whether they want Anzo to generate a new model or whether they want to use an existing one. For example:
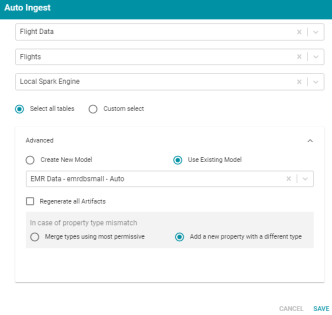
When Use Existing Model is selected, users choose the model to use from a drop-down list. In addition, the following options for controlling the data become available:
- Regenerate all Artifacts: This option is relevant for a data set that has previously been auto-ingested and has existing artifacts. When Regenerate all Artifacts is selected, all entities from the previous ingestion process are deleted. The artifacts that result from the current ingestion process, such as the model, mappings, and jobs will contain only the data from the current process.
Example: If a previous run generated a model, mapping, and job that contained Table A and the current run is ingesting Table B, selecting Regenerate all Artifacts results in artifacts that contain only Table B. If Regenerate all Artifacts is not selected, the resulting artifacts contain Table A and Table B.
- In case of property type mismatch: The property type mismatch options specify how Anzo handles data type mismatches between the existing model and the new schema:
- Merge types using most permissive: Anzo looks at the inferred types in both schemas and chooses the type that covers all inputs. In most cases Anzo sets the type to String.
- Add a new property with a different type: If Anzo encounters a type mismatch, it adds a new property with the new type to the existing model.
When associating column names in the new schema with the existing model, the match is case-insensitive. Anzo matches the names based on the spelling. For example, "myInt" matches "MYint."
Option to Scan Larger Percentage of CSV Files Before Inferring Data Types
To help improve accuracy of data type assignment when importing CSV files, Anzo Version 4.2.0 provides an option to scan a larger percentage of the files before inferring the data types for each column. The new Use Extended Sample option is on the Edit CSV File screen that is accessible after you select files to import. For example:
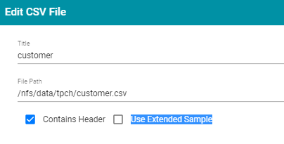
Choosing to use an extended sample before inferring data types increases the time it takes to import the data.
Display Size of Imported CSV Files
Version 4.2.0 adds a Size column to the Files tab on the CSV Data Sources screen. The Size column displays the file size for each imported CSV file. For example:
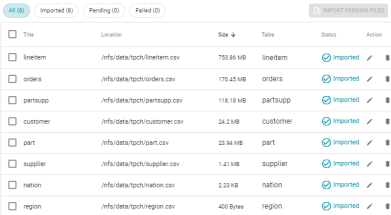
Save Inferred CSV Delimiter Values
In previous Anzo versions, when users did not specify the delimiter used in CSV files Anzo inferred the value. However the inferred delimiter was not saved for future imports. In Version 4.2.0, Anzo saves the inferred delimiter values.
Invalid Schema Queries are Saved for Editing
In previous Anzo versions, if a user attempted to save an invalid schema query for a database data source, Anzo displayed an error message and discarded the invalid query. In Version 4.2.0, Anzo saves the invalid schema query so that a user can modify the query to correct it.
Users with Access Can Run Jobs that Include Data Sources Imported from Computer
In previous versions, if one user imported a CSV or JSON file to Anzo from their local computer, other users who had access to that data source could not run a job that included the source. In Version 4.2.0, if a user uploads a CSV, JSON, or XML file from their computer, users who have access to that data source are able to run jobs that include the source.
CData Type Statement Added to JSON Data Sources
In Version 4.2.0 Anzo automatically adds the following type statement to JSON data sources:
<http://cambridgesemantics.com/ontologies/DataSources#CDataSource>
Anzo updates any existing JSON sources during the upgrade; no action is required by users.
Job Creation and Publishing Improvements
Version 4.2.0 introduces the following changes to improve job creation and publishing functionality:
- Redesigned the Jobs screen and so that the jobs pane remains visible and can be collapsed if needed. For example:
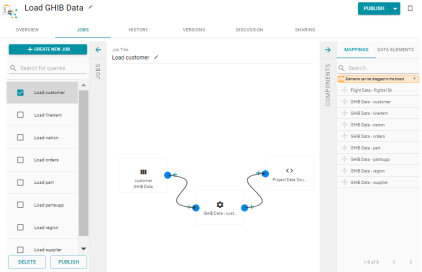
- The jobs list now includes checkboxes so that any combination of jobs can be selected for publishing.
- If a user drags a mapping onto the job canvas and there is only one source and one target for the mapping, Anzo automatically adds that source and target to the job.
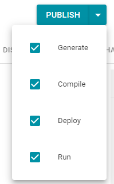
- The Publish button includes a drop-down list of the steps that will run when Publish is clicked. Users can specify when steps to run by selecting or deselecting checkboxes. All steps are selected by default and, like previous Anzo versions, clicking Publish runs all of the jobs in the pipeline.
Local Spark Engine Runs Multi-Threaded by Default
In previous Anzo versions, the local Spark engine ran single-threaded and required configuration to run multi-threaded. In Version 4.2.0, the local Spark engine is multi-threaded by default.
Job Title Required When Creating New Pipeline
Previous Anzo versions did not enable users to enter a job name when they created a new pipeline. Users had to edit the default job title after creating the pipeline. Version 4.2.0 adds a Job Title field to the Create Pipeline screen (shown below) so that users can name the default job before the pipeline is created.
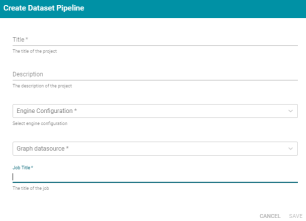
Avoid Spaces in Hive Target Table and Column Names
In Version 4.2.0, spaces in rdfs:label values are replaced with underscores when Hive is defined as the target. Previously, when rdfs:label values contained spaces, issues arose with Parquet because the Hive table and column names included spaces.
Customize Entity Name Values for Data-on-Demand Endpoints
In previous Anzo versions, users could not control the entity display names that were used in the OData schema for data-on-demand endpoints; all entities were displayed using their URI local name. Version 4.2.0 introduces the option to configure a data-on-demand endpoint to display class and property names using a predicate value that you specify, such as the rdfs:label or dc:description for the entity.
