Anzo 5.1 Releases
If you are upgrading to 5.1.x from a previous release, see Anzo 5.1 Installation and Upgrade Notes for important notes about upgrades to Anzo components.
- Anzo Version 5.1.10
- Anzo Version 5.1.9
- Anzo Version 5.1.8
- Anzo Version 5.1.7
- Anzo Version 5.1.6
- Anzo Version 5.1.5
- Anzo Version 5.1.4
- Anzo Version 5.1.3
- Anzo Version 5.1.2
- Anzo Version 5.1.1
- Anzo Version 5.1.0
Anzo Version 5.1.10
This section describes the issue that was fixed in Anzo Version 5.1.10.
System Became Slow to Respond after ACL Inheritance Warnings
Version 5.1.10 resolves an issue that caused Anzo performance to degrade after several "Not all graphs in NamedDataset inherit acls from parentACL" warnings were returned.
Anzo Version 5.1.9
This section describes the issue that was fixed in Anzo Version 5.1.9.
Error when Sending Email Notifications
Version 5.1.9 resolves an issue in the MailerService that prevented email notifications from being sent when a non-SSL SMTP server was configured.
Anzo Version 5.1.8
This section describes the improvements and issues that were fixed in Anzo Version 5.1.8.
- Removed Restart Requirement when SSO is Enabled and Users are Added
- Preserve Status Journals for Dynamic Anzo Unstructured Deployments
- Released Upgraded Versions of the AnzoGraph, Anzo Agent, and Unstructured K8s Operators
- Imported Properties from a Child Model were Unavailable in the Parent Model
- Validation Failed for Mappings with Imported Properties
Removed Restart Requirement when SSO is Enabled and Users are Added
In previous versions, when SSO was configured and Anzo was synced to the directory server to add new users, Anzo needed to be restarted before the new users could log in. Version 5.1.8 resolves the issue so that a restart is not required.
Preserve Status Journals for Dynamic Anzo Unstructured Deployments
For dynamic, Kubernetes-based deployments of Anzo Unstructured, Version 5.1.8 ensures that status journals for unstructured pipelines are serialized to file-backed linked data sets (FLDS) before the pipeline's resources are deprovisioned. As part of the change, only the status of the most recent run of a pipeline remains stored in a status journal. All previous reports are automatically converted to an FLDS and the original status journal is deleted.
Released Upgraded Versions of the AnzoGraph, Anzo Agent, and Unstructured K8s Operators
Version 5.1.8 adds the option to upgrade the AnzoGraph, Anzo Agent, and Anzo Unstructured Operators that are used in dynamic, Kubernetes-based deployments. The new version, Version 2.0, updates the schema to introduce greater flexibility for being able to change the configuration of a dynamic application, such as to add a volume or change an environment variable, without having to recreate the node pool.
Upgrading the Operators is optional. You can continue to use Version 1.x Operators after upgrading to Anzo 5.1.8. No action is needed. To learn more, your Cambridge Semantics Customer Success manager can provide details and guide you through the updates to your Kubernetes (K8s) infrastructure. If you have multiple Anzo environments that access the same K8s cluster, all environments that use the cluster must use the same version of the Operators.
Imported Properties from a Child Model were Unavailable in the Parent Model
Version 5.1.8 corrects an issue that prevented the properties in an imported child model from being reflected in the parent model.
Validation Failed for Mappings with Imported Properties
Version 5.1.8 resolves an issue that caused mappings to become invalid if they referenced properties in a model that were imported from another model.
Anzo Version 5.1.7
This section describes the improvements and issues that were fixed in Anzo Version 5.1.7.
- Added the Ability to Designate the Load Priority for Graphmarts
- Added Option to Generate Statistics After Loading Each Data Layer
- Added Query Descriptions to the Activity Log
- Incorporated Orchestration Service and Associated Datasets into Anzo
- Added a Service Request for Clearing Managed Editions
- Improved Anzo-Managed Upgrades of FLDS to CBLDS
- Improved Layout for Table Lenses with Large Number of Columns
- Improved Handling of Permissions for Imported and Exported Artifacts
- Added Disk Space Checking to System Monitor Service
- Added Support for Pipe Characters in Query Builder Queries
- Removed the Limit for ASK Queries in the Query Builder
- Upgraded the CData XML Driver
- Modified Detailed Thread Dump Script to Run with Default Configuration
- Hid the Provenance Viewer by Default
- Reduced Unprocessed Request Limit for Anzo Unstructured
- The Model for a Parquet Source Did not Inherit Permissions
- Pie Charts Failed to Render
- Error when Anzo Admin CLI Used with HTTP
- Error for OData $expand when Data Nested More Than 2 Levels
- Fixes for Memory Leaks
- Auto-Refresh not Triggered for Graphmart with Journal-Based Data Sets
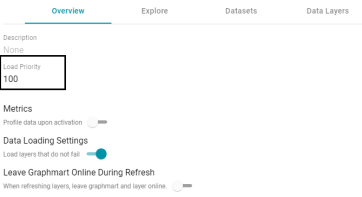
Added the Ability to Designate the Load Priority for Graphmarts
Version 5.1.7 adds a Load Priority setting to the Overview tab for Graphmarts (shown in the image below). If you want Anzo to prioritize the order in which Graphmarts are activated when reconnecting to AnzoGraph or resetting and reloading the AnzoGraph server, you can designate a Load Priority for each Graphmart. When reloading AnzoGraph, Anzo activates the Graphmarts in sequence, starting with the lowest Load Priority number. The default value is 100.
Added Option to Generate Statistics After Loading Each Data Layer
Version 5.1.7 adds a Generate Statistics After Each Layer setting for Graphmarts. Typically the AnzoGraph connection is configured to automatically initiate AnzoGraph's internal statistics gathering queries after loading a Graphmart. However, if a user refreshes individual Data Layers rather than the entire Graphmart, those queries are not triggered. Enabling this setting initiates the statistics gathering queries each time a layer is loaded. This helps the AnzoGraph query planner generate ideal query execution plans for queries that are run against the refreshed Data Layers.
Added Query Descriptions to the Activity Log
Version 5.1.7 adds to the Activity Log descriptions of each of the queries and other processes that run when a Graphmart is activated, reloaded, or refreshed. Including the descriptions helps users more easily find the query or step they are interested in investigating.
Incorporated Orchestration Service and Associated Datasets into Anzo
Version 5.1.7 adds a default Orchestration Service instance and associated datasets into the core Anzo product. With this change, the Orchestration Service no longer needs to be imported separately after installing Anzo. However, setup of Connections, Ingestion Managers, and Load Services is still required.
If you currently use the Orchestration Service and your solution is defined by the URI http://cambridgesemantics.com/service/OrchestrationService, the default Orchestration Service configuration in the registry-data in ASDL Services will automatically be updated during the Anzo upgrade.
If you have a custom Orchestration Service defined with URI that is different than http://cambridgesemantics.com/service/OrchestrationService, follow the steps in Prepare any Custom Orchestration Services before upgrading Anzo.
Added a Service Request for Clearing Managed Editions
Version 5.1.7 introduces a clearWorkingEdition Semantic Service request that enables administrators to clear out all of the existing components from the Managed Edition of a Dataset so that the Edition is recreated from scratch the next time the pipeline is published. For more information, see How do I clear the Data Components from the Managed Edition of a Dataset? in the Anzo Deployment & User Guide.
Improved Anzo-Managed Upgrades of FLDS to CBLDS
Version 5.1.7 improves the handling of auto-updates to any existing file-based linked data sets (FLDS) to component based linked data sets (CBLDS) when Anzo is upgraded from earlier releases to a release that supports Dataset Editions.
Improved Layout for Table Lenses with Large Number of Columns
Version 5.1.7 improves the layout and column visibility for Table lenses that display a large number of columns.
Improved Handling of Permissions for Imported and Exported Artifacts
Version 5.1.7 includes several fixes that improve the handling of permissions for imported and exported artifacts as well as permission inheritance in general.
