Exporting Data to an FLDS (Export Step)
This topic provides guidance on configuring an Export Step to use for exporting the knowledge graphs in memory to a file-based linked data set (FLDS) on the shared file store. Follow the steps below to create an Export Step.
If you add an Export Step to a graphmart that has been activated, you must reload the entire graphmart after adding the step. Simply refreshing the layer or graphmart after adding the step does not create the ontology graph that the Export Step requires.
- Go to the graphmart for which you want to add a step and then click the Data Layers tab.
- On the Data Layers tab, find the layer that you want to add the step to. Click the menu icon (
 ) for that layer and select Add Step/View. The Add Step/View dialog box is displayed with the New tab selected.
) for that layer and select Add Step/View. The Add Step/View dialog box is displayed with the New tab selected.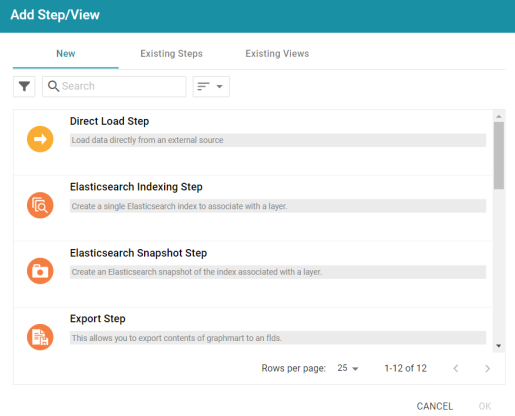
- To create a new Export step, select Export Step and then click OK. If you want to clone an existing step, click the Existing Steps tab, select the step that you want to clone, and then click OK. Anzo creates or clones the step and displays the Details tab:
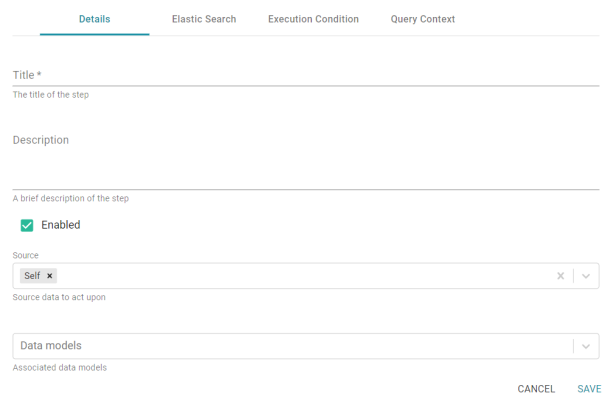
- On the Details tab, configure the following options as needed:
- Title: The required name of the step.
- Description: An optional short description of the step.
- Enabled: When creating a new step, the Enabled option is selected by default, indicating that the step is enabled and will run when the layer is loaded or refreshed. If you want to disable the step so that it is not processed, clear the Enabled checkbox.
- Source: The source data that this step should act upon. Steps can build upon the data generated by steps in other layers or can be self-contained, applying changes that relate only to the data defined in the layer that contains this step. You can select any number of the following options:
- Self: This option is selected by default and means that the step runs against only the data that is generated in the layer this step belongs to.
- All Previous Layers Within Graphmart: This option means that the step runs against the data that is generated by all of the successful layers that precede the layer this step is in. Any failed layers are ignored.
- Previous Layer Within Graphmart: This option means that the query runs against only the data that is generated by the one layer that precedes the layer this step is in.
- Layer Name: The Source drop-down list also includes options for specific layer names. You can choose a specific layer to act upon the data in that layer only.
- Data models: This optional field specifies the model or models to associate with this step. The list displays all of the available models. By default, the field is set to Exclude System Data (
 ). If you want to choose a system model, click the toggle button on the right side of the field to change it to Include System Data (
). If you want to choose a system model, click the toggle button on the right side of the field to change it to Include System Data ( ). When system data is included, the drop-down list displays the system models in addition to the user-generated models.
). When system data is included, the drop-down list displays the system models in addition to the user-generated models. - Target FLDS: This is the target FLDS for this export. If an FLDS does not exist, you can select -Create New- to create an empty dataset. See Adding an Empty Dataset for an Export Step for instructions. If you select an existing target FLDS, you also have the option to specify whether or not to overwrite the existing dataset.
- Overwrite FLDS: This setting controls whether the existing FLDS is replaced with the exported files each time the Export Step runs or whether the exported files are added to the existing FLDS:
- If you want Anzo to replace the current edition of the dataset, select the Overwrite FLDS checkbox. When Overwrite FLDS is enabled, Anzo archives the existing files in a new timestamped export subdirectory directory under the Target FLDS directory. Each time the Export step runs, Anzo archives the current edition, and creates a new export directory. If you add this dataset to a graphmart, only the latest version of the exported data will be loaded to AnzoGraph.