The new options are available when viewing the endpoint details on the Data on Demand screen. For example:
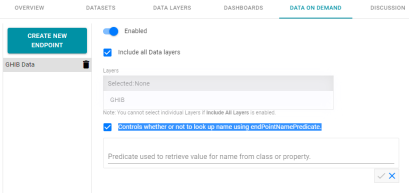
When the Controls whether or not to look up name using endPointNamePredicate option is enabled Anzo uses the predicate value in the Predicate used to retrieve value for name from class or property field to obtain the name to use for the entities. Specify a predicate from the related data model, such as http://www.w3.org/2000/01/rdf-schema#label to use each entity's Label value or http://purl.org/dc/elements/1.1/description to use each entity's Description value.
If the Controls whether or not to look up name using endPointNamePredicate option is disabled, Anzo displays each entity's local name. If the Controls whether or not to look up name using endPointNamePredicate option is enabled but the Predicate used to retrieve value for name from class or property field is empty, Anzo automatically uses the value in the rdfs:label (http://www.w3.org/2000/01/rdf-schema#label) predicate.
Preview Templated Step Queries
Version 4.2.0 adds the option to view a preview of the template query in a Templated Step. The preview shows a version of the query where each of the keys are substituted with their specified value from the key/value table.
Display Elapsed Load Time on Graphmarts Screen
To provide additional feedback about a graphmart's load time while the graphmart is activating, Version 4.2.0 displays the elapsed load time above the status bar on the Graphmart screen. For example:

Option to Hide Simple Load Data Layers
To help streamline the management of data layers and simplify the Data Layers screen, Version 4.2.0 introduces the ability to hide data layers that only contain steps that simply load data sets without filtering the data. The Data Layers screen now includes the option to Hide simple load layers. For example:
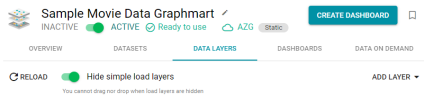
If a layer contains a Load Step that includes a Multiple Select or Query filter, the layer will not be hidden when the "Hide simple load layers" option is enabled. Also, if the layer includes other types of steps in addition to Load Steps, the layer will not be hidden when the "Hide simple load layers" option is enabled.
Statement and Instance Counts Not Displayed Until Final
To avoid confusion when viewing the Statement Count and Instance Count statistics that are displayed on the Graphmart and Dataset Overview screens, Version 4.2.0 delays displaying those statistics until the counts are deduplicated and stable.
Ability to Delete Existing Data Layer Steps and Views
In Version 4.2.0, the Add Step/View dialog box provides an option to delete existing steps or views. For example:
![]()
When deleting an existing step or view, Anzo does not provide a warning if a data layer is using the step. Before removing an existing step, make sure that the step is not in use.
Redesigned Unstructured Document Search Lens
Version 4.2.0 redesigns the Document Search Results lens to make the following improvements:
- The lens initially displays the list of documents without requiring a search. For example:
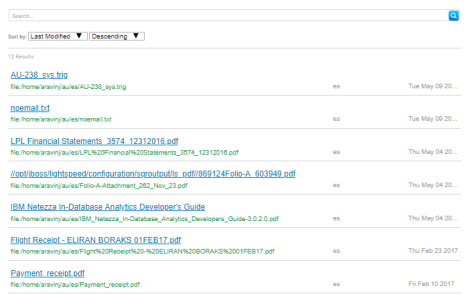
- The search results now affect other facets on the dashboard.
- There is a clearer representation of search hits in the search results with links between the hit and the location of the text in the document. Users do not need to open a document to view the context of a result. For example:
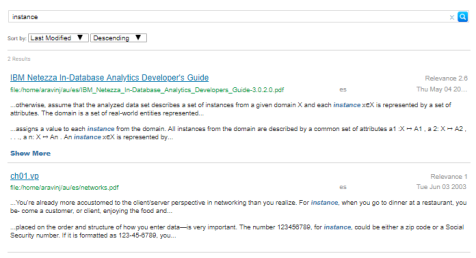
- Additional search functionality is available in the lens.
- The Elasticsearch relevance score is displayed in the search results, and users can sort results by relevance.
Ability to Export any Artifact and its Related Entities
Version 4.2.0 introduces new functionality to standardize the process for exporting different artifacts (schemas, pipelines, mappings, models, etc.) and provide the ability to easily export any of an artifact's related entities.
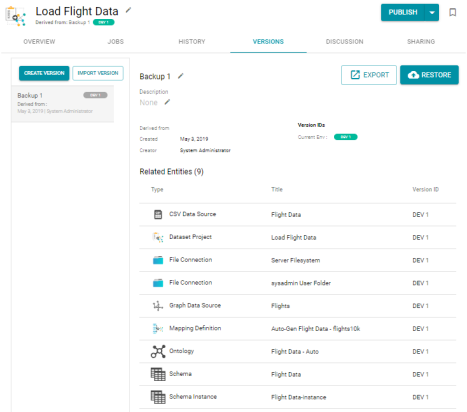
In Version 4.2.0, you export an entity from a backup version of the artifact. For information about viewing or creating backup versions, see Backing Up and Restoring Artifacts in the Anzo Deployment and User Guide.
To export an artifact from a backup version, go to the Versions tab for the component to export and view the version that you want to export from. For example, the image below shows the details for a backup version for a pipeline:
Clicking Export opens the Export screen and enables users to select the entities or entity to export. For example:
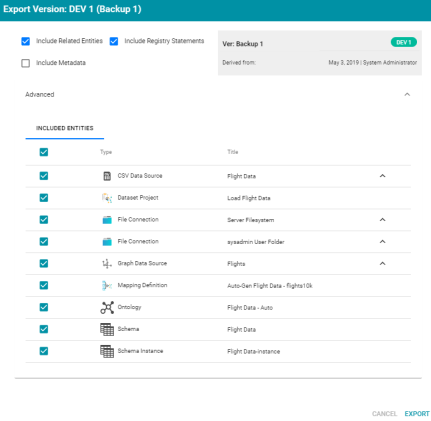
For more information about exporting entities, see Exporting Artifacts in the Anzo Deployment and User Guide.