Added Disk Space Checking to System Monitor Service
In Version 5.1.7, to avoid filling up the disk when writing stack and heap dumps, the System Monitor Service checks the amount of disk space that is available before writing out files. If there is less than 1 GB of space left, the service will not write files.
Added Support for Pipe Characters in Query Builder Queries
Version 5.1.7 adds support for including pipe (|) characters to express OR in Query Builder queries.
Removed the Limit for ASK Queries in the Query Builder
Version 5.1.7 removes the LIMIT that is automatically applied to Query Builder queries if the query is an ASK query. Automatically applying the default LIMIT caused ASK queries to return an error.
Upgraded the CData XML Driver
Version 5.1.7 includes an update to the CData XML driver for better performance when publishing XML data sources for both relational and flat schema types.
Modified Detailed Thread Dump Script to Run with Default Configuration
In previous releases, the <install_path>/Server/scripts/Anzo-detailed-thread-dump.sh script needed to be configured before it could be run. In Version 5.1.7 the script is pre-configured to run.
Hid the Provenance Viewer by Default
By default, Version 5.1.7 hides the Provenance viewer in the Anzo application for all users except the sysadmin user. To enable the Provenance option for a role, you can assign the View Provenance permission to the role. Version 5.1.7 also enhances the Provenance viewer so that it is more performant than in previous Anzo releases.
Reduced Unprocessed Request Limit for Anzo Unstructured
Version 5.1.7 reduces the Anzo Unstructured Unprocessed Request Limit to guard against out-of-memory conditions that could occur if smaller-sized Anzo Agents were configured and large pipelines were processed.
The Model for a Parquet Source Did not Inherit Permissions
Version 5.1.7 corrects an issue where the generated Model for a Parquet Data Source did not automatically inherit the permissions from the Data Source. As a result, users could not access the Model.
Pie Charts Failed to Render
Version 5.1.7 resolves an issue that caused Pie Charts to return an "Error processing chart information" error and fail to render.
Error when Anzo Admin CLI Used with HTTP
Version 5.1.7 resolves a problem that caused the Anzo admin CLI to return a classpath error when the CLI was configured to use HTTP instead of JMS.
Error for OData $expand when Data Nested More Than 2 Levels
Version 5.1.7 resolves an issue that caused an OData query to return an error when the $expand operator was used to expand data that was nested by more than two levels.
Fixes for Memory Leaks
Version 5.1.7 includes a number of fixes to shore up areas of the system where memory leaks could occur.
Auto-Refresh not Triggered for Graphmart with Journal-Based Data Sets
Version 5.1.7 corrects an issue that caused automatic Graphmart refresh (Manual Refresh Graphmart was false) to fail when a Graphmart had a single Load Data Step that included several journal-based Datasets.
Anzo Version 5.1.6
This section describes the improvements and issues that were fixed in Anzo Version 5.1.6.
- Added Waterfall Chart Type
- Added SPARQL Endpoint Option to Skip Query Cache
- Added Option to Exclude Filters on Hyperlinked Lenses
- Added Support for Kubernetes API Versions 1.18 and 1.19
- Added Support for Azure Kubernetes Service Node Labels
- Added Support for Using Query Contexts with Custom Database Connections
- Added Data on Demand Support for Classes and Properties with Matching Names
- Improved Efficiency Between Orchestration Service and Ingest Manager
- Added Activate/Deactivate Graphmart Options to Orchestration Service
- Improved Page Load Performance for Customized Hi-Res Analytics Application
- Improved Behavior for Canceled SPARQL Endpoint and Query Builder Download Requests
- Improved Layout and Behavior on Advanced Configuration Screen
- Corrected Misalignment of Drill Down Icons in Table Lenses
- LDAP Change Not Reflected in User Interface after Sync
- Startup Failed when Orchestration Service was Enabled
- Default ETL Engine Configuration Overrode Selected Engine for Pipeline
- Could not Display Delete Button in Linked Data Set Dashboard
- OData Error for Filter with Nested Lambda Operators
- Null Pointer Exception when Importing Unstructured FLDS
- Extraneous AnzoGraph Persistence Error when Activating Graphmart with Export Steps
Added Waterfall Chart Type
Version 5.1.6 introduces a new Waterfall Chart Type lens for Hi-Res Analytics dashboards. The Waterfall chart compares the contribution of each value to the total values across categories.
The aggregated Waterfall Chart Summary cannot be enabled unless the X Axis value is a string. To display the Waterfall Summary, choose a string value for the X Axis or use a function such as STR to coerce a non-string value to a string.
Tip: When converting date values to strings, use the format yyyy-mm-dd to apply the expected date sort order.
Added SPARQL Endpoint Option to Skip Query Cache
Version 5.1.6 adds the SPARQL endpoint skipCache parameter. Specifying skipCache=true in a request avoids the reuse of the cache that may exist from a previous run of the query.
Added Option to Exclude Filters on Hyperlinked Lenses
Version 5.1.6 adds an option to exclude the filters on the origin dashboard when configuring a hyperlink to another lens or dashboard. The new option, Exclude Group Filter (shown below), is available in the Table lens Designer when configuring a column hyperlink.

Added Support for Kubernetes API Versions 1.18 and 1.19
Version 5.1.6 adds support for K8s API versions 1.18 and 1.19. Previously, only version 1.17 was supported.
Added Support for Azure Kubernetes Service Node Labels
Version 5.1.6 adds support for using node labels to identify the purpose of the nodes in an Azure Kubernetes Service node pool.
Added Support for Using Query Contexts with Custom Database Connections
Version 5.1.6 adds support for using a query context to connect to a custom database in Graph Data Interface queries.
Added Data on Demand Support for Classes and Properties with Matching Names
Version 5.1.6 improves handling of Data on Demand endpoints when the data includes a class and property that have the same name but differ only in character case. Anzo detects the name collision and generates unique key properties.
Improved Efficiency Between Orchestration Service and Ingest Manager
To increase ingestion performance, Version 5.1.6 eliminates the redundancy of operations when the Orchestration Service and Ingest Manager are used together.
Added Activate/Deactivate Graphmart Options to Orchestration Service
Version 5.1.6 enhances the Graphmart Load Service that is called from the Orchestration Service to add the option to activate or deactivate graphmarts.
Improved Page Load Performance for Customized Hi-Res Analytics Application
Version 5.1.6 significantly improves the page load performance when a custom personality is used for the Hi-Res Analytics application.
Improved Behavior for Canceled SPARQL Endpoint and Query Builder Download Requests
Version 5.1.6 ensures that Anzo responds when a user cancels a SPARQL endpoint query. This version also improves behavior when results are being downloaded from the Query Builder and the request is canceled. Both types of cancellations log messages to anzo_full.log.
Improved Layout and Behavior on Advanced Configuration Screen
Version 5.1.6 improves the layout and behavior when filtering or navigating between pages on the Advanced Configuration screen in the Administration application.
Corrected Misalignment of Drill Down Icons in Table Lenses
When scrolling in a dashboard with a Table lens that had drill down functionality configured, the drill down icons could become misaligned. Version 5.1.6 corrects the alignment.
LDAP Change Not Reflected in User Interface after Sync
Version 5.1.6 resolves an issue where, in certain circumstances, the user interface did not reflect directory group changes after the server was synchronized with Anzo.
Startup Failed when Orchestration Service was Enabled
Version 5.1.6 resolves an issue that prevented Anzo from starting if the Orchestration Service (the com.cambridgesemantics.anzo.asdl.services bundle) was enabled.
Default ETL Engine Configuration Overrode Selected Engine for Pipeline
Version 5.1.6 resolves in issue that caused the default ETL engine configuration to be used to publish a pipeline even though the user specified a different ETL engine when publishing the jobs.
