Creating a New Unstructured Pipeline
This topic provides instructions for creating a new pipeline to ingest unstructured data.
- In the Anzo console, expand the Onboard menu and click Unstructured Data. Anzo displays the Pipeline screen, which lists any existing unstructured pipelines. For example:
- Click the Create button. Anzo opens the Create Unstructured Pipeline dialog box. For example:
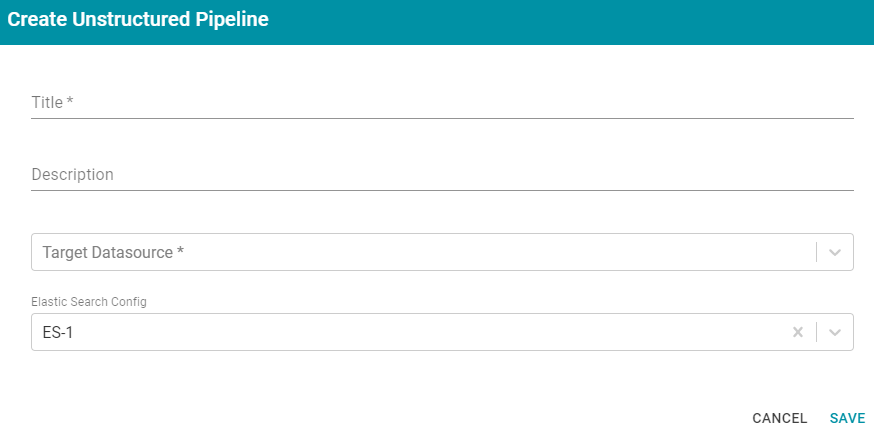
- In the Title field, type a name for the pipeline.
Note: This title serves as a key to identify this pipeline and its corpus in multiple contexts. Specify a title that is unique and stable. The pipeline's corpus data set name is derived from this title.
- Type an optional description for the pipeline in the Description field.
- If necessary, click the Target Datasource field and select the graph data source for this pipeline. For information about creating a graph data source, also known as an Anzo data store, see Creating an Anzo Data Store.
- If necessary, click the Elasticsearch Config field and select the Elasticsearch connection to use for this pipeline. For information about creating an Elasticsearch connection, see Configuring an Elasticsearch Connection.
- Click Save to create the pipeline. Anzo displays the pipeline Overview screen. For example:
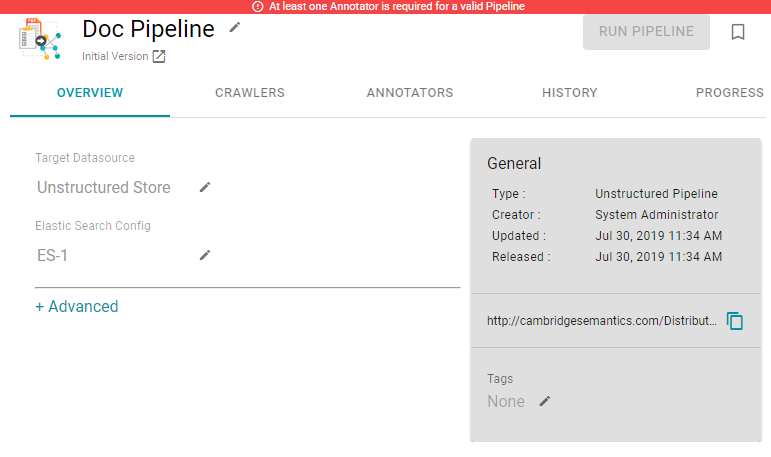
Note: A pipeline configuration saves automatically and constantly undergoes validation to make sure that the pipeline is valid based on the current configuration. Anzo displays validation issues in red on the top of the screen. The warnings will disappear as you add components to the pipeline.
- If necessary, click Advanced to view and configure the advanced pipeline settings. Descriptions of the advanced settings are in progress.
- Click the Crawlers tab and follow the substeps below to add a crawler to the pipeline:
- Click Add Input to select a crawler. Anzo opens the Add Component dialog box.