Known Limitation
The data source definitions for JSON and XML data sources cannot be exported at this time. Other artifacts, such as mappings and pipelines, for JSON and XML data sources can be exported. However, they cannot be re-imported without the data source definition.
Option to Replace Values During Entity Export
Version 4.2.0 adds the option to replace the existing values for certain properties when you are exporting a version of an entity. By default, Anzo is configured to enable the replacement of values such as the user name and password for database data source exports, the base folder location for file connections, and the file path for graph data sources. In addition, users have the option to configure additional values as replaceable on export.
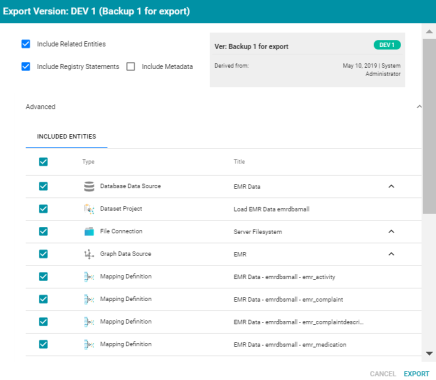
To replace values on export:
- Expand the Advanced options on the Export screen so that the Included Entities are displayed. For example:
- The entities with replaceable values are expandable. Click the ^ character to the right of an entity name to expand the options and view the replaceable values. For example:
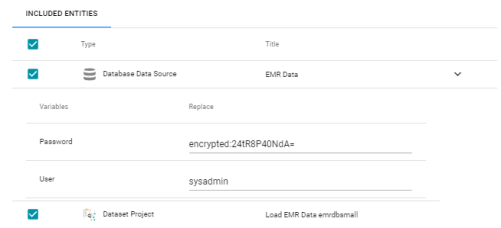
- Replace the existing values with the new values that you want to define for the exported version of the entity.
To configure additional properties so their values can be replaced on export:
To configure a property so that its value is replaceable on export, add the following statement to the http://cambridgesemantics.com/annotations/replaceStatements graph:
class_URI http://cambridgesemantics.com/ontologies/2018/06/Export#replaceStatement property_URI
Where class_URI is the URI for the class that defines the property whose value should be replaceable. And property_URI is the URI of the property.
The specified property must be a Datatype property that contains a literal value.
For reference, the following TriG file is used to define the default properties with replaceable values:
@prefix ds: <http://cambridgesemantics.com/ontologies/DataSources#> .
@prefix exp: <http://cambridgesemantics.com/ontologies/2018/06/Export#> .
@prefix ann: <http://cambridgesemantics.com/annotations/> .
#Mode:ADD
ann:replaceStatements {
ds:PathConnection exp:replaceStatement ds:filePath .
ds:FileConnection exp:replaceStatement ds:fileConnectionBaseFolder .
ds:DbDataSource exp:replaceStatement ds:dbUser , ds:dbDatabase, ds:dbPassword .
}
Import Entities via the User Interface
To complement the new entity export process, Version 4.2.0 adds the option to import the exported versions of entities using the Anzo user interface. The resource selection screens, such as the Pipelines, Mappings, and Data Sources screens now include an Import button. For example:
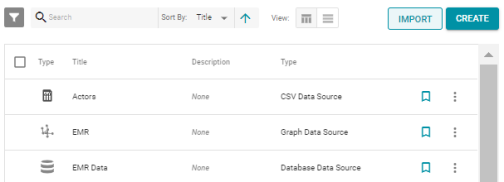
Clicking Import enables user to select and import the .zip files that contain entity export files. For more information, see Importing Exported Artifacts in the Anzo Deployment and User Guide.
Error Displayed when Deleting a Component with Related Entities
Version 4.2.0 adds an error message to help ensure that users do not accidentally invalidate components by deleting a related entity. If a user attempts to delete a component, such as a data source or mapping, and the component has related entities, Anzo displays a detailed error message that shows the specifics about the impact of deleting the selected component. For example:
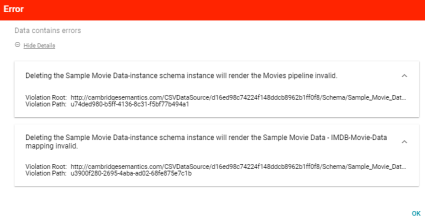
When the user clicks OK, the deletion is canceled, and the component cannot be deleted until the references to the entities in the error message are removed or the entities are deleted.
Component Names Show Version They Are Derived From
In Version 4.2.0, when viewing a component (such as a mapping, pipeline, or model) that has one or more backup versions, the version of the component is displayed under the component name. For example, the sample mapping below shows that it is derived from "Backup 1."
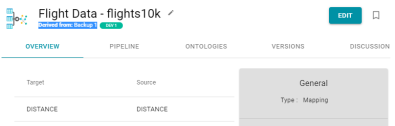
Custom Database Types Preserved after Anzo Upgrade
In Version 4.2.0, custom database type definitions are stored in a new registry that does not get replaced during the upgrade process.
Spark Configuration Changes Preserved after Anzo Upgrade
When upgrading previous Anzo versions, the Spark configuration file, /opt/Anzo/Server/spark/spark-2.2.0-bin-hadoop2.7/conf/spark-defaults.conf, was overwritten and any customizations were lost. Version 4.2.0 now preserves changes to spark-defaults.conf; the file is not overwritten when Anzo is upgraded.
Changes to Script Environment Configuration Preserved after Anzo Restart
In previous versions, the /opt/Anzo/Server/data/sdiScripts/scriptEnvConfig file was overwritten when Anzo was restarted. Any changes to the file were discarded. In Version 4.2.0, Anzo preserves changes to scriptEnvConfig. The file is not overwritten when Anzo is restarted.
Include Empty Strings
In Version 4.2.0, users can now specify empty strings in the Source text box by including double quotation marks ("").
URI Function
In Version 4.2.0, the URI function is available to use in the Source column to convert source values to URIs.