Could not Display Delete Button in Linked Data Set Dashboard
Version 5.1.6 corrects an issue that prevented the Delete button from being displayed when it was added as a column in a Table lens on a Linked Data Set dashboard.
OData Error for Filter with Nested Lambda Operators
Version 5.1.6 resolves an issue that caused an OData request to return an error if the query included a filter with nested lambda operators.
Null Pointer Exception when Importing Unstructured FLDS
Version 5.1.6 resolves in issue that caused an import of an unstructured FLDS to the Dataset catalog to fail with a null pointer exception.
Extraneous AnzoGraph Persistence Error when Activating Graphmart with Export Steps
Version 5.1.6 corrects an issue that caused Anzo to return an AnzoGraph persistence error and fail to activate Data Layers with Export Steps even though persistence was disabled on the AnzoGraph system.
Anzo Version 5.1.5
This section describes the improvements and issues that were fixed in Anzo Version 5.1.5.
- ETL Failed for Custom Database Connection
- Orchestration Service Failed to Trigger Scheduled Job
- Incorrect Results for Property Graph (RDF*) Query
- Parse Error Caused K8s-Based AnzoGraph Deployment to Fail
- New Unstructured Edition Empty if Previous Run Failed
ETL Failed for Custom Database Connection
Version 5.1.5 corrects an issue that caused ETL jobs to fail when the embedded Spark or Sparkler ETL engines were used to onboard data from a custom database data source.
Orchestration Service Failed to Trigger Scheduled Job
Version 5.1.5 resolves an issue that caused the Orchestration Service to fail to trigger the Load service for a scheduled job.
Incorrect Results for Property Graph (RDF*) Query
When a property graph query that included an OPTIONAL clause was run from the Query Builder, the query generator incorrectly excluded the OPTIONAL clause and incorrect results were returned. Version 5.1.5 corrects the issue.
Parse Error Caused K8s-Based AnzoGraph Deployment to Fail
When a user triggered a Kubernetes-based dynamic deployment of AnzoGraph, a parse error in the compliance check for the AnzoGraph extensions caused the deployment to fail. Version 5.1.5 corrects the parse error.
New Unstructured Edition Empty if Previous Run Failed
If an unstructured pipeline completed successfully, the new edition that was generated from the latest run could be empty if a previous run had failed. Version 5.1.5 resolves this issue.
Anzo Version 5.1.4
This section describes the improvements and issues that were fixed in Anzo Version 5.1.4.
- Improved Oracle Date Type Handling in Sparkler Compiler
- ETL Engines Generated URI Templates for Null Values
- User Interface Inaccessible after Upgrade
Improved Oracle Date Type Handling in Sparkler Compiler
Version 5.1.4 restores a workaround that is needed to handle Oracle DATE types. Without the fix, certain date values could be missing from the output data once the Sparkler job was complete.
ETL Engines Generated URI Templates for Null Values
When a user created a custom mapping to map related entities and the referenced entities had properties with null values, Spark and Sparkler incorrectly generated GUIDs to use as URI templates for the null objects. Version 5.1.4 corrects the issue so that the ETL engines do not create URI templates for null objects.
User Interface Inaccessible after Upgrade
When a proxy was used for accessing the user interface, the Anzo application became inaccessible after upgrading from Version 5.0.2 to 5.1.3. Version 5.1.4 corrects the issue.
Anzo Version 5.1.3
This section describes the improvements and issues that were fixed in Anzo Version 5.1.3.
- Removed Oracle JDBC Bundle Dependency
- Added Insert Wildcard Option for XML Data Sources
- Intermittent Error when Refreshing Model Working Set
- Deleted Model Remained Visible in the User Interface
- Incorrect Reordering of Bind and Optional Clauses
- Save Error when Changing Edition in Load Data Step
- Connection to MSSQL Data Source Failed after Upgrade
- Failed to Add Data Set to Graphmart from Datasets Tab
- User Interface Displayed Incorrect Edition in Load Data Step
- LDAP UUID Shown as User Name for New Import
- Null Pointer Exception when Indexing Unstructured Documents
- No Results for Data on Demand Query with $filter on {object}_key
- Orchestration Scheduler Jobs Not Visible to All Users
- Sparkler Compiler Generated Instances for Null Values
Removed Oracle JDBC Bundle Dependency
Version 5.1.3 removes the dependency on the Oracle 11.2 JDBC bundle so that the .jar file can be removed and/or replaced without causing an error on Anzo startup.
Added Insert Wildcard Option for XML Data Sources
Version 5.1.3 adds the Insert Wildcard option to the File Location dialog box that is presented when selecting files for XML data sources. This option was removed in Version 5.1.1 because it was not supported by the CData driver at that time. By specifying a wildcard when importing XML files, you can select multiple files with the same schema. For more information about importing XML files, see Creating an XML Data Source in the Anzo Deployment and User Guide.
Intermittent Error when Refreshing Model Working Set
Version 5.1.3 resolves an error that occurred intermittently when a user added or removed models from the Working Set.
Deleted Model Remained Visible in the User Interface
Version 5.1.3 corrects an issue that caused a model that was deleted via the Anzo admin CLI to remain visible in the Anzo application.
Incorrect Reordering of Bind and Optional Clauses
When a user submitted a query that included several BIND and OPTIONAL statements, the Anzo query generator incorrectly reordered the clauses in a way that caused the query to fail with an error. Version 5.1.3 corrects the issue so that the order of the assignment and optional clauses are valid.
Save Error when Changing Edition in Load Data Step
Version 5.1.3 resolves an issue that could occur when a user modified a Load Data Step to replace the default edition of a data set with a different edition. In some cases, the step failed to save after the new edition was selected.
Connection to MSSQL Data Source Failed after Upgrade
Version 5.1.3 corrects an issue that caused connections to MSSQL data sources to fail with an error after Anzo was upgraded from a 5.0.x version to a 5.1.x version.
Failed to Add Data Set to Graphmart from Datasets Tab
Version 5.1.3 fixes an issue that could cause adding a data set to a graphmart to fail if the Add Dataset button was used to add multiple data sets one at a time.
User Interface Displayed Incorrect Edition in Load Data Step
When a graphmart was created from the Dataset catalog, there could be a circumstance where the user interface displayed the incorrect default edition in the Load Data Step for the new graphmart. Version 5.1.3 corrects the problem to ensure that the UI displays the correct edition.
LDAP UUID Shown as User Name for New Import
When a user imported a version of a pipeline to a new Anzo instance, the user information that was displayed in the Import Advanced Options was the LDAP UUID instead of the user name. Version 5.1.3 corrects the issue so that the user name is shown instead of the LDAP UUID.
Null Pointer Exception when Indexing Unstructured Documents
When indexing unstructured documents, the fully qualified name (FQN) URI was used as the Elasticsearch document ID. If a document was missing an FQN, however, a null pointer exception could occur during the indexing process. In Version 5.1.3, if a document is missing an FQN, Elasticsearch assigns a document ID.
No Results for Data on Demand Query with $filter on {object}_key
Version 5.1.3 corrects an issue that caused Anzo to return an empty result set when a Data on Demand query had a $filter on an {object}_key property within a lambda operator.
Orchestration Scheduler Jobs Not Visible to All Users
Version 5.1.3 resolves an issue where jobs that were created by the Orchestration Scheduler were only visible by the job creator and the sysadmin. In Version 5.1.3, the scheduled jobs are visible to all users with access.
Sparkler Compiler Generated Instances for Null Values
When data from a relational data source was ingested with the Sparkler compiler, URIs were generated for null values. Version 5.1.3, resolves the issue so that instances are not created for null source values.
Anzo Version 5.1.2
This section describes the improvements and issues that were fixed in Anzo Version 5.1.2.
- Improved Handling of Wildcards in File Upload Paths
- Display Multiple Models on Graphmart Explore Tab
- Prune Aborted Queries from Inflight Queries Log
- Add Missing Orchestration Service Dependency
- System Stability and Performance Improvements
Improved Handling of Wildcards in File Upload Paths
Version 5.1.2 improves the handling of wildcard characters (*) when they are used to complete a path to the files to upload.