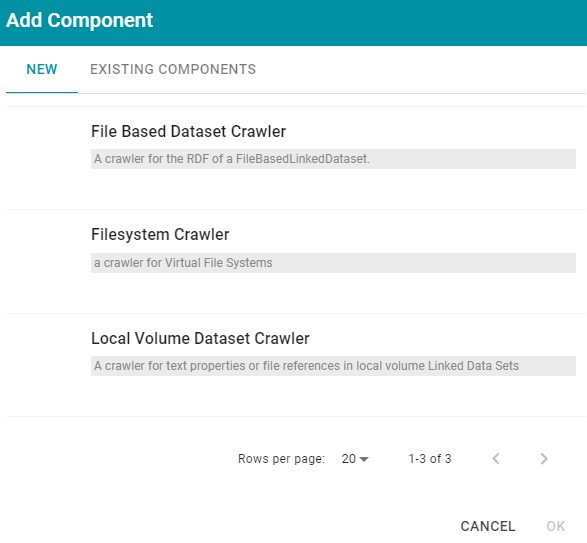
In the Add Component dialog box, the New tab lists the default crawlers and the Existing Components tab lists crawlers that have been previously configured and used in other pipelines.
- To add a new crawler to the pipeline, click the crawler name to select it. To add an existing crawler to the pipeline, click the Existing Components tab, and then select a crawler. The list below describes each of the default crawlers:
- File Based Dataset Crawler: Include this crawler to process data from a file-based linked data set (FLDS) in Anzo.
- Filesystem Crawler: Include this crawler to process documents, such as email messages, PDF, XML, PowerPoint, Excel, OneNote, or Word files, and images, that are available on a file store.
- Local Volume Dataset Crawler: Include this crawler to process RDF data that is stored as a linked data set (LDS) in an Anzo journal.
- After selecting a crawler, click OK. Anzo opens the Create dialog box for the component. Complete the fields to configure the crawler. The list below provides details about the settings for each crawler. Click a crawler name to view the details for that component:
 File Based Dataset Crawler
File Based Dataset CrawlerThis section describes the settings that are available on the Create File Based Dataset Crawler screen:
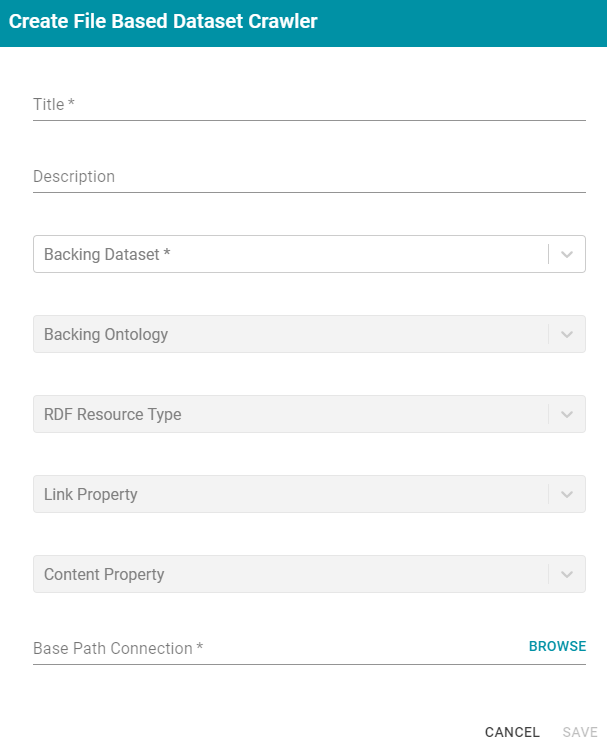
- Title: Required field that specifies the unique name for this crawler.
- Description: Optional field that provides a description of this crawler.
- Backing Dataset: Required field that specifies the Anzo data set to crawl. Click the field and select a data set from the drop-down list.
- Backing Ontology: Required field that specifies the model for the backing data set. Click the field and select a model from the drop-down list.
- RDF Resource Type: Required field that specifies the resource type or class of data to target with this crawler. Click the field and select a resource type from the drop-down list.
- Link Property: Optional field that specifies whether there is a link property to crawl. A link property is a property whose value identifies a linked document. For example, in the triples below, fileLocation is a link property:
<urn://someUnstructuredDocument> <urn://someProperty> "metadata about the file" ; <urn://fileLocation> "/path/to/file.pdf" .