View System Query Audit Information
Version 4.2.0 introduces the System Query Audit tool for system administrators. Under the Administration menu, the new System Query Audit screen enables users to quickly view a log of query events, any query errors, the duration time for the longest running queries, and a list of any queries that have been blacklisted. For example:

Ability to Delete Subset of System Roles
Version 4.2.0 introduces the ability to delete system roles in bulk. The redesigned System Roles screen enables a system administrator to select multiple roles at once and then delete the subset. For example:
Anzo Version 4.1.0
This section describes the improvements and issues that were fixed in Anzo Version 4.1.0.
New Features
- Create and Restore Versions of Components
- Progress Details for Hi-Res Analytics
- Clone Lenses in Hi-Res Analytics
- Data on Demand Endpoints for Individual Data Layers
- ODBC and JDBC Service URLs for Data on Demand Endpoints
- (Beta Release) Save a Table Lens as Data Layer View
- Data Layer Validation Step
- Query Playground for Administrators
- Catalog Data Sets Inherit Pipeline Permissions
- Hi-Res Analytics Associated with Catalog Items
- AnzoGraph Administration Options and Health Overview
- OneNote Extractor for Unstructured Pipelines
- Listeners Notified for Data Layer (RBLDS) Query Execution
- "ls" Command Line Option to List Registry Resources
Changes to Existing Features
- Changes to Data on Demand Endpoint URLs
- Option to Upgrade Legacy Graphmarts Moved to Admin Client
- Data Layer Usability Enhancements
- Keys Automatically Added to Key/Value Table for Template Steps
- Auto-Ingest Populates Data and Graph Source Names
Create and Restore Versions of Components
Version 4.1.0 introduces the ability to create, save, and restore backup versions of the components that make up each solution. Before making changes to data sources, schemas, mappings, pipelines, or data models, users can take a snapshot of the current version of that component. The changed files can then be reverted at any time to any of the saved versions. If a user saves a version of a component, Anzo automatically creates a version of each entity that is related to that component. If a component is restored to a previous version, Anzo automatically saves a version of the current state of the component and its related entities.
Users view, create, and restore versions from the new Versions tab that is available for Data Sources, Datasets, Mappings, and Pipelines. The tab displays a list of existing versions, statistics about each version, and details about related entities. For example:
For more information, see Backing Up and Restoring Solution Components in the Anzo Deployment and User Guide.
Progress Details for Hi-Res Analytics
In Version 4.1.0, the Hi-Res Analytics application now displays detailed progress information while processing the data to display in dashboards. When dashboard components are loading, Anzo now displays the percent completed in the progress circle as well as specific details about the AnzoGraph query steps at the bottom of the browser window and as a tip if you hover the pointer over the progress circle. For example:

Clone Lenses in Hi-Res Analytics
Version 4.1.0 introduces the option to clone existing lenses in Hi-Res Analytics dashboards. In previous Anzo versions, users could open an existing lens in multiple dashboards, but the dashboards shared the same version of the lens. In Version 4.1.0, cloning a lens makes a copy of the lens that can be changed without affecting the original lens or other dashboards.
You can only clone lenses from dashboards that you have permission to modify. If you open a dashboard with read-only access, the Open Lens and Clone options are not available. To clone a lens from a read-only dashboard, save a copy of the dashboard so that you become the owner. To save a copy, click the Dashboard button in the main Hi-Res Analytics toolbar and select Save As. Then follow the procedure below to clone a lens into the dashboard that you own.
Follow the steps below to clone a lens.
- Open a dashboard in the Hi-Res Analytics application, then click Lenses in the main toolbar and select Open. Anzo opens the Lens Selection dialog box, which lists the lenses that are available to open. For example:
- Click the Clone link for the lens that you want to clone. Anzo displays the Clone lens dialog box, and populates the Title field with the existing lens name and "(clone)." For example:
- Modify the Title to name the new copy of the lens, and add or change the Description if necessary. Then click OK.
- Anzo adds the new copy of the lens to the Lens Selection dialog box and selects it. Click OK to add the lens to the dashboard.
Data on Demand Endpoints for Individual Data Layers
In previous Anzo versions, data on demand endpoints could only be created at the graphmart level. Each graphmart could have one data on demand endpoint, and the data feed included access to all classes for all data sets in the graphmart. Version 4.1.0 introduces the ability to create data on demand endpoints for individual data layers in a graphmart. Graphmarts can now contain multiple endpoints, and users have the option to create endpoints that provide access to an entire graphmart, a combination of the data layers in a graphmart, or a single data layer in a graphmart. For more information, see Making Data Available to Applications (Data on Demand) in the Anzo Deployment and User Guide.
If you are upgrading to Anzo Version 4.1.0 from a previous version, and you have existing data on demand endpoints, see Changes to Data on Demand Endpoint URLs for information about changes to data feed URLs.
ODBC and JDBC Service URLs for Data on Demand Endpoints
In Version 4.1.0, when users create endpoints to share data with third-party applications, Anzo automatically generates ODBC and JDBC service URLs in addition to the OData URL. Users can copy a URL for use when connecting to the endpoint.
(Beta Release) Save a Table Lens as Data Layer View
Version 4.1.0 includes a beta release of a feature that enables users to create a new data layer with a view step from a table lens in a Hi-Res Analytics dashboard. The service saves the query that was used to retrieve and display the data in the table lens.
Cambridge Semantics categorizes this feature as a beta release because it was a late addition to Version 4.1.0. Though it has been tested internally by Cambridge Semantics, it has not yet been enabled and validated in a customer environment.
The ability to automatically create a view from a table lens is provided by the Grid Lens View Service, which is disabled by default. Follow the instructions below to enable the service and use it to create a view step:
Enabling the Grid Lens View Service
Follow the instructions in this section to enable the Grid Lens View Service.
- Log in to the Anzo console, expand the Administration menu, and select Plugin Configuration.
- On the Plugin Configuration screen, type grid in the Search field and press Enter. Anzo finds the Grid Lens View Service:

- Click the Grid Lens View Service title to view the plugin details:

- At the top of the screen, click Start Bundle. Anzo asks you to confirm that you want to start the service. Click OK. Anzo starts the service. You can click the Service tab to view the service status. For example:

A Save as View option also becomes available in the table lens toolbar in Hi-Res Analytics.
Creating a Table Lens View Data Layer
Follow the instructions in this section to create a new data layer and view step from a table lens in a dashboard.
