Configuring a Load Data Step
This topic provides guidance on configuring a Load Data Step to use for adding a Dataset to a Graphmart. The sections below describe each of the tabs and configuration options that are available when you create or edit a Load Data Step.
Details
The Details tab includes all of the required settings that configure options such as the name of the step and the Dataset to load.
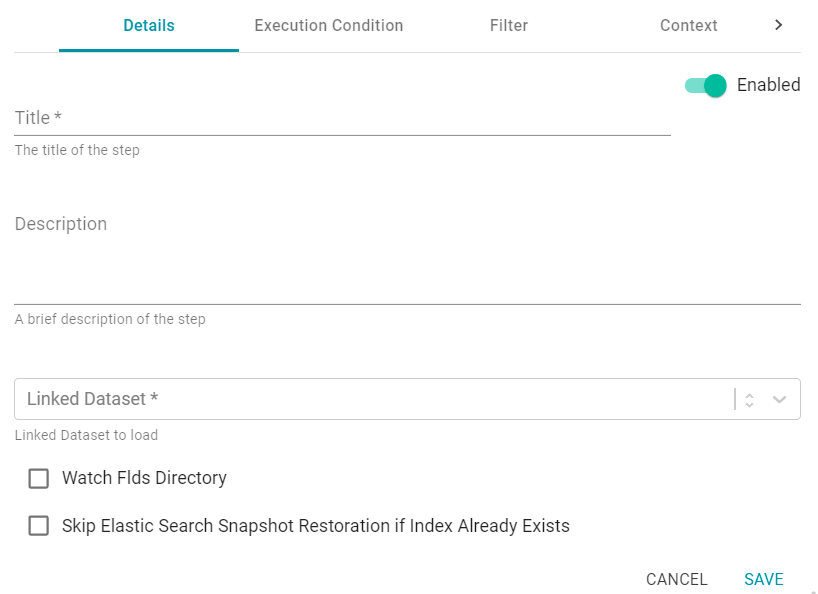
Title
The required name of the Step.
Description
And optional description of the Step.
Enabled
When creating a new Step, the Step is Enabled by default, indicating that the Step will run when the Data Layer is loaded or refreshed. If you want to disable the Step so that it is not processed, slide the Enabled slider to the left.
Linked Dataset
This field specifies the Dataset that you want this Step to load. The list displays all of the Datasets in the Dataset catalog. By default, the field is set to Exclude System Data ( ). If you want to choose a system dataset, click the toggle button on the right side of the field to change it to Include System Data (
). If you want to choose a system dataset, click the toggle button on the right side of the field to change it to Include System Data ( ). The Linked Dataset drop-down list will display the system datasets in addition to the Datasets in the catalog.
). The Linked Dataset drop-down list will display the system datasets in addition to the Datasets in the catalog.
If this is a new Load Data Step, the current working edition (Managed Edition) of the Dataset is selected. If you want to select a different Edition, you can click Modify Edition and follow the steps in Modifying an Edition.
Watch FLDS Directory
If you want this Step to watch the FLDS directory on the file store and indicate when any of the load files change, select the Watch FLDS Directory checkbox. If Watch FLDS Directory is enabled and changes are detected in the FLDS directory, Anzo will mark this Step (and Data Layer) as needing a refresh.
Skip Elastic Search Snapshot Restoration if Index Already Exists
This option applies to loads of Unstructured Datasets and controls whether Anzo first checks to see if an index with the alias for the Dataset already exists in Elasticsearch. If it does exist, Anzo will not reload the index snaphsot into Elasticsearch.
Execution Condition
If you want this Step to be executed conditionally, based on the result of a specified Validation Condition, you can configure an Execution Condition on the Execution Condition tab that is available when creating or editing a Step. The image below shows the Execution Condition tab.
In order to set up an Execution Condition, the Graphmart needs to have at least one Validation Step that defines a Condition Variable. Condition Variables can be used across all Data Layers in the Graphmart. For guidance on configuring a Validation Step, see Configuring a Validation Step.

Enable Layer Based on Boolean Condition
This setting indicates whether to enable this Step only if the returned value from the Validation Condition is either true or false. You specify true or false in the Conditional Variable If Result field. If the Validation Condition fails, the Step is disabled.
Conditional Variable
This field specifies the variable that you want to base this Execution Condition on. The variable is the result of a Validation Step Query in the Graphmart.
Conditional Variable If Result
If you enabled the Enable Layer Based on Boolean Condition setting, select true or false from the drop-down list. The Step will be enabled only if the result of the Validation Step Query matches the value that you specified. If Enable Layer Based on Boolean Condition is disabled, leave this field blank.
Filter
The Filter tab includes options for filtering out some of the data in the Dataset. If you want to load all of the statements in the Linked Dataset that you chose on the Details tab, do not configure Filter options. If you want to exclude some statements, configure the Filter options.
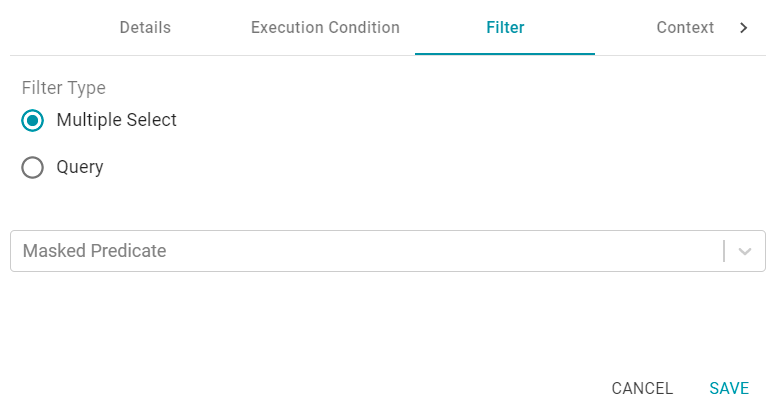
Multiple Select
This option enables you to exclude certain triples from the load by selecting the predicates to filter out. These are known as Masked Predicates, which can also be configured at the Data Layer level (as described in Masking Data in a Data Layer). To exclude predicates, select the Multiple Select radio button, then click the Masked Predicate drop-down list and select a predicate to add it to the Masked Predicate field. Click the field again to select additional predicates. Repeat this step to mask additional predicates. You can remove a property from the masked list by clicking the X next to the predicate name.
Query
If you want to hand-pick the data to load, you can use this option to write a SPARQL query that inserts specific values or filters out certain values. To write a query, select the Query radio button, and then type an INSERT query in the text box. For example, you can use the following format to filter out properties from the files:
INSERT {
GRAPH ${targetGraph}{
?s ?p ?o.
}
}
${usingSources}
WHERE {
?s ?p ?o .
FILTER EXISTS { ?s a ?type . }
FILTER(?type = <URI>)
}
Including the ${targetGraph} and ${usingSources} parameters are required. Anzo automatically populates the query with the appropriate graph URIs when the Step is run.
In load filter queries, URIs are not supported in the object position. To specify a URI as an object, include the standard ?s ?p ?o triple pattern in the WHERE clause and then apply FILTER statements with URIs as needed. URIs are supported in the subject or predicate position.
For example, the following query filters the data in a sample dataset that includes information about people and the events they buy tickets for. The WHERE clause filters the data to load only the triples that are related to person1 (personid=1):
INSERT { GRAPH ${targetGraph} {
?s ?p ?o
}
}
${usingSources}
WHERE {
?s ?p ?o ;
<http://cambridgesemantics.com/ont/autogen/c89d/Tickets#tickit_users_personid> ?id .
FILTER (?id=1)
}