Display Multiple Models on Graphmart Explore Tab
Version 5.1.2 corrects an issue that prevented all of the models that were included in a graphmart from being displayed on the Explore tab.
Prune Aborted Queries from Inflight Queries Log
Version 5.1.2 resolves an issue that could cause aborted AnzoGraph queries to remain in the Inflight Queries log in System Query Audit.
Add Missing Orchestration Service Dependency
Version 5.1.2 adds a dependency library that was missing and could prevent the Orchestration Service from starting.
Anzo Version 5.1.1
This section describes the improvements and issues that were fixed in Anzo Version 5.1.1.
Improvements
- Query Builder Improvements
- Export Semantic Service Improvements
- Data Profile Improvements
- New Global Prefix Manager
- Unstructured Graphmart Load Performance Improvements
- Advanced AnzoGraph Connection Improvements
- LDAP Search Performance Improvement
- Improved Tolerance for Extra Characters in ETL Additional Jars List
- Added a Copy URI Link for Roles
- Added Model Class and Property URI Prefix Options to Ingest with Dictionary Workflow
- Added Support for Escaped Parquet File Names
- Enabled Option to Omit Heap or Stack from System Monitor Dump
- Added Elasticsearch Check Before Starting Unstructured Pipeline
- Added Labels to Differentiate Problematic Editions
- Detect Malformed CSV Files Before Processing
- Clicking "Back to Anzo" Opens Anzo Application Launch Point
- Added Support for Limiting Concurrent Job Executions on Remote Sparkler Engine
Notable Changes
- Limited Metadata Dictionary to 50k Concepts
- Limited Number of Schemas Allowed Per Database Data Source
- Added Response Timeout for AnzoGraph System Queries
- Set Default ETL Engine to Sparkler
- Display Regex Annotation Class Names in Annotated Document Lens
- Removed Insert Wildcard Option for XML Data Sources
Fixes
- Expected Properties Missing from Class View
- Improved Data on Demand Handling of Models with Recursive Hierarchies
- Sparkler Engine Failed to Remove Copies of Shared Library
- Some File Handles Remained Open after Jobs Published
- Layer Required Refresh after Graphmart was Auto-Updated
- Spark Status Updates Delayed by Unreachable Livy Server for Other ETL Engine
- NPE when Filtering out Null Values in OData Query
- Could Not Resolve Data Location for HDFS File Store
- Local Sparkler Engine Generated Unnecessary SSO Provider Objects
Query Builder Improvements
Version 5.1.1 includes several fixes and enhancements to the Query Builder:
- Improve error message reporting to ensure that detailed information is displayed.
- Improve ability to resize the Query window.
- Resolve an issue that prevented users from being able to save queries in some circumstances. In addition, ensure that multiple copies of a query are not saved if a user saves a query, continues to edit it, and then saves the query again.
- Resolve an issue that prevented a user from being able to preview a Templated Step query in the Query Builder.
- Correct an issue that caused edits to be lost if a user was in the process of editing a saved or previously run query and moused over a menu item in the navigation pane without leaving the Query Builder page.
- Warn users if they navigate away from the Query Builder without saving changes.
- Ensure that CONSTRUCT queries return the correct number of results when a LIMIT is specified in the query.
- Resolve an issue that prevented the Format Query option from working when the data source was a graphmart.
- Ensure that saved queries can be deleted.
- Fix an issue that caused the Query Builder to return an "Unknown function" error when PARSEDATE was used to convert strings to date values in a graphmart.
Export Semantic Service Improvements
Version 5.1.1 includes the following enhancements to the Export Service:
- Previously the Export Service allowed users to export all of the children for one parent graph. Version 5.1.1 extends the service to allow users to export a metadata graph that includes multiple parent graphs.
- When using the Export Service to import or export multiple parent graphs, users can now specify ACLs for a single graph and the permissions will apply to all graphs in the request.
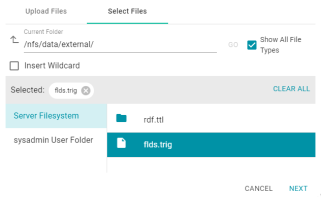
- TriG files that have been exported with the Export Service can now be imported into Anzo using the user interface. When selecting files from the File Location dialog boxes, .trig files are now displayed if the Show All File Types checkbox is selected. For example:
- The Export Service enables users to include additional predicates to follow when writing an export request.
- The Export Service enables user to exclude predicates from the export so that those instances can be preserved in the target Anzo system instead of overwritten on import.
- When exporting a dashboard, the Export Service now includes the graphs for any drill down lenses that are referenced by the dashboard.
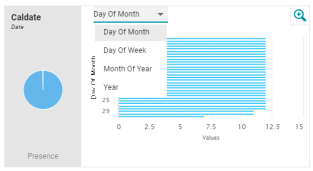
Data Profile Improvements
Version 5.1.1 enhances the metrics that are generated when profiling source or graph data to include a histogram for date or dateTime values. The metric also includes a drop-down list for changing the unit of time for the histogram. The image below shows an example of the chart that is generated for a property with date values:
New Global Prefix Manager
Version 5.1.1 introduces the Global Prefix Manager. The new prefix manager stores the standard prefixes and any custom prefixes that you want Anzo to recognize globally. Defining global prefixes creates shortcuts for inserting PREFIX statements in Query Builder and data layer queries. For more information, see Configure Global Prefixes in the Anzo Deployment and User Guide.
Unstructured Graphmart Load Performance Improvements
In previous versions, two time-consuming tasks were performed sequentially when a graphmart with unstructured data sets was activated: First, data was loaded into AnzoGraph. When the load was complete, the Elasticsearch snapshot was restored. Version 5.1.1 revises the unstructured graphmart activation process to run the AnzoGraph load and snapshot restore in parallel and significantly improve overall performance.
Advanced AnzoGraph Connection Improvements
Version 5.1.1 revises the advanced AnzoGraph connection settings to clarify the behavior that the settings control as well as give administrators more control over how Anzo sets the AnzoGraph status when Anzo and AnzoGraph are restarted. In addition, Version 5.1.1 introduces a Max Allowed Duration for Queries option for setting a limit on the amount of time Anzo waits for AnzoGraph to complete a user query. For information about all of the advanced settings, see Connecting to AnzoGraph in the Anzo Deployment and User Guide.
LDAP Search Performance Improvement
Version 5.1.1 increases the performance of LDAP searches by removing the wildcard character (*) that was automatically prepended to the search term. Anzo was performing all LDAP searches as "*<term>*" which increased the search time as well as the number of results. Now the wildcard character is only appended to the end of the term automatically, and users can add the character to the beginning of the term if they wish.
Improved Tolerance for Extra Characters in ETL Additional Jars List
In previous versions, if the list of files in the Additional Jars field in the Spark and Sparkler ETL Engine Config included extra characters, such as spaces or periods, ETL jobs could fail. Version 5.1.1 improves the tolerance for extra characters in the field so that they do not affect the ETL process.
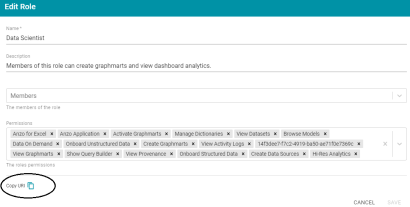
Added a Copy URI Link for Roles
For convenience when finding the named graph for a role, Version 5.1.1 adds a Copy URI ![]() link to the Edit Role screens. The image below shows the location of the Copy URI option.
link to the Edit Role screens. The image below shows the location of the Copy URI option.