- In the Hi-Res Analytics application, open the dashboard that includes the table lens from which you want to create a view.
- In the toolbar for the table lens, click Save as View.
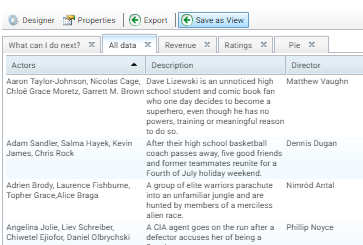
Anzo displays the Create Grid Lens View dialog box:
- In the Create Grid Lens View dialog box, type a name for the view in the View name field.
- If you want Anzo to automatically refresh the graphmart for this dashboard to load the new data layer and create the view definition in AnzoGraph, select the Refresh graphmart checkbox. For efficiency, Cambridge Semantics recommends that you leave the Refresh graphmart option disabled and refresh or reload the graphmart manually at a later time.
- If you want Anzo to automatically create a data on demand endpoint for the new data layer in the graphmart, select the Create Data On Demand Endpoint checkbox. The endpoint makes available only the data layer that includes the new grid lens view. When this option is specified, the service returns the endpoint URL after the process is complete. Note that the data will not be available via the endpoint until the graphmart is refreshed.
- Click OK to run the service and create the new view.
The service generates a new data layer in the graphmart for this dashboard and adds a view step to the layer. The layer's name includes the view name that you specified in brackets ( [ ] ). For example:
The service also generates a new data model for the view. For example:
Data Layer Validation Step
Version 4.1.0 adds a new Validation Step for data layers. The new step enables users to write a query that validates the data in a layer to ensure that it conforms to expectations. Users have the option to configure the step to cancel the load of the data layer or entire graphmart if the validation fails.
For more information, see Adding a Step that Validates the Data in the Anzo Deployment and User Guide.
Query Playground for Administrators
Version 4.1.0 introduces the Anzo Query Playground where administrators can quickly search for data that is stored in the system data source, AnzoGraph, system tables, or an LDAP server. Users can find data by typing a subject, predicate, object, or graph.
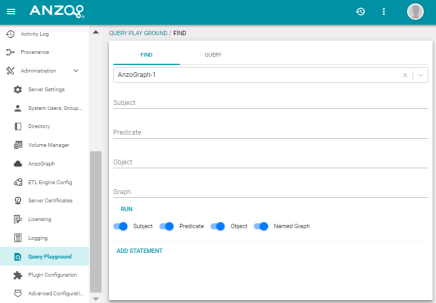
In addition to using to being able to search for values in the Find form, the Query Playground includes a query form where users can compose and test queries against system, AnzoGraph, system tables, or LDAP data sources.
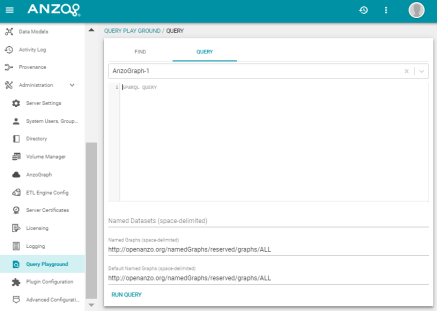
Catalog Data Sets Inherit Pipeline Permissions
By default in Version 4.1.0, data sets in the Catalog inherit the permissions from the pipeline that generated the data set. The Sharing tab for catalog items provides a view of the inherited access control list (ACL). The screen includes a Copy permissions from drop-down list that shows the provenance of the permissions. For example:
![]()
If the pipeline permissions change, the catalog item automatically inherits the changes.
Hi-Res Analytics Associated with Catalog Items
Version 4.1.0 adds a Dashboard tab that is available when viewing an item in the Catalog. The new Dashboard screen lists any Hi-Res Analytics that reference that data set.
AnzoGraph Administration Options and Health Overview
Version 4.1.0 significantly enhances AnzoGraph server statistics presentation and the functionality available for AnzoGraph administration in the Anzo user interface. The redesigned AnzoGraph view displays a health overview, which shows details about cluster nodes, loaded graphmarts, data sets, and data layers and steps. The screen also displays memory usage, CPU details, and additional server and AnzoGraph statistics. For example:
OneNote Extractor for Unstructured Pipelines
Version 4.1.0 introduces the OneNote Rich Text Extractor format transformer for unstructured pipelines. Anzo processes .one files by converting them to HTML using the Aspose library. Anzo then indexes and annotates the HTML version of the OneNote file. By default Anzo also processes OneNote attachments and links them to the original .one file. Users have the option to configure the component to ignore attachments, however.
Listeners Notified for Data Layer (RBLDS) Query Execution
In Version 4.1.0, Anzo sends notifications to listeners when data layer queries are executed.
"ls" Command Line Option to List Registry Resources
Version 4.1.0 introduces the ls command line interface option. The new option enables users to list registered resources. The ls option accepts -a to list system resources and -l to list additional details such as the title and type of the resource. For example, the following command lists the details for the semantic service resources:
anzo ls http://cambridgesemantics.com/semanticServices* -la
************************************************************************ Semantic Services ************************************************************************ http://cambridgesemantics.com/semanticServices/ACLInheritanceService Title: ACLInheritanceService Description: ACL Inheritance Service http://cambridgesemantics.com/semanticServices/AnsiTaxonomyToLdsService Title: AnsiTaxonomyToLdsService Description: Ansi Taxonomy To Lds Service http://cambridgesemantics.com/semanticServices/AowService Title: Maven Semantic Service Description: Maven Semantic Service http://cambridgesemantics.com/semanticServices/AuditLog Title: AuditLogService Description: AuditLog Service
...
Changes to Data on Demand Endpoint URLs
As described in Data on Demand Endpoints for Individual Data Layers, Version 4.1.0 adds support for configuring multiple data on demand endpoints in the same graphmart. The implementation requires a change to the data feed URLs that Anzo generates for the endpoints. Additional characters that represent the graphmart and endpoint name are added to the URLs to ensure that each URL is unique.
If you have existing data feed URLs in use from a previous Anzo version, those feeds will continue to work after the upgrade to Version 4.1.0. However, the endpoints will NOT be displayed on the Data On Demand screen in the Anzo console until the URLs are updated to include the new required information. See Updating Existing Endpoints below for instructions.