- If you want Anzo to add the exported files to the existing FLDS, leave the Overwrite FLDS checkbox unchecked. When Overwrite FLDS is disabled, Anzo adds all of the exported components to a cumulative export directory under the Target FLDS directory. The dataset will contain the original files as well as all cumulative working editions. If you subsequently add this dataset to a graphmart, all of the data from all of the subdirectories will be loaded into AnzoGraph.
- Export Binary Store Contents: This option applies to exports of unstructured graphmarts and controls whether the binary store is exported along with the data.
- Always Move Binary Store: This option also applies to exports of unstructured graphmarts and controls whether the binary store is moved or copied during the export. Since the binary store can be large and have a nested structure, copying the data can take a very long time. Since moving the binary store is almost instantaneous, however, enabling Always Move Binary Store can reduce the time it takes to complete the export.
- Export Elasticsearch Contents: This option is enabled by default and controls whether Elasticsearch contents, such as associated indexes, are copied to disk in the Target FLDS. If you do not want Elasticsearch contents to be exported to the FLDS, clear the checkbox.
When exporting data from an AnzoGraph instance that does not have an associated Elasticsearch connection, clear the Export Elasticsearch Contents checkbox.
- Keep Elasticsearch Index Online: This option controls whether the Elasticsearch index that is associated with the dataset remains stored in Elasticsearch or is removed from Elasticsearch once it is exported.
For information about advanced Elasticsearch options that are available for Export Steps, see Elastic Search Tab below.
- Generate Metrics: This option controls whether a data profile is generated before the data is exported. Enabling this option increases the time it takes to run the step, but enabling it ensures that the information on the Dataset Explore is complete if the dataset is viewed. If you load the exported files in the future, the data profile is also loaded.
- Do Not Create New Edition in Dataset on Export: This option controls whether or not a new edition is created for the dataset each time the Export Step is run. By default this option is disabled, which means each export results in a new edition. If you do not want a new edition to be created on each export, select the Do Not Create New Edition in Dataset on Export checkbox.
- Maximum Number of Components in Edition: This option controls the maximum number of components to retain in an edition. The default value is blank, which means unlimited. If you specify a number in this field and the limit is reached, Anzo ages off the oldest components as new ones are created.
- Click Save to save the step configuration.
Once the Details tab is configured, the step can be run. If you added the step to an active graphmart, make sure that you deactivate and then reactivate the graphmart. Simply refreshing the layer or graphmart after adding the step does not create the ontology graph that the Export Step requires. For information about running this step conditionally by setting up an execution condition, see Defining Execution Conditions.
Once the graphmart is reactivated, the new dataset becomes available in the Datasets catalog.
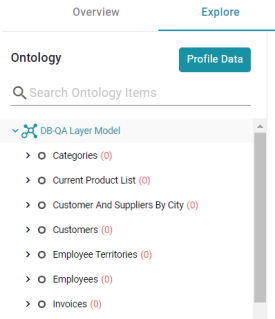
Unless you enable Generate Metrics, when you view in the Datasets catalog a dataset that was created by an Export Step, the counts in the Ontology panel on the Explore tab remain 0 until a Data Profile is generated for the dataset. For information about generating a profile, see Generating a Dataset Data Profile. For example, the image below shows the Explore tab for a dataset that was created by an Export Step and has not been profiled.
Elastic Search Tab
The Elastic Search tab contains optional settings that you can use to set any desired limits on Elasticsearch indexing processes.
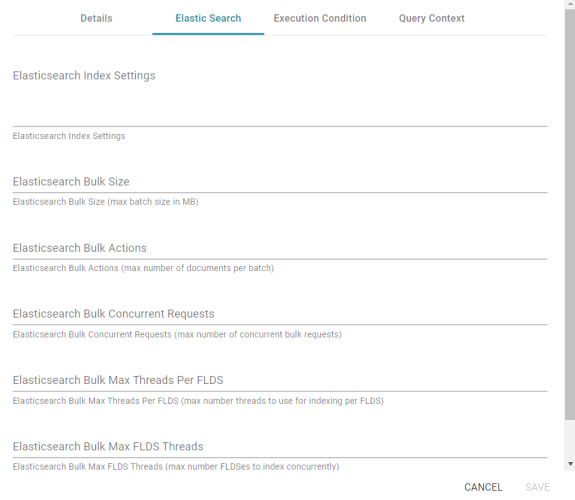
Elasticsearch Index Settings
A custom JSON list of any Elasticsearch index settings that you want to apply to the export.
Elasticsearch Bulk Size
The maximum batch size in MB.
Elasticsearch Bulk Actions
The maximum number of documents to include in each batch.
Elasticsearch Bulk Concurrent Requests
The maximum number of bulk requests that can run concurrently.
Elasticsearch Bulk Max Threads Per FLDS
The maximum number of threads to use for indexing per file-backed linked data set (FLDS).
Elasticsearch Bulk Max FLDS Threads
The maximum number of FLDSes to index concurrently.