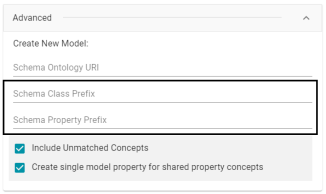
Added Model Class and Property URI Prefix Options to Ingest with Dictionary Workflow
When ingesting a data source with a metadata dictionary and creating a new model, Version 5.1.1 adds the option to set the URI prefix format to use when generating the classes and properties in the model. The Schema Class Prefix and Schema Property Prefix fields (shown in the image below) are the same fields that are available when ingesting data without a metadata dictionary. For information about the fields, see Ingesting a Data Source with a Metadata Dictionary in the Anzo Deployment and User Guide.
Added Support for Escaped Parquet File Names
Version 5.1.1 adds support for onboarding Parquet files with escaped file names and paths.
Enabled Option to Omit Heap or Stack from System Monitor Dump
To preserve disk space, Version 5.1.1 introduces the option to configure the Anzo System Monitor service to exclude heap dumps or stack dumps. For instructions on configuring the service to dump stacks or heaps but not both, see Configuring the System Monitor to Omit Heap or Stack Dumps in the Anzo Deployment and User Guide.
Added Elasticsearch Check Before Starting Unstructured Pipeline
In Version 5.1.1, if an unstructured pipeline requires Elasticsearch, Anzo verifies that Elasticsearch is available and operational before starting the pipeline. That way the user is alerted immediately if Elasticsearch is unavailable, rather than being alerted later when the pipeline fails.
Added Labels to Differentiate Problematic Editions
Version 5.1.1 adds a label to the title of a pipeline edition if that edition is incomplete or otherwise problematic, such as if a pipeline was interrupted and the related FLDS is incomplete.
Detect Malformed CSV Files Before Processing
Version 5.1.1 detects malformed CSV files and displays an error when pending files are processed rather than when the data source is ingested.
Clicking "Back to Anzo" Opens Anzo Application Launch Point
Previously, clicking the Back to Anzo button in the Administration application opened the Anzo Home page. In Version 5.1.1, clicking the Back to Anzo button returns the user to the same screen they were on when they launched the Administration application.
Added Support for Limiting Concurrent Job Executions on Remote Sparkler Engine
Version 5.1.1 adds support for configuring a remote Sparkler engine to limit the number of jobs that can be run concurrently. For information, see Limiting Job Concurrency on a Remote Sparkler Engine in the Anzo Deployment and User Guide.
Limited Metadata Dictionary to 50k Concepts
To prevent a circumstance where a metadata dictionary is unintentionally created with an extremely large number of concepts that cannot be processed, Version 5.1.1 limits the number of concepts to 50,000 per dictionary.
Limited Number of Schemas Allowed Per Database Data Source
Version 5.1.1 limits the number of schemas that can be imported or created for one database data source to 5.
Added Response Timeout for AnzoGraph System Queries
Version 5.1.1 introduces a response timeout setting in the AnzoGraph connection configuration. If Anzo is waiting on a system information type response, such as CPU and memory usage statistics, from AnzoGraph, and AnzoGraph does not respond within the specified time, Anzo cancels the request rather than waiting indefinitely.
The new option, Request Deadline (Minutes), is available under the Advanced AnzoGraph connection options. The default value is 2 minutes. For information, see Connecting to AnzoGraph in the Anzo Deployment and User Guide.
Set Default ETL Engine to Sparkler
Version 5.1.1 sets the Default ETL Engine Config value to Sparkler so that the ETL engine is pre-populated with the Sparkler engine when users configure the Ingest workflow. For information about changing the default engine, see Configure the Default ETL Engine in the Anzo Deployment and User Guide.
Display Regex Annotation Class Names in Annotated Document Lens
When the Regex Annotator captured annotations, they were displayed under a generic "Regex Capture" class in Annotated Document lenses. In Version 5.1.1, new subclasses are created as defined in the Regex Annotator, and annotations are displayed under the appropriate class names in the Annotated Document lens.
Removed Insert Wildcard Option for XML Data Sources
Version 5.1.1 removes the Insert Wildcard option from the File Location dialog box that is presented when selecting files for XML data sources. Wildcards are not supported by the CData driver.
Expected Properties Missing from Class View
When one model defined class "A" and a second model defined property "P" with a domain of class "A," property "P" could be excluded from the list of properties when class "A" was viewed in a dashboard or a Data on Demand endpoint. Version 5.1.1 corrects the issue.
Improved Data on Demand Handling of Models with Recursive Hierarchies
Version 5.1.1 improves the handling of models with recursive hierarchies in Data on Demand endpoints. Previously a request could return a stack overflow error if a $metadata or class URL OData request was sent and the model included a circular subclass hierarchy.
Sparkler Engine Failed to Remove Copies of Shared Library
When the Sparkler compiler was used to compile ETL jobs, the compiler could fail to remove copies of the shared library that were no longer needed once the jobs were compiled. The leftover .jar files took up unnecessary space on the file system. Version 5.1.1 resolves the issue to ensure that shared library .jar files are removed from the file system after jobs have finished compiling.
Some File Handles Remained Open after Jobs Published
In some cases, open file handles were not closed for all jobs after a pipeline was published. This caused a "Too many open files" error after several pipelines were run in an environment. Version 5.1.1 resolves the issue to ensure that all open file handles are closed when jobs are completed.
Layer Required Refresh after Graphmart was Auto-Updated
Version 5.1.1 resolves an issue where a data layer was incorrectly tagged as needing a refresh even though the graphmart was configured to automatically update AnzoGraph when the data changed (Manual Refresh Graphmart was disabled).
Spark Status Updates Delayed by Unreachable Livy Server for Other ETL Engine
Version 5.1.1 corrects an issue where status updates were delayed for Spark jobs that were running if the Livy server was unreachable for another configured ETL engine.
NPE when Filtering out Null Values in OData Query
Version 5.1.1 resolves in issue that caused Anzo to return a null pointer exception when a user ran an OData query that included a filter to find the entities that were not null.
Could Not Resolve Data Location for HDFS File Store
AnzoGraph returned a "Could not resolve data location or data files" error when a user tried to activate a graphmart whose RDF files were on a HDFS file store. The problem was that Anzo connected to the HDFS RPC port but AnzoGraph tried to connect to the HTTP REST port. Version 5.1.1 resolves the issue by adding HTTP protocol settings to the HDFS file connection configuration so that users can provide the HTTP specifications that AnzoGraph needs to access HDFS. The new settings are Nameservice Rest IP or Name, Nameservice Rest Port, and Nameservice Rest Protocol. For details about the settings, see HDFS File Connection in the "Connecting to a File Store" topic in the Anzo Deployment and User Guide.
Local Sparkler Engine Generated Unnecessary SSO Provider Objects
When ETL jobs were compiled by the local Sparkler Engine, some unnecessary SSO provider objects were generated. Version 5.1.1 resolves the issue by generating one SSO provider token before the jobs are compiled rather than as jobs are being executed.
Anzo Version 5.1.0
This section describes the new features and changes to existing components that are introduced in Anzo Version 5.1.0.