Updating Existing Endpoints
Since the new data feed URLs must also be updated in any requesting applications, Cambridge Semantics opted to provide a manual update process for modifying any existing feeds at your convenience. To update the URLs, run the following query in Anzo. The query removes the existing data feeds from the registry and then recreates the feeds in the new format:
PREFIX graphmart: <http://cambridgesemantics.com/ontologies/Graphmarts#>
PREFIX datafeed: <http://cambridgesemantics.com/ontologies/DataFeeds#>
DELETE {
GRAPH ?s {
?s a datafeed:DataFeed .
?s datafeed:dataFeedName ?endPointName.
}
}
INSERT {
GRAPH ?s {
?s graphmart:dataFeedEndPoint ?sNew .
?sNew a graphmart:DataFeedEndPoint .
?sNew graphmart:endPointName ?endPointName .
?sNew graphmart:endPointEnabled ?enabled .
?sNew graphmart:includeAlLayers "true"^^xsd:boolean .
}
}
USING DATASET <http://cambridgesemantics.com/registries/Graphmarts>
WHERE {
?s a graphmart:Graphmart .
?s datafeed:dataFeedName ?endPointName .
OPTIONAL {
?s2 a datafeed:DataFeed .
?s2 datafeed:dataFeedName ?endPointName .
}
BIND( BOUND( ?s2 ) as ?enabled )
BIND( TOURI(CONCAT( STR(?s), "/endpoint/", ?endPointName)) as ?sNew)
}
When the update completes, the endpoints appear on the Data On Demand tab for each graphmart. To re-establish the endpoint connection in external applications, copy the new connection string for each endpoint, and then replace the string in the appropriate application. For example:
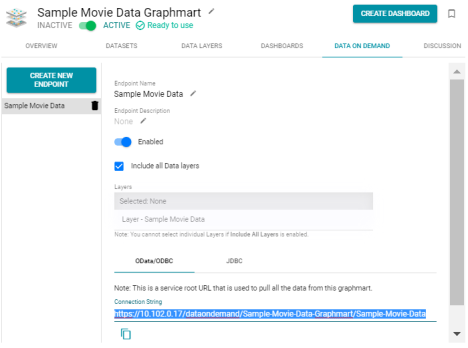
Option to Upgrade Legacy Graphmarts Moved to Admin Client
When you upgrade to Version 4.1.0 from Version 4.0.6 or earlier, any pre-existing graphmarts get labeled "Legacy Graphmart." Legacy graphmarts need to be upgraded before you can view and create data layers for them. Versions 4.0.7, 4.0.8, and 4.0.9 had an Upgrade Graphmart button on the Graphmart Details screen. Version 4.1.0 moves the upgrade graphmart functionality to the Anzo administration client. Follow the instructions below to upgrade graphmarts in Version 4.1.0:
- In a browser, go to the following URL to open the administration client:
https://<Anzo_server>:8946/admin
- Log in with your administrator username and password.
- In the navigation menu on the left, click Volume and Linked Dataset Manager. Then click the Linked Data Collection Manager tab in the Volume and Linked Dataset Manager. The client lists the collections in Anzo. In the list, any legacy graphmarts have (legacy graphmart) appended to the name. For example:

- For each graphmart that is labeled "legacy," click the Save as Graphmart link to the right of the collection name.
- Anzo displays a confirmation dialog box that asks if you want to save the collection as a graphmart. Click Yes to upgrade the collection. Anzo will now display the upgraded graphmarts on the Graphmarts screen in the Anzo console.
Data Layer Usability Enhancements
To enhance usability when working with data layers, Version 4.1.0 adds the ability to expand and collapse data layers to show or hide the steps. It also adds an option to quickly copy the URI for any data layer or step.
Keys Automatically Added to Key/Value Table for Template Steps
In Version 4.1.0, when a user adds a key to a query in a Template Step, Anzo automatically adds the key to the key/value table. Users can then simply type the value for a key instead of having to create a new table entry for each key. Version 4.1.0 also adds the ability to search for keys and values in the table.
Auto-Ingest Populates Data and Graph Source Names
Version 4.1.0 enhances the auto-ingest workflow to automatically populate the data source as well as the graph data source if only one graph source is configured.
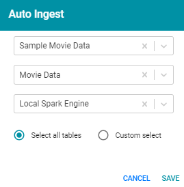
Anzo Version 4.0.8
This section describes the improvements and issues that were fixed in Anzo Version 4.0.8.
- New JSON Data Source
- New Data Science Toolkit
- New Graphmart Data Layer Load Setting
- New Ability to Reload Individual Data Layers
- New Reusable Template Step
- New Option to Materialize Data Created by View Steps
- New Option to Filter Data in Load Data Steps
- New Ability to View Inherited Permissions for Data Sets and Sources
- New Option to Import CSV Files from a Computer
- New Option to Add Table Queries to Existing Schemas
- New Options to Enable Complex Password Requirements
- New Option to Enable Deduplication for Spark Pipelines
- Parameterized Schema Names for Spark Jobs
- Upgraded Spark Engine
- Ability to Filter Table Types When Importing Schemas
New JSON Data Source
Version 4.0.8 adds support for ingesting data from JSON files. For information, see Importing Data from JSON Files in the Anzo Deployment and User Guide.
New Data Science Toolkit
Version 4.0.8 introduces the Anzo Data Science Toolkit (DSTK). The DTSK is a SPARQL service that enables users to query external data, such as data stored in databases, CSV, XML, and JSON files, or APIs, without needing to ingest the data into Anzo. Using the DSTK, users can combine Anzo-stored data with external data.
New Graphmart Data Layer Load Setting
In Version 4.0.7, if running any of the steps in a data layer failed with an error, the entire graphmart failed to load to AnzoGraph and remained Inactive in the Anzo console. Version 4.0.8 introduces a Load layers that do not fail setting on the Details tab for graphmarts. The setting enables users to choose whether to abort the load if any data layer has an error or continue the load for layers that succeed and skip the layer that fails. By default, Anzo is configured to load all layers that succeed.
To disable the option so that a failing layer aborts the graphmart load, click the Load layers that do not fail slider and move it to the left.