- Content Property: Optional field that specifies whether there is a content property to crawl. A content property is a property whose value is a string literal, and you want Anzo to crawl and annotate the string. For example, in the triples below, longDescription is a content property:
<urn://someUnstructuredDocument> <urn://someProperty> "metadata about the file" ;
<urn://longDescription> "this is some interesting, likely long, unstructured text with a lot of information, and I want to annotate it" . - Base Path Connection: Required field whose value depends on whether a link property was specified or a content property was specified:
- If a Link Property was specified, the Base Path Connection is the base path to use for resolving relative file paths in the link property values. For example, in sample triples above, <urn://fileLocation> has a value of "/path/to/file.pdf." That value could be the relative path to s3://location/bucket/path/to/file.pdf or /opt/anzoshare/data/path/to/file.pdf.
To specify the base path, click the Base Path Connection field. Then type or select the base path to the linked files in the File Location dialog box.
- If a Content Property was specified, the Base Path Connection is a directory on the file store where Anzo can save a copy of the content property string values for the Anzo Unstructured worker instances. Saving the content to a shared file location avoids the overhead of sending the strings to the workers over the network.
To specify the path connection, click the Base Path Connection field. In the File Location dialog box, select the directory where Anzo should save the content property values.
- If a Link Property was specified, the Base Path Connection is the base path to use for resolving relative file paths in the link property values. For example, in sample triples above, <urn://fileLocation> has a value of "/path/to/file.pdf." That value could be the relative path to s3://location/bucket/path/to/file.pdf or /opt/anzoshare/data/path/to/file.pdf.
Filesystem CrawlerThis section describes the settings that are available on the Create Filesystem Crawler screen:
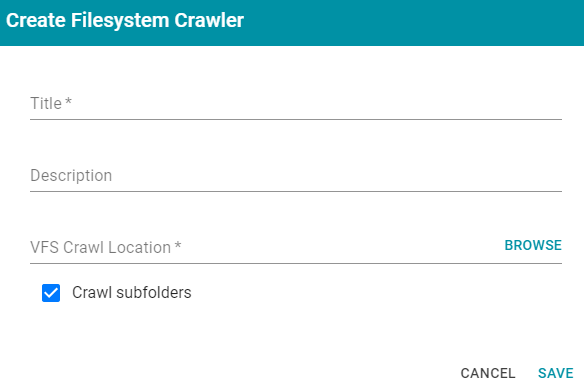
- Title: Required field that specifies the unique name for this crawler.
- Description: Optional field that provides a description of this crawler.
- VFS Crawl Location: Required field that specifies the virtual file system crawl location. Click the field to open the File Location dialog box:
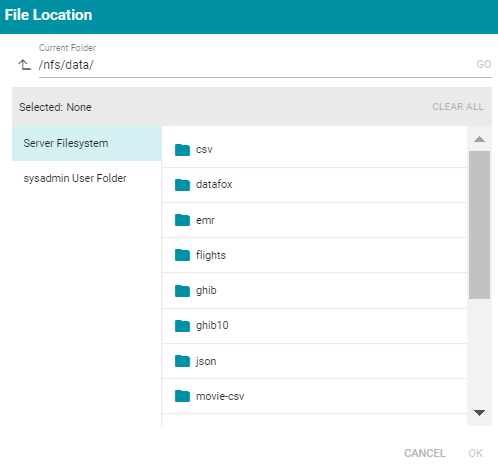
On the left side of the screen, select the storage location for the files to crawl. On the right side of the screen, navigate to the directory that contains the files. Select a directory, and then click OK.
- Crawl subfolders: Optional field that specifies whether to crawl the subdirectories under the VFS Crawl Location. To crawl the subdirectories, select the Crawl subfolders checkbox. To ignore subdirectories, clear the Crawl subfolders checkbox.