New Features
- Pipeline Editions for Data Set Snapshots
- Data Source and Data Set Categories
- Native Support for Apache Parquet
- Separate Administration Application
- Dynamic Deployments of Anzo Unstructured Clusters
- Semantic Services Log
- Data Profile for Graphmarts
- Upload XML and JSON files from a Computer
- Default Anzo Server Data Store
- Option to Refresh the Dataset Catalog
- Option to Refresh AnzoGraph Status
- Cancel Profile Generation from Activity Log
General Improvements
- Hi-Res Analytics Application Redesign
- Option to Save File Uploads to the Shared File Store
- Added and Revised Application Tooltips and Descriptions
- Redesigned Data Profiling Reports
- Data Profile Execution Moved to AnzoGraph
- Usability Enhancements for Versioning and Restore Operations
- Usability Improvements for Search Operations
- Data Toolkit Improvements
- Report Additional Metadata for Resources
- Related Mappings and Pipelines Added to Schema View
- Redesigned and Combined Import and Create Buttons
- Auto-Select a File or Directory when it is the Only Option
- Redesigned Sharing Tab
- Option to Allow Empty Documents in Unstructured Pipelines
- Normalize Uppercase and Lowercase LDAP Names
- Renamed Advanced AnzoGraph Settings
- Improved Error Messaging for Login Failures
- Display Tags on Home Screen and Search Results
- Renamed Pipeline Publish Button
- Press Escape to Close Dialog Boxes
Metadata Dictionary Improvements
- Renamed Data Dictionary to Metadata Hub
- Automatically Merge Schema Tables to One Concept
- Ability to Select and Move Multiple Properties at Once
- Display Mapping and Model Locations for Dictionary Concepts
- Display Primary Keys for Concepts
Other Changes and Fixes
- Additional Jar Configuration Required for Local ETL Engines
- Removed Integer from Model Property Editor
- Default to Double Instead of Float for Non-Integer Numeric Types
- JDBC Driver Array Formatting Improvement
- Shortened JDBC Driver Generated Foreign Key Names
- Refactored Database Data Source Ontology
- Moved Database Data Source Connection Status
- Added Client Hostname Setting in AU Network Configuration
- Option to Separate Occurrences of Same Annotation
- Option to Use File Name as Document Title in Unstructured Pipelines
- Removed Anzo Connect from Permissions
- Removed Anzo for Excel Plugin
- Disallow Data Layer Editing During Graphmart Activation
- Warn if Graphmart Deactivated when Data Profile is Running
- Return ASK Results in Query Builder
- Warn when Minimum AnzoGraph Version Not Met
- Values not Returned for PARSEDATETIME against Graphmart
Pipeline Editions for Data Set Snapshots
In previous Anzo releases, data sets could only contain the most recent version of the data generated from a pipeline. Each time a pipeline was published, the existing data was overwritten by the latest version. Version 5.1.0 introduces Pipeline Editions for creating snapshots of the data that is published by a given pipeline. All runs of a pipeline can be preserved, and data sets can be assembled by users. A data set can include any subset of jobs in a pipeline and any published version of a job. For more information, see Managing Pipeline Editions in the Anzo Deployment and User Guide.
Data Source and Data Set Categories
Version 5.1.0 introduces the Category manager for data sources and data sets. The Categories feature provides a way to define custom metadata about a data set that can be used to classify or catalog the data. Categories describe the properties in a data source or data set but are independent of the instance data. When categories are configured, they are displayed as choices in the list of quick filters that are available when sorting resource lists. For more information about categories, see Configuring Data Source Categories and Configuring Data Set Categories in the Anzo Deployment and User Guide.
Native Support for Apache Parquet
Version 5.1.0 adds support for ingesting data from Apache Parquet files. For more information, see Creating a Parquet Data Source and Ingesting the Data in the Anzo Deployment and User Guide.
Known Limitations
The list below describes the limitations for the first release of Parquet data source support:
- Each Parquet data source supports one schema. You can ingest multiple files with the same schema in the same data source, but if you have files that are defined by different schemas, create one Parquet data source per schema.
- Metadata Dictionaries are not supported with Parquet data sources.
- Anzo generates a data model for Parquet sources but does not create a schema.
Separate Administration Application
Version 5.1.0 moves the Administration menu to a separate application. The new Administration icon (![]() ) in the top menu bar of the Anzo application opens the Administration menu.
) in the top menu bar of the Anzo application opens the Administration menu.

Clicking a menu option opens the Administration application for managing Anzo server settings, connections, users, and other components. For example:
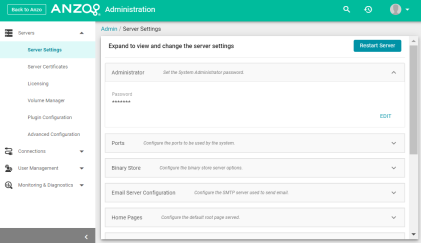
Because the main Anzo application and Administration application were separated, the URLs for both applications were modified. The base URL for the Anzo application was changed from http://<hostname>/sdl/index.html#/ to http://<hostname>/sdl/index.html#/main/ and the Administration application base URL is https://<hostname>/sdl/index.html#/admin.
For information about using the Administration application, see the Administration Guide in the Anzo Deployment and User Guide.
Dynamic Deployments of Anzo Unstructured Clusters
Version 5.1.0 adds support for dynamic, Kubernetes-based deployments of Anzo Unstructured (AU) clusters.
When dynamic deployments are enabled:
- Anzo users activate pre-configured Kubernetes environments on-demand without needing specific technical, cloud platform, or infrastructure provisioning skills.
- Right-sized AU clusters are automatically created and deleted in response to users' real-time requests, avoiding the need to keep instances running indefinitely and reducing the overall cost of maintaining the applications.
- Anzo provides a unified user interface for administrators to create and view all of the dynamic deployment options. Multiple cloud service providers can be managed through the same user interface.
For more information, see Setting Up Cloud Infrastructure for Dynamic Deployments in the Anzo Deployment and User Guide.
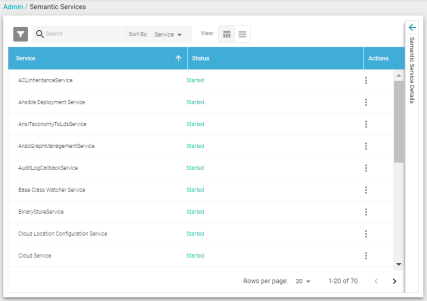
Semantic Services Log
Version 5.1.0 introduces a Semantic Services log in the Administration application. The log enables administrators to view the status of semantic services, review details about the services and their operations, and stop and restart services.
Data Profile for Graphmarts
Version 5.1.0 adds the option to create a data profile for a graphmart. In addition, you can configure a graphmart to automatically generate a profile upon activation.
Upload XML and JSON files from a Computer
When creating an XML or JSON data source, Version 5.1.0 adds the ability to select the files to import from your computer. Previously XML and JSON source files had to be hosted on a file store.
You can also configure Anzo to save uploaded files to a file store location. See Option to Save File Uploads to the Shared File Store for information.
Default Anzo Server Data Store
Version 5.1.0 adds a pre-configured default data store called Server Anzo Data Store. This data store points to the local Anzo file system. The default store was added so that first-time users can quickly test the onboarding process. It is not meant to be used in production, however. It is safe to delete this data store so that it is not presented as an option when users configure ingestion pipelines. For more information, see Creating an Anzo Data Store in the Anzo Deployment and User Guide.
Option to Refresh the Dataset Catalog
In Version 5.1.0, the Volume Manager was updated to provide options to rebuild and clean up the Dataset catalog. The new options are at the bottom of the Configuration screen for a volume.
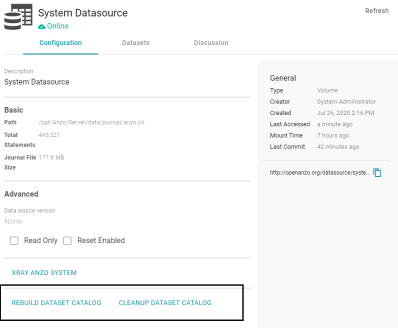
Rebuild Dataset Catalog regenerates all the catalog entries based on their linked data set. And Cleanup Dataset Catalog removes any catalog entry that no longer has an associated linked data set.
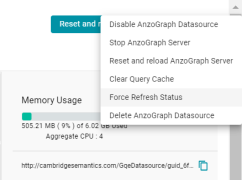
Option to Refresh AnzoGraph Status
Version 5.1.0 adds a Force Refresh Status option to the menu on the AnzoGraph screen in the Administration application. Forcing a status refresh queries the AnzoGraph system tables to retrieve the latest information about memory usage and server details, such as the total number of statements in the database, and refresh the values displayed on the AnzoGraph screen.