New Ability to Reload Individual Data Layers
Previously if any data layer in a graphmart changed, users had to reload the entire graphmart to update the data in memory. In Version 4.0.8, users have the ability to reload changed layers individually without reloading the graphmart. If a data layer changes, Anzo displays a Refresh button on the Data Layers screen. For example:
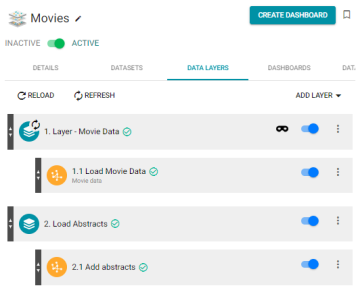
Clicking Refresh reloads the data only for the data layers that changed. Clicking Reload drops all of the data for the graphmart and reloads it. If multiple layers changed, and users want to load one layer at a time, Anzo also provides the option to reload a single layer by clicking the reload or refresh icon on an individual layer. For example:
New Reusable Template Step
Version 4.0.8 introduces a Template Step that enables users to write parameterized queries for dynamic reuse in multiple data layers and graphmarts. In templated steps, key/value pairs are represented by parameters in a query. When reusing the step, users do not need to rewrite the query to target different data; they simply modify the values for the keys. For more information, see Adding a Query Template Step in the Anzo Deployment and User Guide.
New Option to Materialize Data Created by View Steps
In Version 4.0.7, users could create virtual views of the data in View steps. Only the view definition was stored in memory and not a copy of the data constructed by the view query. In Version 4.0.8, users have the option to configure views so that Anzo stores a copy of the data that the view creates as well as the view definition. For more information, see Adding a Step that Creates a View of the Data in the Anzo Deployment and User Guide.
New Option to Filter Data in Load Data Steps
Version 4.0.8 introduces the option to write a query in Load Data steps that filters the data that is loaded from the step's linked data set. For example, if the data set includes a large number of properties and you are only interested in a subset of them, you can write an INSERT query that loads the subset of properties. For more information, see Adding a Step that Loads a Data Set in the Anzo Deployment and User Guide.
New Ability to View Inherited Permissions for Data Sets and Sources
In Version 4.0.8, the Sharing tab for Data Sources and Datasets provides a view of the inherited access control list (ACL) for the component. The screen includes a Copy permissions from drop-down list that shows the provenance of the permissions. For example:
Users have the option to choose a different ACL to apply to the data set or data source.
New Option to Import CSV Files from a Computer
In previous releases, when creating a CSV data source, users were required to import CSV files from a location that was available to the Anzo file system or had been previously configured as a file connection. When configuring a CSV data source in Version 4.0.8, users have the option to import CSV files directly from their computer.
New Option to Add Table Queries to Existing Schemas
Version 4.0.8 includes an option that enables users to add tables to existing schemas by writing table queries. For more information, see Adding a Table Query to a Schema in the Anzo user documentation.
New Options to Enable Complex Password Requirements
Version 4.0.8 introduces options that enable administrators to place more complex restrictions on passwords for users whose accounts are created locally in Anzo. Password requirements are defined in the Anzo Keystore API. Follow the instructions below to customize the password requirements.
- Log in to the Anzo console, expand the Administration menu item, and click Advanced Configuration.
- In the Search field on the Advanced Configuration screen, type keystore to search for the keystore API.
- In the search results, click Anzo Keystore API. Anzo displays the API details. For example:
- On the API details screen, click the Services tab. Then expand the Anzo Keystore API drop-down under Configurable Services.
- Expand the org.openanzo.security.KeyStore drop-down list to view the password settings at the bottom of the list.

- To modify values, such as to require a minimum number of special characters, digits, or uppercase letters, click the Edit icon (
 ) next to an option to edit that value. Click the check mark icon (
) next to an option to edit that value. Click the check mark icon ( ) to save changes to an option, or click the X icon (
) to save changes to an option, or click the X icon ( ) to clear the value for an option.
) to clear the value for an option. - When you finish entering password requirements, restart Anzo to submit the configuration changes. Users whose accounts were created in Anzo will be required to create new passwords that conform to the requirements.
New Option to Enable Deduplication for Spark Pipelines
To streamline the ETL process, and because AnzoGraph automatically deduplicates data when it is loaded into memory, the Spark ETL engine does not remove duplicates by default. If the source contains a significant number of duplicate entities, however, and you want to remove them during the ETL process, Version 4.0.8 introduces a Dedupe output per executor option for graph data sources.
Enabling the Dedupe output per executor option instructs Spark to remove duplicates when running pipelines for the graph source. The option limits the number of duplicates to one duplicate per Spark executor node. For example, if the Spark configuration has 10 executor nodes, the resulting data set contains a maximum of 10 duplicate entities.
For more information, see Creating a Graph Data Source in the Anzo Deployment and User Guide.
Parameterized Schema Names for Spark Jobs
To aid in portability for ETL jobs, Version 4.0.8 adds a new schema name parameter type for Spark jobs. When running a job, users can include the following statement to replace the previous schema name with the new name:
--schemaReplace oldSchemaNamenewSchemaName
Upgraded Spark Engine
Version 4.0.8 upgrades the Spark ETL Engine to version 2.2.0. Upgrades of existing servers will continue to use Spark version 1.6 by default.
Ability to Filter Table Types When Importing Schemas
Version 4.0.8 provides the ability to filter table types at the database-level when importing schemas. For example, users can filter out data such as views or stored procedures.
Anzo Version 4.0.7
This section describes the improvements and issues that were fixed in Anzo Version 4.0.7.
- New Data Layers Functionality
- Upgrade Legacy Graphmarts and Dashboards for Data Layers
- Deprecated HTTP/S Communication Support Between Anzo and AnzoGraph
- Renamed Anzo on the Web to Hi-Res Analytics
- New Comments Column in Mappings
- New Conditional Parameters for Filters in Mappings
- New Anzo CLI Command to Deregister URIs
- Renamed Projects to Pipelines
- New SSL Certificate Support with Anzo Clients
- Auto-Ingest Additional Source Data without Overwriting Existing Data in the Pipeline
- Excluded Timing Stack Output in Audit Log
New Data Layers Functionality
Version 4.0.7 introduces the ability to create data layers in graphmarts. Data layers enable users to enhance graphmarts dynamically by creating layers that can load additional data sets, mask certain data, infer new data automatically, or run SPARQL queries to create, clean, conform, or transform data. And users can dynamically turn data layers on and off in Hi-Res Analytics dashboards. For details about the new feature, see Working with Data Layers in the Anzo user documentation.
