Defining a Database Schema
This topic provides information about creating the schema to use when importing data from a database. The schema defines the source data to onboard. Anzo supports multiple options for defining the schema. You can import a schema from the database, you can write a static SQL query that defines the data, or, if you want to import data incrementally, you can write an incremental SQL query that includes parameters that automatically increment when the ETL pipeline is run. Select an option from the list below for instructions on creating that type of schema:
Importing a Predefined Schema
Follow the steps below to import a predefined schema from the database to Anzo. For instructions on writing a schema query, see Creating a Schema from an SQL Query below.
- From the Overview screen (as shown in the last step of the procedure above), click the Tables tab. Anzo displays the Tables screen. For example:
- Click the Import Schemas button. Anzo displays the Import Schemas dialog box, which lists any predefined schemas in the database. For example:

If you do not see a schema that you expect to see, make sure that you have the necessary access to the data source.
- Select the checkbox next to each schema that you want to import, and then click OK. Anzo imports the selected schema or schemas and lists the imported schemas on the Tables screen. For example:
Once the schema or schemas are imported, the source data can be onboarded to Anzo. For instructions on onboarding the data by letting Anzo automatically generate the mapping, model, and ETL pipeline, see Ingesting Data into Anzo.
Creating a Schema from an SQL Query
Follow the instructions below to create a schema by writing an SQL query that defines the data to onboard.
| Tip | For better ETL pipeline performance, it is beneficial to include joins and/or filters in schema queries rather than configuring those operations at the mapping level. For more information, see Performance Considerations for Database Pipelines. |
- From the Overview screen (as shown in the last step of Connecting to a Database), click the Tables tab. Anzo displays the Tables screen. For example:
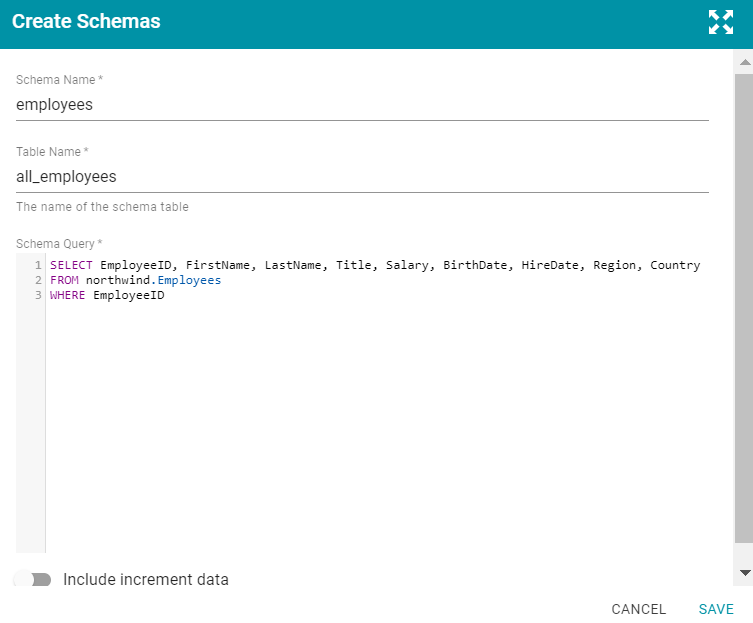
- Click the Create Schemas From Query button. Anzo displays the Create Schemas dialog box:

- In the Create Schemas dialog box, specify a name for the schema in the Schema Name field.
- In the Table Name field, specify a name for the schema table that the query will create.
- Type the SQL statement in the text box. The statement can include any functionality that the source database supports. Anzo does not validate the SQL. For example:
For information about writing a schema query that onboards data from a database incrementally, see Creating an Incremental Schema below.