Local Volume Dataset CrawlerThis section describes the settings that are available on the Create Local Volume Dataset Crawler screen:
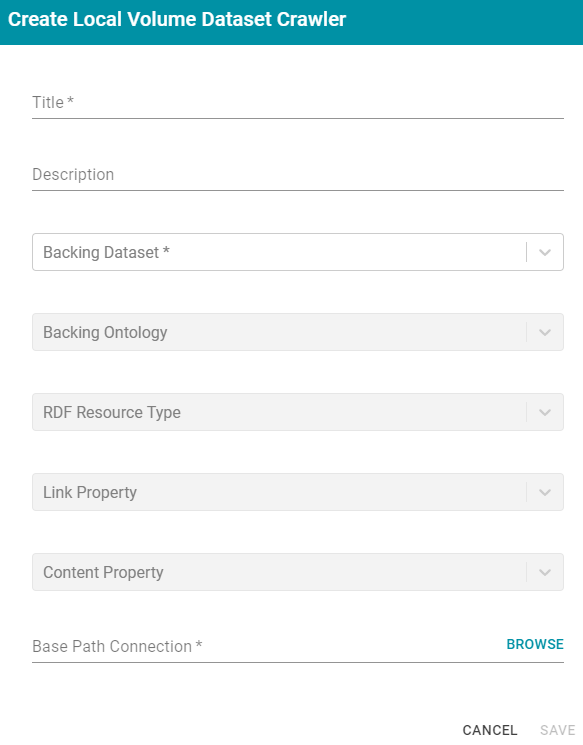
- Title: Required field that specifies the unique name for this crawler.
- Description: Optional field that provides a description of this crawler.
- Backing Dataset: Required field that specifies the Anzo data set to crawl. Click the field and select a data set from the drop-down list.
- Backing Ontology: Required field that specifies the model for the backing data set. Click the field and select a model from the drop-down list.
- RDF Resource Type: Required field that specifies the resource type or class of data to target with this crawler. Click the field and select a resource type from the drop-down list.
- Link Property: Optional field that specifies whether there is a link property to crawl. A link property is a property whose value identifies a linked document. For example, in the triples below, fileLocation is a link property:
<urn://someUnstructuredDocument> <urn://someProperty> "metadata about the file" ; <urn://fileLocation> "/path/to/file.pdf" .
- Content Property: Optional field that specifies whether there is a content property to crawl. A content property is a property whose value is a string literal, and you want Anzo to crawl and annotate the string. For example, in the triples below, longDescription is a content property:
<urn://someUnstructuredDocument> <urn://someProperty> "metadata about the file" ;
<urn://longDescription> "this is some interesting, likely long, unstructured text with a lot of information, and I want to annotate it" . - Base Path Connection: Required field whose value depends on whether a link property was specified or a content property was specified:
- If a Link Property was specified, the Base Path Connection is the base path to use for resolving relative file paths in the link property values. For example, in sample triples above, <urn://fileLocation> has a value of "/path/to/file.pdf." That value could be the relative path to s3://location/bucket/path/to/file.pdf or /opt/anzoshare/data/path/to/file.pdf.
To specify the base path, click the Base Path Connection field. Then type or select the base path to the linked files in the File Location dialog box.
- If a Content Property was specified, the Base Path Connection is a directory on the file store where Anzo can save a copy of the content property string values for the Anzo Unstructured worker instances. Saving the content to a shared file location avoids the overhead of sending the strings to the workers over the network.
To specify the path connection, click the Base Path Connection field. In the File Location dialog box, select the directory where Anzo should save the content property values.
- If a Link Property was specified, the Base Path Connection is the base path to use for resolving relative file paths in the link property values. For example, in sample triples above, <urn://fileLocation> has a value of "/path/to/file.pdf." That value could be the relative path to s3://location/bucket/path/to/file.pdf or /opt/anzoshare/data/path/to/file.pdf.
- When you have finished configuring the crawler, click Save. Anzo adds the crawler to the pipeline and returns to the Crawlers screen. For example:
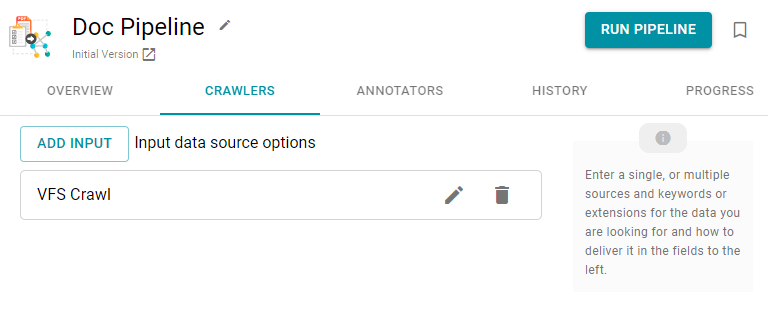
- If you want to change the crawler configuration, click the Edit icon (
 ) for the crawler and modify the settings as needed. If you want to add another crawler to the pipeline, repeat substeps a – d.