Upgrade Legacy Graphmarts and Dashboards for Data Layers
When you upgrade to Version 4.0.7, any pre-existing graphmarts get labeled "Legacy Graphmart." The legacy graphmarts need to be upgraded before you can view and create data layers for them. When viewing details for a legacy graphmart, the Anzo console displays an Upgrade Graphmart button. Click Upgrade Graphmart to update the graphmart and enable data layers. For example:

In addition to upgrading legacy graphmarts, any Hi-Res Analytics dashboards that are associated with those graphmarts need to be updated to the new Graphmart dashboard type. Follow the instructions below to update existing Hi-Res Analytics for legacy graphmarts:
- Log in to the Anzo console and click Graphmarts.
- Click the name of the graphmart whose dashboards you want to update. Anzo displays the graphmart details.
- Click the Dashboards tab to view the list of dashboards for the graphmart.
- Click a dashboard name to open it in Hi-Res Analytics.
- In the Hi-Res Analytics main toolbar, click Dashboard and select Save As. Anzo displays the New Dashboard dialog box.
- On the New Dashboard dialog box, type a name for the dashboard in the Title field.
- Click the Type drop-down list and select Graphmart dashboard, and then click OK. The new dashboard is now updated to display data layers that are configured for the graphmart. Repeat this process for all dashboards that were created for legacy graphmarts.
Deprecated HTTP/S Communication Support Between Anzo and AnzoGraph
Version 4.0.7 requires the use of Anzo protocol (gRPC) for secure communication between AnzoGraph and Anzo servers. When configuring a new connection between Anzo and AnzoGraph, you are required to use the Anzo protocol port (5700) and cannot specify an HTTP/S port.
If you have an existing AnzoGraph data source configured to use HTTP/S communication on ports 7070, 7071, or a custom port, that connection continues to work after upgrading to 4.0.7. You cannot configure new connections to use HTTP/S communication.
Renamed Anzo on the Web to Hi-Res Analytics
In Version 4.0.7, the name of the Anzo on the Web component was changed to Hi-Res Analytics. When granting privileges to create and edit dashboards, configure user or role permissions to include the Hi-Res Analytics application. For more information about configuring permissions see Managing Anzo Users and Roles in the Anzo user documentation.
New Comments Column in Mappings
To facilitate collaboration, Version 4.0.7 introduces a new Comments column next to the Source column in mappings. The column provides space for users to enter comments about a mapping, such as explanations of the logic used in the mapping or details about the source data. Comments in a mapping are not ingested but remain in the mapping file for users to see.
New Conditional Parameters for Filters in Mappings
Version 4.0.7 introduces the ability to set up conditional parameters or criteria for filters in mappings so that the mapping can ingest a subset of the source data rather than all values. For example, if a user wants to add to the data lake data that has decades worth of historical information but is only interested in ingesting data from certain years, the user can set join criteria to filter out data that does not fall between those years. For more information, see Configuring Mappings to Ingest a Subset of the Source Data in the Anzo user documentation.
New Anzo CLI Command to Deregister URIs
Version 4.0.7 adds a deregister subcommand to the Anzo command line interface. The deregister subcommand enables users remove a specified resource from the appropriate system registries based on the rdf:type of the resource. For more information about the Anzo CLI, see Using the Anzo Command Line Interface in the Anzo user documentation.
Renamed Projects to Pipelines
In Version 4.0.7, the Projects option in the Ingestion menu was changed to Pipelines.
New SSL Certificate Support with Anzo Clients
Prior to Version 4.0.7, Anzo clients, like Anzo Unstructured, used the standard java trust store. In Version 4.0.7, if users add SSL certificates or certificate authorities to the client trust store (client.ts), Anzo clients use those certificates as well.
Auto-Ingest Additional Source Data without Overwriting Existing Data in the Pipeline
Previously if a user auto-ingested a subset of source tables in a database schema and then subsequently auto-ingested additional tables without re-selecting the original tables, Anzo overwrote the original ETL project with a new project that only included the newly ingested tables. In Version 4.0.7, the default Anzo behavior changed. If a user adds source tables to an existing auto-ingested project without selecting the original tables for import, Anzo does not overwrite the existing project; it keeps the original project with the previously ingested tables and adds the new tables to it.
To enable users to control the behavior of adding tables to an auto-ingested project, Version 4.0.7 adds a Regenerate All Artifacts on Auto-Ingest option to the Advanced tab in the Dataset manager. For example:
If the Regenerate All Artifacts on Auto-Ingest option is enabled, Anzo does overwrite existing auto-ingested projects if users add schema tables without re-selecting the previously ingested tables.
Excluded Timing Stack Output in Audit Log
By default, the Anzo user Audit Log included timing stack information that was output as a very long string. If the Audit Log was loaded to AnzoGraph for analysis, the timing stack string caused the load to fail with an out-of-memory error. In Version 4.0.7 the timing stack information is omitted from the Audit Log by default.
Users who do not want to load the Audit Log into AnzoGraph can enable the timing stack output by adding the com.cambridgesemantics.anzo.auditlog.includeTimingStack property to the Anzo Audit Logging Framework bundle. Follow the instructions below to include timing stack output in Audit Log:
- Log in to the Anzo console, expand the Administration menu item, and click Advanced Configuration.
- In the list of bundles on the left of the screen, select Anzo Audit Logging Framework. Anzo displays the bundle details.
- In the list of properties under com.cambridgesemantics.anzo.AuditLog, click Add property.
- In the Add property dialog box, add com.cambridgesemantics.anzo.auditlog.includeTimingStack to the Name field.
- Type true in the Value field, and then click OK.
- Restart Anzo to complete the bundle configuration. You can restart the server by clicking the Restart button (
 ) at the top of the Advanced Configuration screen.
) at the top of the Advanced Configuration screen.