- Click Save to save the query. Anzo creates the new schema and adds it to the list of schemas on the Tables screen. For example:
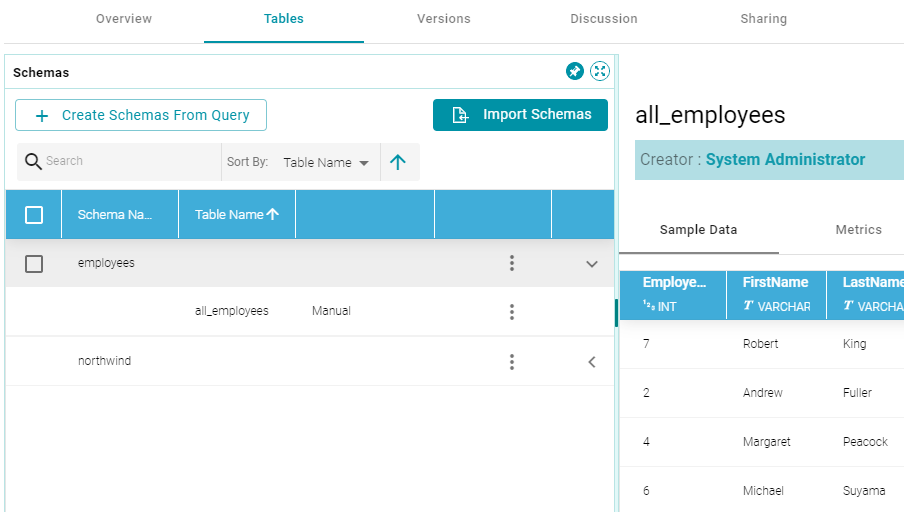
Once the schema or schemas are created, the source data can be onboarded to Anzo. For instructions on onboarding the data by letting Anzo automatically generate the mapping, model, and ETL pipeline, see Ingesting Data into Anzo.
Creating an Incremental Schema
Anzo provides the option to create a schema that is configured to import only the data that has been added to the data source since the last time the data was onboarded. This section provides instructions for writing a schema query to import data incrementally and gives an overview of the workflow to onboard the data.
| Important | Anzo onboards new source data only; it does not process data that was updated or deleted in the source database. Running the ETL job for an incremental schema query replaces the existing data with the newly onboarded data. What happens to the existing data in an FLDS when I run an incremental ETL job? |
Writing an Incremental Schema Query
| Tip | For better ETL pipeline performance, it is beneficial to include joins and/or filters in schema queries rather than configuring those operations at the mapping level. For more information, see Performance Considerations for Database Pipelines. |
- In the Anzo console, expand the Onboard menu and click Structured Data. Anzo displays the Data Sources screen, which lists any existing data sources. For example:
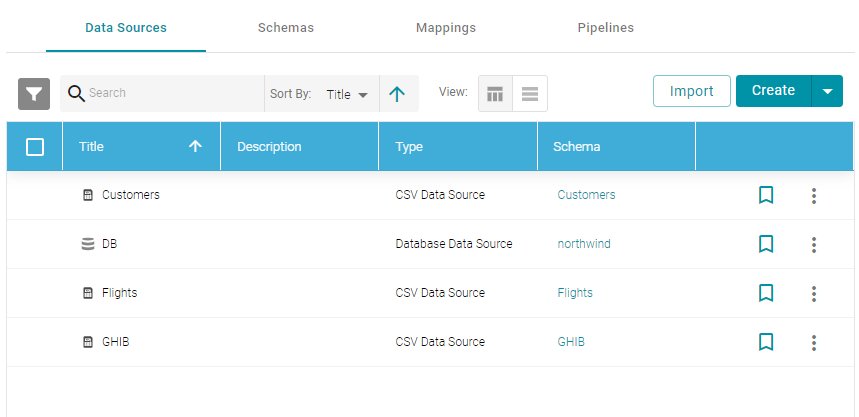
- On the Data Sources screen, click the database data source for which you want to create an incremental schema. Anzo displays the Tables screen for that source. For example:
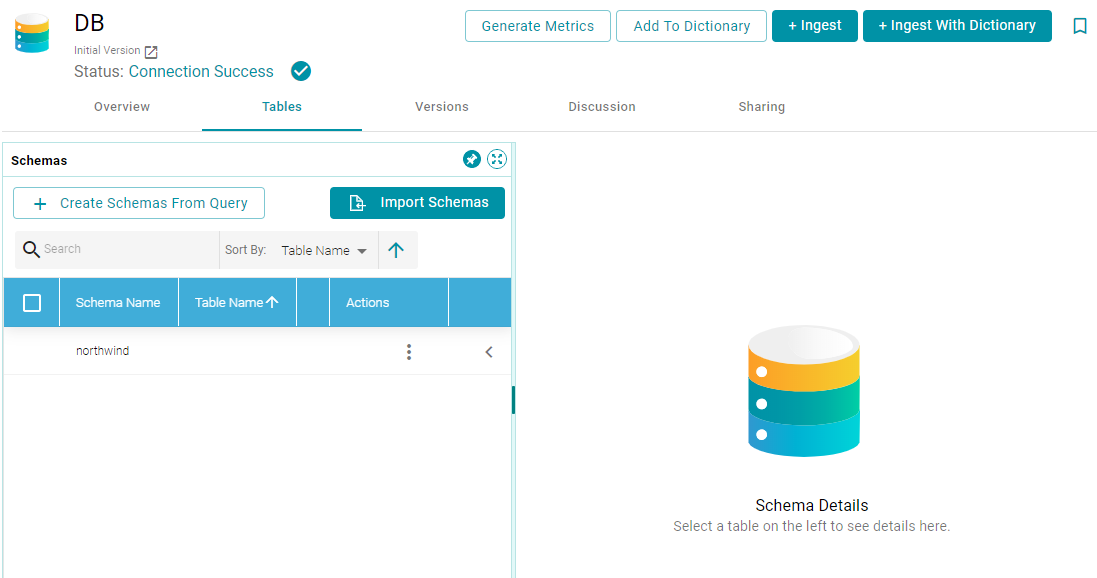
- Click the Create Schemas From Query button. Anzo displays the Create Schemas dialog box:
- In the Create Schemas dialog box, specify a name for the schema in the Schema Name field.
- In the Table Name field, specify a name for the schema table that the query will create.