) for the crawler and modify the settings as needed. If you want to add another crawler to the pipeline, repeat substeps a – d.
- Click Add Input to select a crawler. Anzo opens the Add Component dialog box.
- Click the Annotators tab and follow the substeps below to add an annotator to the pipeline:
- Click Add Output to select an annotator. Anzo opens the Add Component dialog box.
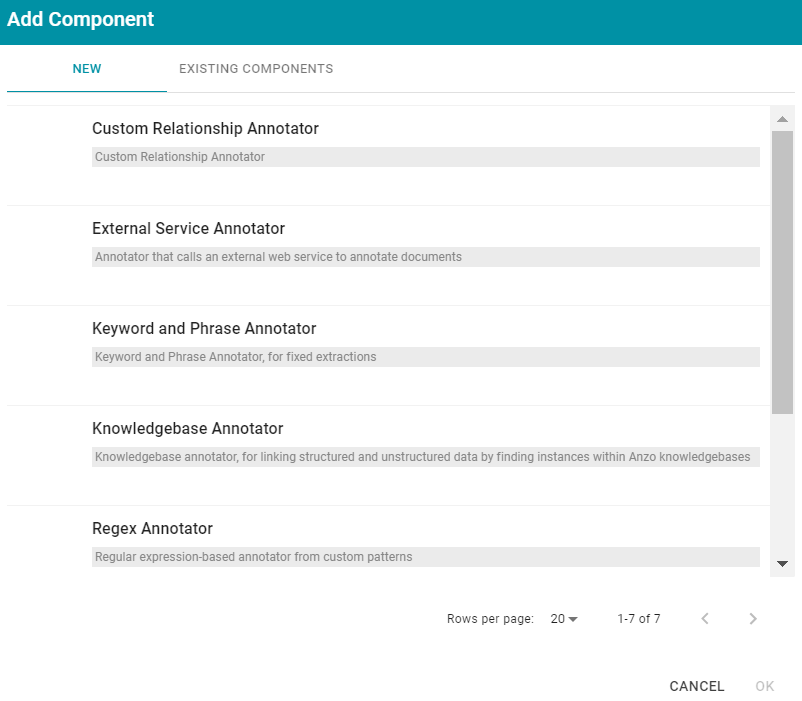
In the Add Component dialog box, the New tab lists the default annotators and the Existing Components tab lists annotators that have been previously configured and used in other pipelines.
- To add a new annotator to the pipeline, click the annotator name to select it. To add an existing annotator to the pipeline, click the Existing Components tab, and then select an annotator. The list below describes each of the default annotators:
- Custom Relationship Annotator: Include this annotator to map relationships between annotations based on the number of characters between the annotations.
- External Service Annotator: Include this annotator to hit an HTTP endpoint that provides annotations.
- Keyword and Phrase Annotator: Include this annotator to create annotations based on the phrases that you specify.
- Knowledgebase Annotator: Include this annotator to link structured and unstructured data by finding instances in Anzo knowledgebases. Based on the names and aliases of entities present or patterns that are indicative of the entities, this annotator marks up the documents with the structured entities linked.
- Regex Annotator: Include this annotator to use regular expression rules to identify entities such as email addresses, URLs, phone numbers, or any other entity that can be matched using a regular expression.
- Semantria Annotator: Include this annotator to use the Semantria web service to find entities, sentiment, and topics in documents. It requires an Semantria API access key from Lexalytics.
- Significant Phrases Annotator: Include this annotator to annotate statistically significant words and phrases.
- After selecting an annotator, click OK. Anzo opens the Create dialog box for the component. Complete the fields to configure the annotator. The list below provides details about the settings for the annotators that are typically used in pipelines. Click an annotator name to view the details for that component:External Service Annotator
This section describes the settings that are available on the Create External Service Annotator screen:
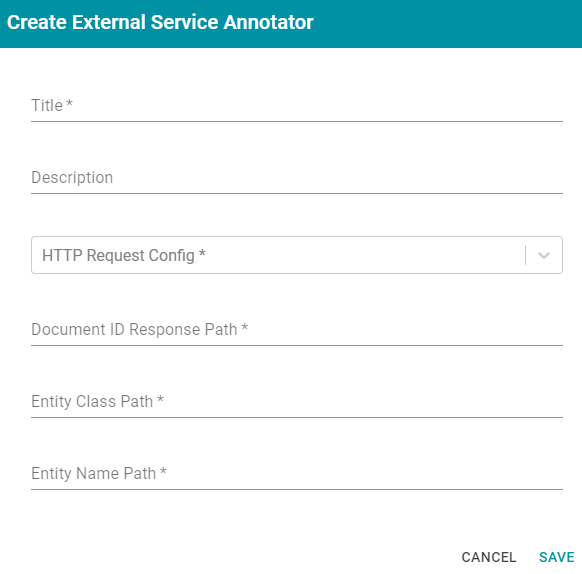
- Title: Required field that specifies the unique name for this annotator.
- Description: Optional field that provides a description of this annotator.
- HTTP Request Config: Required field that specifies the HTTP source object that contains the URL and method to use when sending data for annotations.
- Document ID Response Path: Required field that specifies where to find the document ID in the response.
- Entity Class Path: Required field that specifies the class URI for an annotation.
- Entity Name Path: Required field that specifies the annotation object name path.
Knowledgebase AnnotatorThis section describes the settings that are available on the Create Knowledgebase Annotator screen:
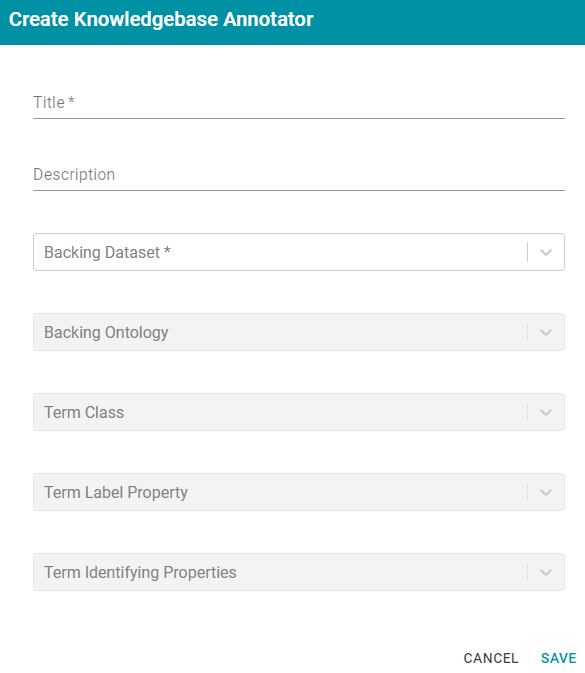
- Title: Required field that specifies the unique name for this annotator.
- Description: Optional field that provides a description of this annotator.
- Backing Dataset: Required field that specifies the Anzo knowledgebase to crawl. Click the field and select a knowledgebase from the drop-down list.
- Backing Ontology: Required field that specifies the model for the backing data set. Click the field and select a model from the drop-down list.
- Term Class: Required field that specifies the class of data for the annotation.
- Term Label Property: Required field that lists the property for which to find entities.
- Term Identifying Properties: Required field that specifies the properties that contain names, aliases, or other identifiers by which you want to find entities.
Regex AnnotatorThis section describes the settings that are available on the Create Regex Annotator screen:
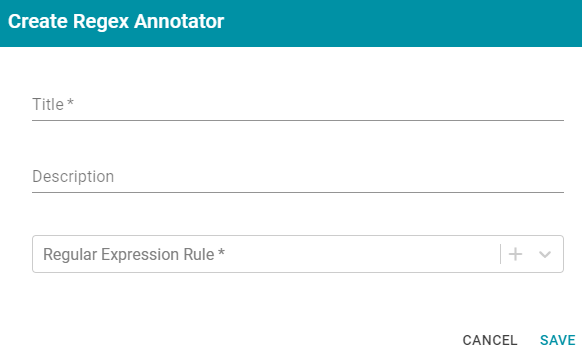
- Title: Required field that specifies the unique name for this annotator.
- Description: Optional field that provides a description of this annotator.
- Regular Expression Rule: Required field the lists the regular expression rules for this annotator. To add a rule, click the plus icon (
 ) in the field. Anzo opens the Create Regular Expression Rule dialog box where you can define the rule:
) in the field. Anzo opens the Create Regular Expression Rule dialog box where you can define the rule:
- Title: Required field that specifies the name of the rule.
- Description: Optional field that describes the rule.
- Regular Expression: Required field that specifies the regular expression to use for finding matching entities.
- Class Structure: Required field that specifies the class structure for the entities in the format
group_number:class_name. For example,0:person,1:Company.
- When you have finished configuring the annotator, click Save. Anzo adds the annotator to the pipeline and returns to the Annotators screen. For example:
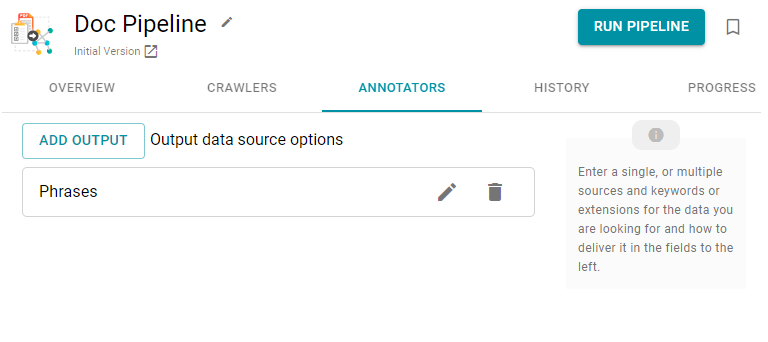
- If you want to change the annotator configuration, click the Edit icon () for the annotator and modify the settings as needed. If you want to add another annotator to the pipeline, repeat substeps a – d.
- Click Add Output to select an annotator. Anzo opens the Add Component dialog box.
- When you have finished adding crawlers and annotators to the pipeline, click the Run Pipeline button to run the pipeline.
The process can take several minutes to complete. You can click the Progress tab to view details such as the pipeline status, runtime, number of documents processed, and errors. For example:
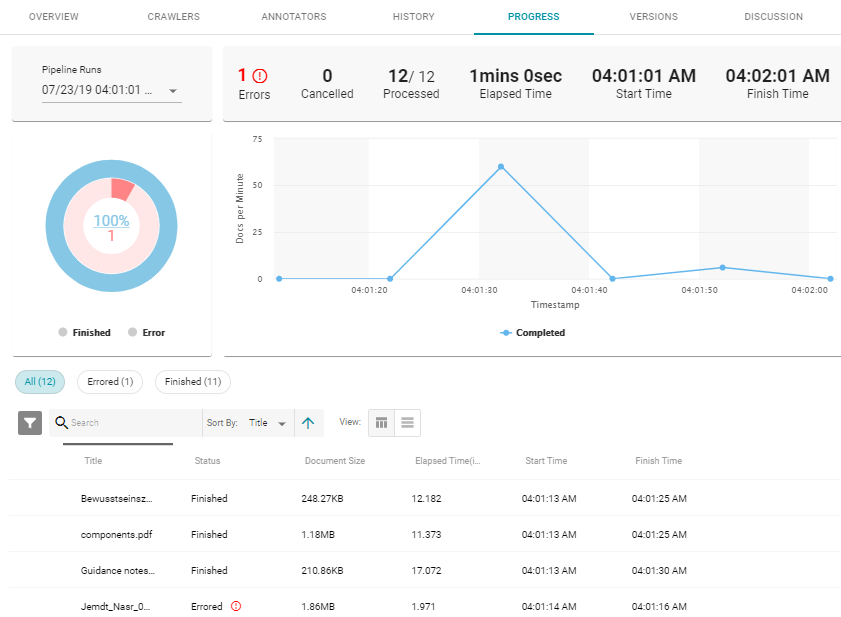
When the pipeline completes, Anzo registers the new unstructured data set and adds it to the Dataset catalog. You can add the new data set to a graphmart and load it to AnzoGraph so that you can explore and analyze the data in Hi-Res Analytics dashboards. See Creating Graphmarts and Loading Data to AnzoGraph for instructions.