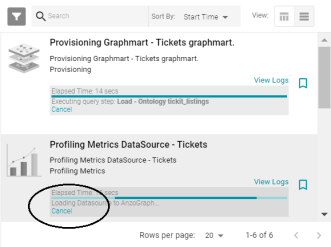
Cancel Profile Generation from Activity Log
In Version 5.1.0, when generating a data source, data set, or graphmart profile, the Activity Log includes the option to stop the profiling process by clicking Cancel under the progress bar for the task. For example:
Hi-Res Analytics Application Redesign
Version 5.1.0 redesigns the skin for the Hi-Res Analytics application to give the application a more modern and minimalistic look and feel. To get an overview of the types of changes the update includes, see the images in Introduction to Hi-Res Analytics in the Anzo Deployment and User Guide.
Option to Save File Uploads to the Shared File Store
By default, if a user creates a file-based data source and uploads the source file (such as a CSV, XML, or JSON file) to Anzo from their computer, the file is copied to a directory under the Anzo server's data directory. When the file is in the server installation path, however, it is not accessible by other applications, such as AnzoGraph or Spark. In addition, other users cannot publish pipelines for that data source because they typically do not have access to the file. Version 5.1.0 adds the option to configure Anzo to copy uploaded files to a location on the shared file store so that they are available to other applications. For more information, see Setting a Base File Store Path for File Uploads in the Anzo Deployment and User Guide.
Added and Revised Application Tooltips and Descriptions
To provide more guidance for users, Version 5.1.0 adds more tooltips and messages throughout the Anzo application. This release also revises many of the field descriptions to make them more complete and informative.
Redesigned Data Profiling Reports
In Version 5.1.0, the Generate Metrics buttons are renamed to Profile Data, and the reports that are generated have been redesigned to make them easier to see and analyze and to offer more information.
Data Profile Execution Moved to AnzoGraph
In Version 5.1.0, the execution of all data source, dataset, and graphmart data profiling occurs in AnzoGraph. Performing the computations in AnzoGraph increases the performance of metrics generation and avoids the strain on Anzo resources.
Since AnzoGraph now performs data source profiling, that means AnzoGraph needs to connect directly to any data sources that you profile. For file-based data sources, AnzoGraph uses the Graph Data Interface (GDI) Java plugin to access the sources. The plugin, datatoolkit-2.0.0.jar, needs to be copied to the <install_path>/lib/udx directory on the AnzoGraph leader server.
For database data sources, AnzoGraph requires the GDI plugin plus the same drivers that you have configured to access those sources in Anzo. To configure AnzoGraph to profile database data sources, copy the necessary driver .jar files to the <install_path>/lib/udx directory on the AnzoGraph leader server and restart the database.
Usability Enhancements for Versioning and Restore Operations
Version 5.1.0 includes usability enhancements for versioning and restore operations. The changes improve the workflow and messaging for users who do not have permissions to view or modify all of entities that are related to a version.
Usability Improvements for Search Operations
Version 5.1.0 implements a more basic CONTAINS search method, which enhances the usability of the search feature throughout the Anzo application. For example, in previous versions if a data set was named "Data - CSI - DOC" and a search for "doc" was performed, the data set would not be found. In Version 5.1.0 simple searches like the example yield results.
Data Toolkit Improvements
In Version 5.1.0, the Data Toolkit Service, now called the Graph Data Interface (GDI), was updated to add support for querying remote data source metadata. The GDI plugin was also moved from Anzo to AnzoGraph to increase query performance and reduce the impact on Anzo server resources. For more information, see Blending Data from Remote Sources in the Anzo Deployment and User Guide.
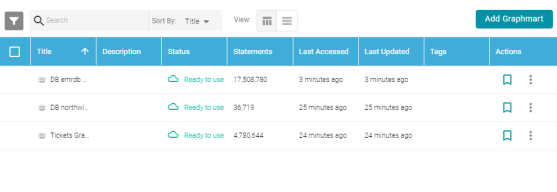
Report Additional Metadata for Resources
In Version 5.1.0, additional metadata is displayed in the Anzo application for resources such as graphmarts, data sources, datasets, and metadata dictionaries. Resource lists now include information about when the resource was last accessed or updated. For example, the graphmart list below includes Last Accessed and Last Updated columns:
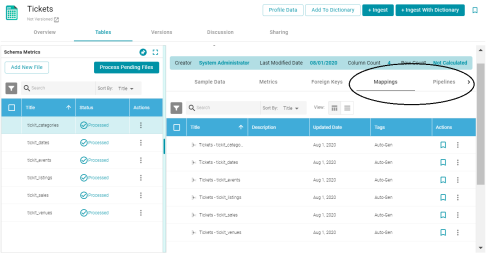
Related Mappings and Pipelines Added to Schema View
Version 5.1.0 adds Mappings and Pipelines tabs to the schema details view. Including these tabs enables users to see the mappings and pipelines that are related to the schema. The image below shows the location of the tabs.
Redesigned and Combined Import and Create Buttons
In Version 5.1.0, the Import and Create buttons throughout the Anzo application were replaced with an Add... button. When importing or creating a resource, you click the Add button and select the action to take from a menu that is displayed.
Auto-Select a File or Directory when it is the Only Option
In Version 5.1.0, when a user navigates to a file or directory in the Select Files dialog box, Anzo will automatically select the appropriate file or directory if it is the only valid option for the dialog. For example, when adding RDF files to the Dataset catalog, Anzo will auto-select the rdf.ttl or rdf.ttl.gz directory.
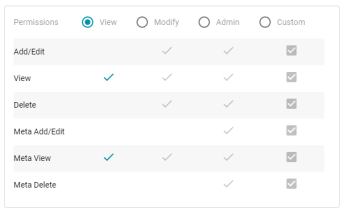
Redesigned Sharing Tab
Version 5.1.0 redesigns the Sharing tab across the Anzo application. The new screen uses radio buttons instead of tabs to clarify which base permission is being assigned. For example:
Option to Allow Empty Documents in Unstructured Pipelines
In Version 5.1.0, a new Allow Empty Documents option was added to the unstructured pipeline Advanced configuration settings (highlighted in the image below). When this option is enabled, zero-byte documents will be processed instead of logging an error when the pipeline is run.
![]()
Normalize Uppercase and Lowercase LDAP Names
In previous versions, duplicate user accounts were created in Anzo if an LDAP distinguished name had both a lowercase and uppercase version. Version 5.1.0 adds the option to configure the system to normalize distinguished name strings so that values that differ only in capitalization are treated as the same value. For more information, see Normalizing LDAP Names in the Anzo Deployment and User Guide.
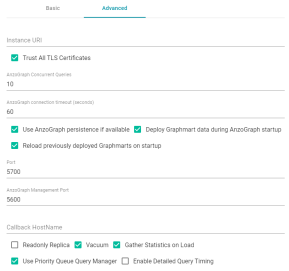
Renamed Advanced AnzoGraph Settings
In previous releases, the Advanced settings on the AnzoGraph configuration screen could be confusing because a user needed to select an option if they wanted to disable the feature, for example, "Disable Gather Statistics." Version 5.1.0 renames the settings to clarify the options.
Improved Error Messaging for Login Failures
Version 5.1.0 standardizes messaging for authentication failures across all SSO providers. It also ensures that consistent messages are returned for non-SSO login failures.
Display Tags on Home Screen and Search Results
In Version 5.1.0, if users add tags to artifacts, those tags are now displayed with the artifacts on the Home page as well as in global search results that find those artifacts.
Renamed Pipeline Publish Button
To distinguish between the functionality of the Publish button at the top of a Pipeline screen and the Publish button that is displayed above the job list when specific jobs are selected, the button at the top of the screen was renamed to Publish All since it is configured (by default) to publish all of the jobs in the pipeline.
Press Escape to Close Dialog Boxes
In Version 5.1.0, pressing the Esc key can be used to close dialog boxes in the Anzo application.
Renamed Data Dictionary to Metadata Hub
In Version 5.1.0, the Data Dictionary option under the Onboard menu is renamed to Metadata Hub.
Automatically Merge Schema Tables to One Concept
In Version 5.1.0, when creating a new dictionary from a schema, users have the option to merge the tables in the schema into a single class concept. For example, if the data source is multiple CSV files where each file (table in the schema) contains the data for a single study in a group of studies, enabling the new Nest all Concepts under a single Class Concept option would merge all of the properties from each file into one class. For more information, see Creating a Metadata Dictionary from a Schema in the Anzo Deployment and User Guide.
Ability to Select and Move Multiple Properties at Once
In Version 5.1.0, when splitting concepts in a metadata dictionary, users can now select multiple properties to drag and drop.
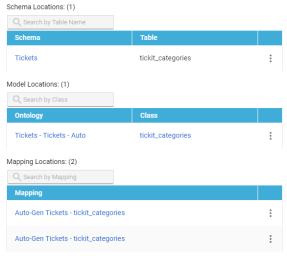
Display Mapping and Model Locations for Dictionary Concepts
In Version 5.1.0, after you ingest a data source with a dictionary, the dictionary is updated to include information about the model, mapping, and schema locations for the selected concept or property. For example:
The locations include an actions menu (![]() ) that enables you to delete the pointer to the location for that concept. Deleting a pointer does not remove the mapping, model, or schema.
) that enables you to delete the pointer to the location for that concept. Deleting a pointer does not remove the mapping, model, or schema.
Display Primary Keys for Concepts
In Version 5.1.0, metadata dictionaries display the primary keys for concepts. The dictionary also includes the option to create or remove primary keys. Note that updating keys in a dictionary does not alter the source schema.
Additional Jar Configuration Required for Local ETL Engines
In previous versions, when Anzo was configured to use JDBC drivers to connect to relational databases, the file system locations for those drivers did not need to be explicitly defined for the local Spark and Sparkler ETL engines. In Version 5.1.0, local engines need to be configured in the same way as remote Spark clusters; the path to any drivers must be specified in the Additional Jars field on the Run tab for the local Spark and Sparkler engines. For more information, see Configuring a Spark ETL Engine and Configuring a Sparkler Compiler in the Anzo Deployment and User Guide.
Removed Integer from Model Property Editor
When configuring the Property Range for a property in the model editor, the list of data types included both Int and Integer. Integer is a BigInt data type that is not natively supported in AnzoGraph. To ensure that integer properties are correctly set to Int, Version 5.1.0 removes Integer from the list of data types to choose from.
Default to Double Instead of Float for Non-Integer Numeric Types
When ingesting data in Version 5.1.0, non-integer numeric data types default to xsd:double instead of xsd:float.
JDBC Driver Array Formatting Improvement
Since the JDBC driver does not have support for multi-valued columns, arrays of values are returned for requests that include multi-valued columns. The formatting of multi-value arrays, however, could include unnecessary new lines that caused issues in tools such as Informatica. Version 5.1.0 removes the additional formatting for multi-value arrays so that the driver returns a simple array of values.
Shortened JDBC Driver Generated Foreign Key Names
The auto-generated foreign key names that the JDBC driver created could be longer than 128 characters, depending on the graphmart name, Data on Demand endpoint name, and class names. The long names could cause an issue when using the JDBC driver with tools such as Informatica. In Version 5.1.0, the JDBC driver has been updated to ensure that generated foreign key names are unique but not longer than 128 characters.
Refactored Database Data Source Ontology
In Version 5.1.0, the internal ontology for database data sources was refactored to treat each database type as a subclass. Previously, each database type was a property under one database source class.
When upgrading to Version 5.1.0, the upgrade process automatically updates any existing data sources that were created using Anzo's standard pipelines. However, there are two cases where your data source must be upgraded separately:
- If you plan to add a volume from a previous release to an Anzo 5.1.0 server, the volume must be upgraded to use the new format before it is added to Anzo. Contact Cambridge Semantics Support to request a script to upgrade your volumes.
- If you use custom JDBC drivers, the TriG for those drivers must be modified to provide the new information that the ontology requires. Specifically, a Database DataSource that extends DbDataSource needs to be created. And the corresponding DbType record needs to point to the newly created Database DataSource. Contact Cambridge Semantics Support for guidance on creating the necessary .trig file.
Moved Database Data Source Connection Status
When viewing database data sources in previous Anzo versions, the connection status for the source was displayed at the top of the screen under the data source name. For example:
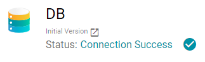
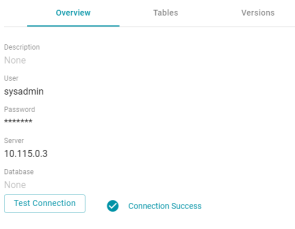
In Version 5.1.0, the Status field is removed from the top of the screen. You can view the connection status by clicking the Test Connection button on the Overview tab for the data source. For example:
Added Client Hostname Setting in AU Network Configuration
To accommodate dynamic deployments of Anzo Unstructured (AU) clusters, a new setting, called Distributed Pipeline Client Hostname, was added to the network configuration for static AU clusters. For static deployments, the new field lists the hostname or IP address of the AU leader instance. For more information, see Configure Network Connections to an Anzo Unstructured Distributed Cluster in the Anzo Deployment and User Guide.
Option to Separate Occurrences of Same Annotation
By default, unstructured pipeline annotators combine multiple instances of the same annotation into one overall record that references each occurrence of the annotation within a document. Version 5.1.0 adds the option to configure an annotator to keep each annotation separate so that additional metadata for each annotation is not lost. The new property is called Is Combine Annotation Instances, and it is available as an Advanced option in the annotator configuration.
Option to Use File Name as Document Title in Unstructured Pipelines
When configuring an unstructured pipeline in Version 5.1.0, there is a new Advanced option called Use File Names as Document Titles. This option enables users to choose whether file names are used as the Document Title for all documents or whether the Document Title is acquired from metadata in the file.
- When Use File Names as Document Titles is enabled, document file names will be used for all Document Titles in the Document Search lens results for that pipeline.
- When Use File Names as Document Titles is disabled, the Document Search lens will display the Document Titles that come from metadata in the files. If a document lacks a title, then the file name will be used as the Document Title.
Removed Anzo Connect from Permissions
Version 5.1.0 removes the "Anzo Connect" option from permissions since the component is no longer used in Anzo. For information about the existing permissions, see Permissions Reference in the Anzo Deployment and User Guide.
Removed Anzo for Excel Plugin
In Version 5.1.0, the Anzo for Excel plugin was removed from the Anzo Software Installation Packages page (accessed from https://<Anzo_server_IP>/installs/). The Anzo for Excel component is no longer used.
Disallow Data Layer Editing During Graphmart Activation
In Version 5.1.0, the data layers in a graphmart are read-only while that graphmart is being activated, refreshed, or reloaded.
Warn if Graphmart Deactivated when Data Profile is Running
In Version 5.1.0, users are presented with a warning that profile metrics will be canceled if they attempt to deactivate a graphmart while a data profile that uses that graphmart is being generated.
Return ASK Results in Query Builder
In previous versions, the Query Builder failed to return results when an ASK query was run. Version 5.1.0 resolves the issue so that "true" or "false" is displayed when an ASK query is run in the Query Builder.
Warn when Minimum AnzoGraph Version Not Met
In Version 5.1.0, when configuring a connection to AnzoGraph, the Administration application will warn the user if the version of AnzoGraph does not meet the minimum requirements for use with Anzo 5.1.x.
Values not Returned for PARSEDATETIME against Graphmart
Version 5.1.0 fixes an issue that prevented values from being returned when the PARSEDATETIME function was used to convert strings to dateTime values in a graphmart. If the string did not include a timestamp, the result would not be displayed. In Version 5.1.0, if a value is missing the timestamp, Anzo adds "T00:00:00Z" to the value and displays the results.