- At the bottom of the screen, enable the Include increment data option by sliding the slider to the right. Anzo displays additional settings. For example:

- Populate the following fields so that you can use the values as a guide for writing the schema query:
- Incremental Column Name: The source column whose value will be used to increment the data.
- Value: The value in the column to use as the stopping point for the current import process and the starting point for the next import.
Note Do not include quote characters in the Value field. If the SQL query requires quotes around values, such as ‘2010-01-01’ or ‘TestValue’, include the quotes around the {INCREMENTVALUE} parameter in the query and not in the Value field. For example, if the value to increment on is ‘2010-01-01’, specify 2010-01-01 in the Value field and add the quotes to the query like the following example: SELECT * FROM Orders WHERE OrderData > ‘{INCREMENTVALUE}’ - Comparator: The operator to use for comparing source values against the value above.
- In the query text field, type the SQL statement that will target the appropriate source data. The WHERE clause must include the incremental column name, the comparison operator, and an {INCREMENTVALUE} parameter that is substituted with the Value at runtime. For example:
SELECT EmployeeID, FirstName, LastName, Title, Salary, BirthDate, HireDate, Region, Country FROM northwind.Employees WHERE EmployeeID > {INCREMENTVALUE}Make sure that the query includes the INCREMENTVALUE parameter and uses the same Incremental Column Name and Comparator values as the settings. For example:

- Click Save to save the query. Anzo creates the new schema and adds it to the list of schemas on the screen. For example:

Once the schema or schemas are created, the source data can be onboarded to Anzo. For instructions on onboarding the data by letting Anzo automatically generate the mapping, model, and ETL pipeline, see Ingesting Data into Anzo. See Running an Incremental Pipeline below for important information about running a pipeline that includes an incremental schema.
Running an Incremental Pipeline
When an incremental schema is added to an ETL job, a clock icon (![]() ) is displayed when hovering over the component in the job. For example:
) is displayed when hovering over the component in the job. For example:
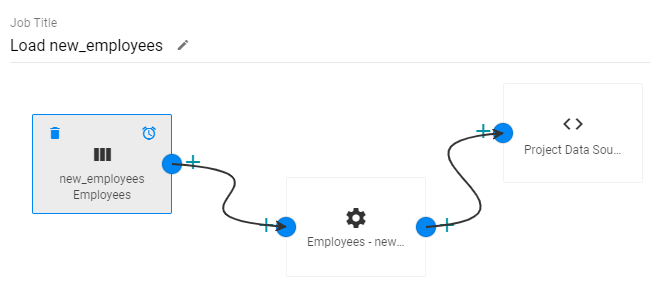
Clicking the clock icon opens the Incremental Load dialog box, which lists the Incremental Column Name, Value, and Comparator from the schema query. For example:
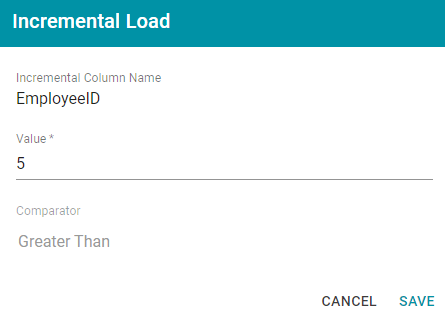
Publishing the job for this example will onboard only the records for which the EmployeeID is greater than 5. When the job is finished, Anzo adjusts the incremental load value to list the last value that was onboarded for the incremental column. Every time the pipeline is published, Anzo changes the incremental load value parameter to the highest or lowest value for the column, depending on the Comparator.
For example, viewing the Incremental Load dialog box after running the job above shows that the last EmployeeID value that was onboarded was 14:
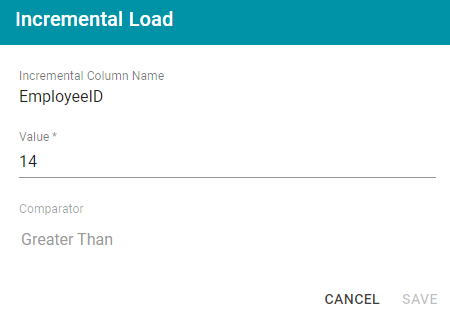
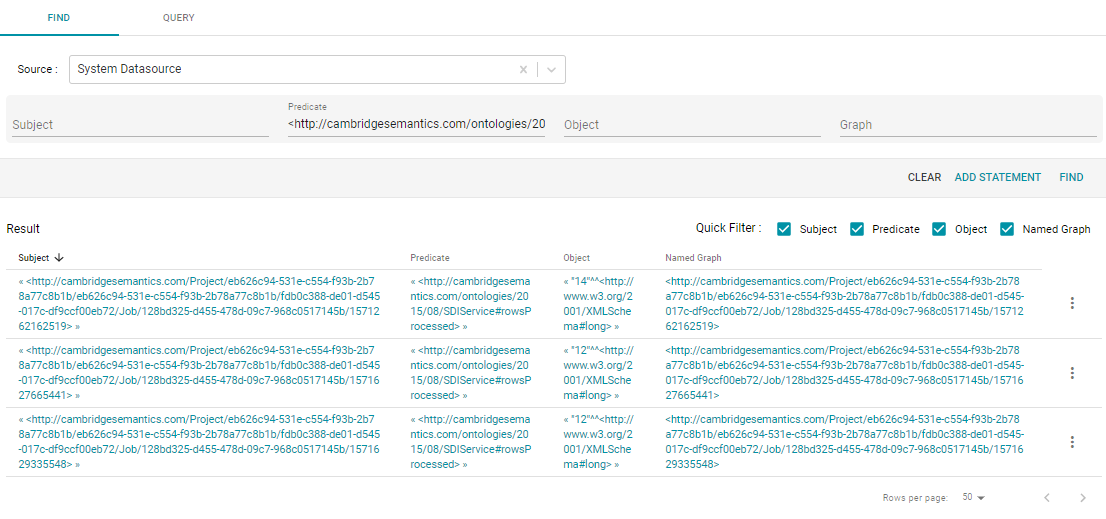
The next time this job is run, Anzo will onboard only the records where EmployeeID is greater than 14. To view the number of rows processed after running a job, you can search the System Datasource for the following predicate on the Find tab in the Query Builder:
<http://cambridgesemantics.com/ontologies/2015/08/SDIService#rowsProcessed>
The Object column shows the number of rows processed each time the pipeline was run. For example: