Anzo 5.0 Releases
To view the release notes for an Anzo 5.0 version, select the version from the list below. The release notes for each version describe the product changes from the previous version.
- Anzo Version 5.0.8
- Anzo Version 5.0.7
- Anzo Version 5.0.6
- Anzo Version 5.0.5
- Anzo Version 5.0.4
- Anzo Version 5.0.3
- Anzo Version 5.0.2
- Anzo Version 5.0.1
- Anzo Version 5.0.0
Anzo Version 5.0.8
This section describes the improvements and issues that were fixed in Anzo Version 5.0.8.
- Added Waterfall Chart Type
- Added Option to Cancel a Running Query in the Query Builder
- Added Option to Cancel All Inflight Queries
- Added Support for Escaped Parquet File Names
- Added Option to Set Maximum Duration for AnzoGraph Queries
- Added SPARQL Endpoint Option to Skip Query Cache
- Added Logging to Capture Additional User Management Related Events
- Added Option to Exclude Filters on Hyperlinked Lenses
- Improved Behavior for Canceled SPARQL Endpoint and Query Builder Download Requests
- Improved Oracle Date Type Handling in Sparkler Compiler
- Improved Data on Demand Handling of Models with Recursive Hierarchies
- Improved Efficiency Between Orchestration Service and Ingest Manager
- Improved Page Load Performance for Customized Hi-Res Analytics Application
- Removed Oracle JDBC Bundle Dependency
- Limited Maximum Results in the Query Builder
- Corrected Misalignment of Drill Down Icons in Table Lenses
- Removed Aborted Queries from Inflight Queries List
- SPARQL Endpoint Rejected Request with Content-Type
- Non Sysadmin Users Could Not Delete Layers and Steps
- Error Loading Data from HDFS File Store
- Deleted Model Remained Visible in the User Interface
- LDAP Change Not Reflected in User Interface after Sync
- Error when Anzo Admin CLI Used with HTTP
- Activation of Large Graphmart Failed with Deadline Exceeded Error
- Auto-Refresh not Triggered for Graphmart with Journal-Based Data Sets
- Startup Failed when Orchestration Service was Enabled
Added Waterfall Chart Type
Version 5.0.8 introduces a new Waterfall Chart Type lens for Hi-Res Analytics dashboards. The Waterfall chart compares the contribution of each value to the total values across categories.
The aggregated Waterfall Chart Summary cannot be enabled unless the X Axis value is a string. To display the Waterfall Summary, choose a string value for the X Axis or use a function such as STR to coerce a non-string value to a string.
Tip: When converting date values to strings, use the format yyyy-mm-dd to apply the expected date sort order.
Added Option to Cancel a Running Query in the Query Builder
Version 5.0.8 adds a Cancel Running Query button to the Query Builder so that a running query can be canceled if needed.
Added Option to Cancel All Inflight Queries
Version 5.0.8 adds a Cancel All button to the Inflight Queries tab in the System Query Audit log. Clicking Cancel All cancels all inflight queries.
Added Support for Escaped Parquet File Names
Version 5.0.8 adds support for onboarding Parquet files with escaped file names and paths.
Added Option to Set Maximum Duration for AnzoGraph Queries
Version 5.0.8 introduces a Max Allowed Duration for Queries option for setting a limit on the amount of time Anzo waits for AnzoGraph to complete a user query, such as dashboard, data layer, or Query Builder queries. By default, Anzo waits indefinitely. To set a maximum duration, specify the amount of time in any combination of days, hours, and minutes. For example, specifying 1d sets the maximum duration to one day. Specifying 10h, sets the maximum duration to 10 hours, and specifying 1d12h30m sets the duration to 1 day, 12 hours, and 30 minutes. For more information, see Connecting to AnzoGraph.
Added SPARQL Endpoint Option to Skip Query Cache
Version 5.0.8 adds the SPARQL endpoint skipCache parameter. Specifying skipCache=true in a request avoids the reuse of the cache that may exist from a previous run of the query.
Added Logging to Capture Additional User Management Related Events
Version 5.0.8 increases the amount of user management related events that are reported in the Anzo audit logs.
The log level of the UserAudit package must be set to Info in order to report user audit events. For information about changing log levels, see Adding Logs and Adjusting Logging Levels.
When the UserAudit package is set to Info, the anzo_full.log captures the following events:
- The inactivity timeout is changed.
- There are failed login attempts.
- A user successfully logs in or out.
- A user password is changed.
- A user account is created or deleted.
- A user or group is synchronized with the directory server.
- A user is added to or removed from a role or group.
- A permission is added to or removed from a role.
- A role is created or deleted.
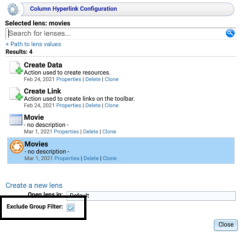
Added Option to Exclude Filters on Hyperlinked Lenses
Version 5.0.8 adds an option to exclude the filters on the origin dashboard when configuring a hyperlink to another lens or dashboard. The new option, Exclude Group Filter (shown below), is available in the Table lens Designer when configuring a column hyperlink.
Improved Behavior for Canceled SPARQL Endpoint and Query Builder Download Requests
Version 5.0.8 ensures that Anzo responds when a user cancels a SPARQL endpoint query. This version also improves behavior when results are being downloaded from the Query Builder and the request is canceled. Both types of cancellations log messages to anzo_full.log.
Improved Oracle Date Type Handling in Sparkler Compiler
Version 5.0.8 restores a workaround that is needed to handle Oracle DATE types. Without the fix, certain date values could be missing from the output once the Sparkler job was complete.
Improved Data on Demand Handling of Models with Recursive Hierarchies
Version 5.0.8 improves the handling of models with recursive hierarchies in Data on Demand endpoints. Previously a request could return a stack overflow error if a $metadata or class URL OData request was sent and the model included a circular subclass hierarchy.
Improved Efficiency Between Orchestration Service and Ingest Manager
To increase ingestion performance, Version 5.0.8 eliminates the redundancy of operations when the Orchestration Service and Ingest Manager are used together.
Improved Page Load Performance for Customized Hi-Res Analytics Application
Version 5.0.8 significantly improves the page load performance when a custom personality is used for the Hi-Res Analytics application.
Removed Oracle JDBC Bundle Dependency
Version 5.0.8 removes the dependency on the Oracle 11.2 JDBC bundle so that the .jar file can be removed and/or replaced without causing an error on Anzo startup.
Limited Maximum Results in the Query Builder
Version 5.0.8 limits the maximum number of results that can be returned in the Query Builder to 10,000.
Corrected Misalignment of Drill Down Icons in Table Lenses
When scrolling in a dashboard with a Table lens that had drill down functionality configured, the drill down icons could become misaligned. Version 5.0.8 corrects the alignment.
Removed Aborted Queries from Inflight Queries List
Version 5.0.8 resolves an issue that could cause aborted AnzoGraph queries to remain in the Inflight Queries log in System Query Audit.
SPARQL Endpoint Rejected Request with Content-Type
Version 5.0.8 resolves an issue that caused the SPARQL endpoint to reject queries against AnzoGraph extensions if the request specified the Content-Type.
Non Sysadmin Users Could Not Delete Layers and Steps
Version 5.0.8 corrects an issue that caused an error when a non-sysadmin user tried to delete or rearrange data layers or steps in a graphmart.
Error Loading Data from HDFS File Store
AnzoGraph returned a "Could not resolve data location or data files" error when a user tried to activate a graphmart whose RDF files were on a HDFS file store. The problem was that Anzo connected to the HDFS RPC port but AnzoGraph tried to connect to the HTTP REST port. Version 5.0.8 resolves the issue by adding HTTP protocol settings to the HDFS file connection. Now users can provide the HTTP specifications that AnzoGraph needs to access HDFS. The new settings are Nameservice Rest IP or Name, Nameservice Rest Port, and Nameservice Rest Protocol. For details about the settings, see HDFS File Connection.
Deleted Model Remained Visible in the User Interface
Version 5.0.8 corrects an issue that caused a model that was deleted via the Anzo admin CLI to remain visible in the Anzo application.
LDAP Change Not Reflected in User Interface after Sync
Version 5.0.8 resolves an issue where, in certain circumstances, the user interface did not reflect directory group changes after the server was synchronized with Anzo.
Error when Anzo Admin CLI Used with HTTP
Version 5.0.8 resolves a problem that caused the Anzo admin CLI to return a classpath error when the CLI was configured to use HTTP instead of JMS.
Activation of Large Graphmart Failed with Deadline Exceeded Error
Version 5.0.8 resolves an issue that could cause the activation of a very large graphmart to fail with a "Deadline Exceeded" error.
Auto-Refresh not Triggered for Graphmart with Journal-Based Data Sets
Version 5.0.8 corrects an issue that caused automatic graphmart refresh (Manual Refresh Graphmart was false) to fail when a graphmart had a single Load Data Step that included several journal-based data sets.
Startup Failed when Orchestration Service was Enabled
Version 5.0.8 resolves an issue that prevented Anzo from starting if the Orchestration Service (the com.cambridgesemantics.anzo.asdl.services bundle) was enabled.
Anzo Version 5.0.7
This section describes the improvements and issues that were fixed in Anzo Version 5.0.7.
- Pagination Options in the Query Builder
- Include Index in Export of Unstructured Data Set
- Report Load Step Errors in the Anzo Application
- Remove 6-Minute Timeout for AnzoGraph Queries
- Display Regex Annotation Class Names in Annotated Document Lens
Pagination Options in the Query Builder
Like Table lens pagination options in the Hi-Res Analytics application, Version 5.0.7 adds the ability to control the number of results that are displayed per page in the Query Builder. Regardless of the LIMIT that is specified for the query, users now have the option to display 25, 50, 100, 150, or 200 results per page. For example:
Include Index in Export of Unstructured Data Set
When an Export Step was used to export an unstructured data set from memory to an FLDS, there were some cases where the associated Elasticsearch index was not added to the FLDS. Version 5.0.7 corrects the issue so that related indexes are included in the FLDS when unstructured data is exported.
Report Load Step Errors in the Anzo Application
The Anzo application reported that all data layers in a graphmart were successfully activated even though a Load Step failed due to malformed URIs. Version 5.0.7 improves error reporting so that the Anzo application can parse and display errors from AnzoGraph during graphmart activation.
Remove 6-Minute Timeout for AnzoGraph Queries
In Version 5.0.7, the default timeout value for AnzoGraph queries was changed from 6 minutes to unlimited.
Display Regex Annotation Class Names in Annotated Document Lens
When the Regex Annotator captured annotations, they were displayed under a generic "Regex Capture" class in Annotated Document lenses. In Version 5.0.7, new subclasses are created as defined in the Regex Annotator, and annotations are displayed under the appropriate class names in the Annotated Document lens.
Anzo Version 5.0.6
This section describes the improvements and issues that were fixed in Anzo Version 5.0.6.
- Ability to Omit Heap or Stack from System Monitor Dump
- Option to Limit Number of Stored Anzo Unstructured Status Journals
- Added Support for RDF* Notation in Queries
- Query Builder Improvements
- Crash after Export of Current Version of a Mapping
- Model Improperly Updated after Re-Ingesting Modified Schema
- Search in Pipeline History Failed to Find Results
- Graphmart Refresh Failed after Step Removed
- Graphmart Refresh Failed to Cancel after Error
- Local Sparkler Engine Generated Unnecessary SSO Provider Objects
- System Stability Improvements
Ability to Omit Heap or Stack from System Monitor Dump
To preserve disk space, Version 5.0.6 introduces the option to configure the Anzo System Monitor service to exclude heap dumps or stack dumps. In cases where you want the service to dump stacks or heaps but not both, you can clear either the stackLocation or heapLocation value to turn off that type of dump.
Follow the instructions below if you want to configure the System Monitor service to omit heap or stack dumps.
- In the Anzo application, expand the Administration menu and click Advanced Configuration. Click I understand and accept the risk.
- Search for the Anzo System Monitor bundle and view its details.
- Click the Services tab and expand System Monitor Activator.
- Clear the value for the following properties depending on which type of dump you want to disable:
- com.cambridgesemantics.anzo.system.monitor.heapLocation: Clear the value for this property if you do not want the service to output heap dumps.
- com.cambridgesemantics.anzo.system.monitor.stackLocation: Clear the value for this property if you do not want the service to output stack dumps.
- After clearing a value, click the checkmark icon (
 ) for that property to save the change. Then restart Anzo to apply the System Monitor service change.
) for that property to save the change. Then restart Anzo to apply the System Monitor service change.
Option to Limit Number of Stored Anzo Unstructured Status Journals
To limit the disk space used by Anzo Unstructured pipelines, Version 5.0.6 introduces the option to configure the Anzo Unstructured Distributed service to limit the number of status journals that are preserved on disk. When the specified limit is reached and a pipeline generates a new journal, the oldest journal is deleted. Journals are removed based on their timestamps alone. The pipeline they are associated with is not a factor in determining the journals to delete.
Follow the instructions below if you want to configure the Unstructured Distributed service to limit the number of status journals on disk.
- In the Anzo application, expand the Administration menu and click Advanced Configuration. Click I understand and accept the risk.
- Search for the Anzo Unstructured Distributed bundle and view its details.
- Click the Services tab and expand Anzo Unstructured Distributed.
- Edit the com.cambridgesemantics.anzo.unstructured.distributed.defaultNumStatusJournalGlobalLimit property to specify the maximum number of status journals to keep on disk. The default value is -1, which is unlimited.
- Click the checkmark icon () to save the change. Then restart Anzo to apply the service configuration change.
Added Support for RDF* Notation in Queries
Version 5.0.6 adds support for using RDF* (labeled property graph) notation in the Query Builder and data layer queries. This change enables users to create and read edge properties using the following syntax in queries:
<< ?subject ?predicate ?object >> ?property ?property_value
For more information about RDF* syntax, see Labeled Property Graphs in the AnzoGraph Deployment and User Guide.
Query Builder Improvements
Version 5.0.6 includes several fixes and enhancements to the Query Builder:
- Improve error message reporting to ensure that detailed information is displayed.
- Resolve an issue that prevented users from being able to save queries in some circumstances. In addition, ensure that multiple copies of a query are not saved if a user saves a query, continues to edit it, and then saves the query again.
- Resolve an issue that prevented a user from being able to preview a Templated Step query in the Query Builder.
- Correct an issue that caused edits to be lost if a user was in the process of editing a saved or previously run query and moused over a menu item in the navigation pane without leaving the Query Builder page.
- Ensure that CONSTRUCT queries return the correct number of results when a LIMIT is specified in the query.
- Resolve an issue that prevented the Format Query option from working when the data source was a graphmart.
- Ensure that saved queries can be deleted.
- Fix an issue that caused the Query Builder to return an "Unknown function" error when PARSEDATE was used to convert strings to date values in a graphmart.
Crash after Export of Current Version of a Mapping
Version 5.0.6 corrects a Java out of memory error that caused Anzo to crash when a user exported the current version of a particular mapping.
Model Improperly Updated after Re-Ingesting Modified Schema
Version 5.0.6 corrects an issue that caused the model to be corrupted after a data source was re-ingested to pick up schema changes.
Search in Pipeline History Failed to Find Results
Version 5.0.6 fixes an issue where the Search function on the Pipeline History tab failed to find matching jobs, even when an exact match was specified.
Graphmart Refresh Failed after Step Removed
Version 5.0.6 corrects an issue that caused a null pointer exception to occur after a step was removed from a graphmart and that graphmart was refreshed.
Graphmart Refresh Failed to Cancel after Error
In a previous version, a user refreshed a graphmart and the refresh failed due to errors. However, the Anzo application continued to show that the refresh was in progress until the user canceled the activity. Version 5.0.6 resolves the issue by ensuring that errors are promptly reported to the client and refresh activity is stopped if it fails. In addition, if no error is produced but AnzoGraph becomes unresponsive, Anzo also ensures that all graphmart load and refresh processes are stopped.
Local Sparkler Engine Generated Unnecessary SSO Provider Objects
When using the local Sparkler Engine to compile ETL jobs, the compiler was generating SSO provider objects each time a job was run, instead of creating one token and reusing it for subsequent jobs. Version 5.0.6 resolves the issue to ensure that generated SSO provider objects are reused instead of recreated.
Anzo Version 5.0.5
This section describes the improvements and issues that were fixed in Anzo Version 5.0.5.
- Option to Set an AnzoGraph Response Timeout
- Data Layer Selections Duplicated in Query Builder
- Some File Handles Remained Open after Jobs Published
- Syntax Error for Dry Run Query
Option to Set an AnzoGraph Response Timeout
In some circumstances, the Anzo application hung because Anzo requested system table information, such as CPU and memory usage statistics, from AnzoGraph and AnzoGraph did not respond. Version 5.0.5 introduces a response timeout setting in the AnzoGraph connection configuration. If Anzo is waiting on a system information type response from AnzoGraph and AnzoGraph does not respond within the specified time, Anzo cancels the request rather than waiting indefinitely.
The new option, Request Deadline (Minutes), is available under Advanced settings on the AnzoGraph Configuration tab (shown in the image below). The default value is 2 minutes.

Data Layer Selections Duplicated in Query Builder
Version 5.0.5 corrects an issue that caused the Query Builder to duplicate the data layers that were selected for a query.
Some File Handles Remained Open after Jobs Published
In some cases, open file handles were not closed for all jobs after a pipeline was published. This caused a "Too many open files" error after several pipelines were run in an environment. Version 5.0.5 resolves the issue to ensure that all open file handles are closed when jobs are completed.
Syntax Error for Dry Run Query
In the Query Builder, users can perform a dry run of an INSERT or DELETE query by clicking the Dry Run Query button. When a dry run is issued, Anzo rewrites the query as a CONSTRUCT query and sends that version to AnzoGraph. Version 5.0.5 resolves an issue where the rewrite of a dry-run query could have a syntax error and fail to run.
Anzo Version 5.0.4
This section describes the improvements and issues that were fixed in Anzo Version 5.0.4.
- Hi-Res Analytics Application Redesign
- Improved Schema Tables View
- Added Activate/Deactivate Graphmart Options to Orchestration Service
- Reduce Latency for SPARQL Endpoint Requests with SSO
- Unable to Version a Pipeline if Multiple Models Shared a Class URI
- Sparkler Engine Failed to Remove Copies of Shared Library
- Non Sysadmin Users Could Not Modify Models
- OData Request for CSV Format Failed
- Expected Properties Missing from Class View
- Missing Graphs were Not Ignored
- Application Hung During Graphmart Operations
- Graphmart Refresh Button Visible but Not Functional
- Callback Failed on Hadoop Spark Cluster
- Could Not Create Network Navigator Lens
Hi-Res Analytics Application Redesign
Version 5.0.4 redesigns the skin for the Hi-Res Analytics application to give the application a more modern and minimalistic look and feel.
The updated skin is not loaded when you open the Hi-Res Analytics application with the default https://<IP>/anzoweb/index.html URL. To open the application with the updated skin, use the following URL: https://<IP>/anzoweb/index-flat.html. For instructions on configuring the Anzo application to open the new URL (or another custom URL) by default, see Routing Hi-Res Analytics to a Custom URL.
Improved Schema Tables View
When a data source had a large number of schemas that could not be viewed at the same time on the Tables tab, the Load More button at the bottom of the screen did not load the additional schemas. Version 5.0.4 resolves the issue in the following ways:
- The default number of rows loaded on the Tables tab was increased to 5,000.
- Clicking the Load More button does successfully load additional schemas.
Added Activate/Deactivate Graphmart Options to Orchestration Service
Version 5.0.4 enhances the Graphmart Load Service that is called from the Orchestration Service to add the option to activate or deactivate graphmarts.
Reduce Latency for SPARQL Endpoint Requests with SSO
When an environment had an SSO provider configured, there was an increased overhead of a few seconds when running queries against the Anzo SPARQL endpoint. The overhead was due to the accumulation and verification of SSO objects in the system volume. Version 5.0.4 reduces the number of SSO objects that are retained and speeds up the verification of the objects to reduce the overhead for SPARQL endpoint queries.
Unable to Version a Pipeline if Multiple Models Shared a Class URI
A user was unable to create a backup version of a pipeline when more than one model in the pipeline had the same class URI. Version 5.0.4 resolves the issue to make sure that Anzo can distinguish between class URIs when models in the same pipeline share that URI.
Sparkler Engine Failed to Remove Copies of Shared Library
When the Sparkler compiler was used to compile ETL jobs, the compiler could fail to remove copies of the shared library that were no longer needed once the jobs were compiled. The leftover .jar files took up unnecessary space on the file system. Version 5.0.4 resolves the issue to ensure that shared library .jar files are removed from the file system after jobs have finished compiling.
Non Sysadmin Users Could Not Modify Models
In a previous version, only the sysadmin user could create, edit, or delete models in the Model editor. Other roles could not use the Model editor. Version 5.0.4 resolves the issue so that any user with the appropriate permissions can create, edit, and delete models in the Model editor.
OData Request for CSV Format Failed
When an OData request asked for results in CSV format ($format=text/csv), the request failed with a null pointer exception. Version 5.0.4 resolves the issue so that Data on Demand requests can return results in CSV format.
Expected Properties Missing from Class View
When one model defined class "A" and a second model defined property "P" with a domain of class "A," property "P" could be excluded from the list of properties when class "A" was viewed in a dashboard or a Data on Demand endpoint. Version 5.0.4 corrects the issue.
Missing Graphs were Not Ignored
By default, Anzo is configured to ignore missing graphs rather than throw an error when a client (such as the admin CLI or Hi-Res Analytics application) sends a query. If a user removed a data layer from an activated graphmart, however, and then a client request included that layer, the missing graph was not ignored and the request failed with an error. Version 5.0.4 resolves this issue so that missing graphs are correctly ignored by default if a layer is removed from an active graphmart.
Application Hung During Graphmart Operations
Version 5.0.4 resolves an issue that could cause the Anzo application to hang or load slowly after reloading and refreshing graphmarts.
Graphmart Refresh Button Visible but Not Functional
Version 5.0.4 resolves an issue where the Refresh button remained visible on the Graphmart screen even though the data layers had not changed and a refresh was not needed.
Callback Failed on Hadoop Spark Cluster
Version 5.0.4 resolves an issue that caused the callback step to fail when an ETL pipeline was published on a Hadoop Spark cluster.
Could Not Create Network Navigator Lens
Version 5.0.4 resolves an issue that prevented the lens Designer from loading when a user created a Network Navigator lens. Since the Designer failed to load, the lens could not be configured and added to a dashboard.
Anzo Version 5.0.3
This section describes the improvements and issues that were fixed in Anzo Version 5.0.3.
- Option to Force Logout of SSO Provider by Default
- Performance Improvements for Large Delete Operations
- Usability Improvements for Versioning and Restore Operations
- Usability Improvements for Data Layers
- Improved Handling of LDAP Connectivity Issues
- Improved Handling of Kerberos Configuration for HDFS File Stores
- Data on Demand Error Handling and Performance Improvements
- Improved OData Tableau Support
- Ability to Log Out of Multiple Sessions
- Improved User Interface Responsiveness
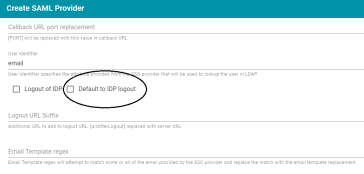
Option to Force Logout of SSO Provider by Default
Version 5.0.2 added a Logout of IDP option to the SSO provider configuration in Anzo. When Logout of IDP was enabled, users were presented with an option to perform a central log out when they logged out of Anzo. Version 5.0.3 introduces the new Default to IDP Logout option (shown in the image below). When Default to IDP Logout is enabled, users are not given a choice about logging out of the IDP. The central logout is performed by default.
Performance Improvements for Large Delete Operations
In previous versions, deleting very large artifacts from Anzo could take a significant amount of time. Version 5.0.3 incorporates performance improvements that reduce the time it takes to perform large delete operations.
Usability Improvements for Versioning and Restore Operations
Version 5.0.3 makes a number of usability enhancements for versioning and restore operations. The changes improve the workflow and messaging for users who do not have permissions to view or modify all of entities that are related to a version.
Usability Improvements for Data Layers
Version 5.0.3 enhances usability and performance when adding, changing, or removing data layers in graphmarts that have a large number of layers or steps.
Improved Handling of LDAP Connectivity Issues
Version 5.0.3 improves the handling and messaging around external LDAP server connectivity issues.
Improved Handling of Kerberos Configuration for HDFS File Stores
Version 5.0.3 improves handling of various Kerberos configurations and environments.
Data on Demand Error Handling and Performance Improvements
Version 5.0.3 adds the following improvements for Data on Demand endpoints:
- Includes UserPrincipal information when logging errors.
- Optimizes the serialization of OData results to improve performance when concurrent OData queries are run against large data sets.
- Returns an empty result set instead of an exception if the requesting user does not have permission to view the ontology or the ontology is missing.
Improved OData Tableau Support
Version 5.0.3 improves support for using Tableau with an OData connection by accepting requests with an invalid Accept header.
Ability to Log Out of Multiple Sessions
Version 5.0.3 corrects an issue where logging out of Anzo and the SSO provider was not always successful if multiple tabs (sessions) were active.
Improved User Interface Responsiveness
Version 5.0.3 addresses issues that caused the user interface to become unresponsive or fail to update statuses, such as the status of AnzoGraph instances or graphmarts that were loaded to AnzoGraph.
Anzo Version 5.0.2
This section describes the improvements and issues that were fixed in Anzo Version 5.0.2.
- Option to Log Out of SSO Provider with Anzo Logout
- Disable AnzoGraph Detailed Query Timing by Default
- Failed to Display Graphmart Overview Screen
- Incomplete Results from OData JDBC Driver with Server Side Paging
- Improved Error Messaging for Login Failures
Option to Log Out of SSO Provider with Anzo Logout
In previous versions, logging out of the Anzo application ended the Anzo session but could not be configured to end the SSO Provider session. Leaving the SSO session open could pose a problem with auto-redirect configurations to SSO. In Version 5.0.2, the Single Sign On configuration screens for Facebook, Indirect Kerberos, Google OIDC, Open ID Connect, and SAML providers include new Logout of IDP and Logout URL Suffix settings. For example:
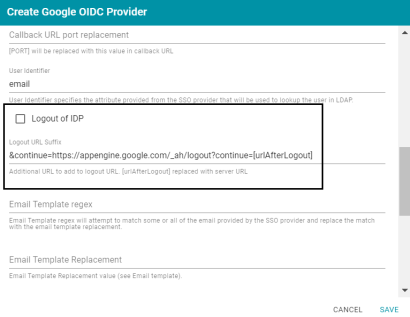
When Logout IDP is enabled, the Logout URL Suffix is used to access the logout URL for the SSO provider. When a user logs out of the Anzo application, a dialog box informs them that additional applications are logged in with the current user, and they are prompted to log out of all sessions.
Disable AnzoGraph Detailed Query Timing by Default
When the Futures Based Query Manager (FBQM) was enabled for AnzoGraph (the default value for Anzo Version 5.x) the average query response time was longer than it was when FBQM was disabled. The difference was due to the additional queries Anzo was sending to AnzoGraph to retrieve detailed timing statistics for every query. The additional queries increased the AnzoGraph workload and slowed the overall response time.
Version 5.0.2 enables users to choose whether to include the detailed timing statistics as part of the FBQM. A new setting, Enable Detailed Query Timing (shown below), was added to the Advanced configuration settings for AnzoGraph.
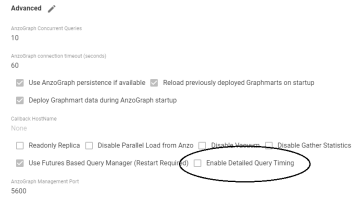
The setting is disabled by default, meaning that Anzo will not run the additional statistics gathering queries unless you enable the setting. When Enable Detailed Query Timing is disabled, the System Query Audit log displays fewer query timing details. For example, the images in the table below show a comparison between the Result Details tab when Enable Detailed Query Timing is disabled versus enabled. When the setting is disabled, details such as query Compilation Time are not recorded.
| Enable Detailed Query Timing Disabled | Enable Detailed Query Timing Enabled |
|---|---|
|
|
|


In addition, the images in the following table show a comparison between the Query Statistics tab when Enable Detailed Query Timing is disabled versus enabled. When the setting is disabled, the Compilation Stats and Query Summary tables are empty.
| Enable Detailed Query Timing Disabled | Enable Detailed Query Timing Enabled |
|---|---|
|
|
|
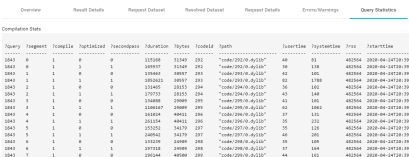
To enable detailed query timing, edit the AnzoGraph connection and select the Enable Detailed Query Timing checkbox. You do not need to restart Anzo or AnzoGraph after changing the setting. Note that enabling detailed query timing increases the AnzoGraph workload and may decrease overall performance.
Failed to Display Graphmart Overview Screen
On rare occasions, when a user clicked a graphmart from the Graphmarts screen, the Overview screen for that graphmart would not fully load due to the number of processes that were executed. Version 5.0.2 resolves the issue to ensure that the initial load of the Graphmart Overview screen is successful.
Incomplete Results from OData JDBC Driver with Server Side Paging
When a Data on Demand request was sent via the JDBC driver with server side paging enabled (the default configuration), Anzo could miscalculate when to return the "odata.next" annotation, which is used by clients to know to request the next page of data. As a result, the response could return fewer results than expected. For example, if 50k rows was requested, and the page size was 10k rows per page, the JDBC driver made the first request with "odata.maxpagesize" set to 10k. The first 10k rows were returned along with the "odata.next" annotation, indicating that there was more data to read. The second 10k rows were requested and returned along with the "odata.next" annotation set to request the next 10k rows. However, when the third 10k rows were returned, because the logic was incorrect, the "odata.next" annotation was not included, and the remaining records were not requested.
Version 5.0.2 resolves the issue to ensure that all of the results are retrieved when using the JDBC driver with server side paging.
Improved Error Messaging for Login Failures
Version 5.0.2 standardizes messaging for authentication failures across all SSO providers. It also ensures that consistent messages are returned for non-SSO login failures.
Anzo Version 5.0.1
This section describes the improvements and issues that were fixed in Anzo Version 5.0.1.
- New Option to Import a Batch of Split JSON files
- Improve Multi-User Query Performance
- Improve Performance for Unstructured Document Text Searches
- Improve Performance for Data Toolkit Service Queries
- Ensure Primary Keys in Data Dictionary are Applied to Model
- Create Separate Pipelines when Multiple Dictionaries use Same Schema
- Generate Valid Pipeline for Dictionary with Merged Class and Foreign Keys
- Ingest all Source Tables for Dictionaries with Merged Classes
- Support Hi-Res Analytics Dashboards with Side Navigation Layout
- Option to Configure Temporary File Location for Unstructured Pipelines
- Close All Open File Handles for Unstructured Pipeline
- Cancel Unstructured Pipeline Successfully when Documents Pending Write
- Display Document Names with Special Characters
- Parse OData Queries with Filters on Multi-Valued Properties
- Ensure Data on Demand uses Correct SKOS Ontology
New Option to Import a Batch of Split JSON files
When a large amount of data is ingested from a single JSON file, the resulting ETL pipeline can take an extremely long time to complete because a single job is created. Since it is a single job, a single ETL engine node processes the data while other resources remain idle. Version 5.0.1 introduces the ability to import a batch of JSON files so that users can divide the source data into several smaller files. Since the data is divided, multiple ETL jobs are created and they can be processed in parallel.
When importing a batch of files in Version 5.0.1, the new Add Part JSON File Locations field (shown below) is used to select multiple files.
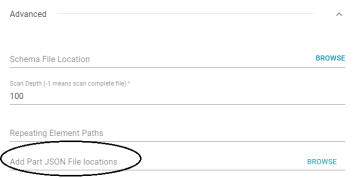
For more information, see Importing Data from JSON Files.
Improve Multi-User Query Performance
In Version 5.0, when the new Futures Based Query Manager was enabled to provide a view of the queued queries in Anzo, query performance could decrease when several users were running queries concurrently. Version 5.0.1 resolves the issue so that performance remains consistent when the Futures Based Query Manager is enabled and several queries are run concurrently.
Improve Performance for Unstructured Document Text Searches
Version 5.0.1 revises the queries that are automatically generated when performing text searches via the Document Search Lens. The changes to the lens take advantage of the general improvements that parallelize the execution of Elasticsearch service calls in AnzoGraph.
After upgrading to Anzo Version 5.0.1, any existing Document Search Lenses need to be deleted and re-created. For more information about Document Search Lenses, see Running Text Searches on Unstructured Data.
Improve Performance for Data Toolkit Service Queries
In previous versions, if the Data Toolkit Service was used to blend data from remote endpoints into graphmarts, the SERVICE call was first sent to the local Anzo SPARQL endpoint before being rewritten and sent to AnzoGraph for processing. To improve performance, Version 5.0 sends SERVICE calls directly to AnzoGraph to process. If you use the Data Toolkit Service with Anzo Version 5.0.1, you must also use AnzoGraph Version 2.1.0. In addition, there are post-installation steps required to configure AnzoGraph for use with the Data Toolkit Service.
Follow the instructions below to configure AnzoGraph for use with the service. If you use Anzo Unstructured and have configured AnzoGraph for use with Elasticsearch, you do not need to complete this task.
- Make sure that the azgmgrd and anzograph services are stopped before proceeding
- AnzoGraph requires Java Development Kit version 11. Follow these steps to install OpenJDK 11 and set $JAVA_HOME to the Java Runtime Environment.
Perform these steps on all servers in the cluster:
- Run the following command to install OpenJDK 11:
sudo yum install java-11-openjdk
- Modify the AnzoGraph system management service, azgmgrd.service, to set the $JAVA_HOME variable to the java runtime environment for the OpenJDK that you installed. To set the variable, add the following line to
/usr/lib/systemd/system/azgmgrd.service:ENVIRONMENT=JAVA_HOME=/usr/lib/jvm/jre-11
- Run the following command to install OpenJDK 11:
- Copy the data toolkit plugin, datatoolkit-1.0.0.jar, provided by Cambridge Semantics to the
<install_path>/lib/udxdirectory on the AnzoGraph leader server. The AnzoGraph leader broadcasts the jar to the compute nodes when the database is started. - Start the azgmgrd service on each AnzoGraph server:
sudo systemctl start azgmgrd
- On the leader node, start the anzograph service:
sudo systemctl start anzograph
Ensure Primary Keys in Data Dictionary are Applied to Model
In Version 5.0, the following workflow produced unexpected results:
- A data dictionary was created from a schema.
- The schema was later edited to add a primary key.
- The modified schema was added to the dictionary again.
- The source was ingested with the dictionary, but the URIs in the resulting data model did not reflect the new primary key.
Version 5.0.1 resolves the issue so that when a primary key is added to an existing schema in a dictionary, the data model generated from the dictionary correctly reflects the change.
Create Separate Pipelines when Multiple Dictionaries use Same Schema
In Version 5.0, a user created two data dictionaries from the same schema and then created a pipeline for each dictionary. When both pipelines were run, the second pipeline overwrote the first one. In Version 5.0.1, if multiple dictionaries are created from the same schema, Anzo ensures that the pipelines for those dictionaries are unique and remain separate.
Generate Valid Pipeline for Dictionary with Merged Class and Foreign Keys
In Version 5.0, an invalid job could be generated for a pipeline that was created from a data dictionary if the dictionary had the following characteristics:
- The dictionary was for a CSV data source.
- Multiple source tables were merged into a single class concept.
- That merged concept represented the source class of a foreign key relationship.
Version 5.0.1 resolves the issue so that all jobs are valid in a pipeline that results from the circumstance described above.
Ingest all Source Tables for Dictionaries with Merged Classes
In Version 5.0, if a data dictionary for a CSV schema merged two classes, the resulting pipeline included one job for the merged class, but it only ingested the data for one of the tables. Version 5.0.1 resolves the issue so that pipelines from dictionaries with merged classes ingest the data from both of the source tables.
Support Hi-Res Analytics Dashboards with Side Navigation Layout
Version 5.0 eliminated the side navigation layout option from the dashboard designer in Hi-Res Analytics. As a result, if a user had dashboards that employed the side navigation layout in Version 4.x, those dashboards became non-functional when Anzo was upgraded to Version 5.0. Version 5.0.1 restores the side navigation layout so that those dashboards remain functional after an upgrade from Version 4.x.
Option to Configure Temporary File Location for Unstructured Pipelines
In previous versions, Anzo Unstructured worker nodes wrote temporary files to the /tmp directory by default, and the location could not be customized. Since /tmp is often on a standard disk, there could be a I/O bottleneck when workers wrote temporary files. Version 5.0.1 adds a new Ramdisk Directory Location setting under Advanced options in the unstructured pipeline configuration. Users can specify a more efficient disk location, such as a mounted SSD, and the temporary files for the pipeline are written to the specified location.
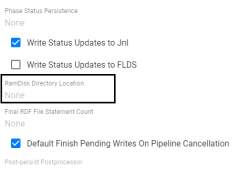
Close All Open File Handles for Unstructured Pipeline
In some cases, open file handles on temporary copies of the original binary files could get orphaned when processing an unstructured pipeline. Version 5.0.1 resolves the issue to ensure that all open file handles are closed.
Cancel Unstructured Pipeline Successfully when Documents Pending Write
In some cases, if a user tried to end an unstructured pipeline, the cancellation failed and returned a "Cannot retrieve document to update status" error. The error occurred when there were documents with a status of Pending Write. Version 5.0.1 resolves the issue so that unstructured pipelines can be canceled when documents are pending write.
Display Document Names with Special Characters
In previous versions, if an unstructured pipeline crawled documents that had special characters, such as ?, in the file name, the Progress screen displayed the name of the directory the file was in instead of the file name. Version 5.0.1 resolves the issue so that document names with special characters are displayed on the unstructured pipeline Progress screen.
Parse OData Queries with Filters on Multi-Valued Properties
In previous versions, if the WHERE clause in an OData query included a filter on a multi-valued property (such as in the example below), Anzo was unable to parse the query due to the way it was translated by the JDBC driver.
SELECT a b FROM Gene_Value WHERE a = 'ALK'
Version 5.0.1 resolves the issue and enables Anzo to parse OData queries with filters on multi-valued properties.
Ensure Data on Demand uses Correct SKOS Ontology
In previous versions, if an application accessed a Data on Demand endpoint for a graphmart that included a version of the SKOS ontology, the results failed to display all of the available classes. The Data on Demand schema was using the default Anzo SKOS ontology instead of the version of SKOS that was included in the graphmart. Version 5.0.1 resolves the issue to ensure that the Data on Demand schema uses the ontologies that are associated with the graphmart and data layers as well as any referenced ontologies.
Anzo Version 5.0.0
This section describes the new features and changes to existing components that are introduced in Anzo Version 5.0.0.
New Features
- Data Dictionaries for Metadata Management
- Dynamic Deployments of AnzoGraph, Elasticsearch, and Spark
- Graph Data Metrics
- Global Search by Title
- Sparkler ETL Compiler
- Comparison of a Backup Version to its Previous Version
- Ability to View and Cancel Queued Queries
- Query-Driven Template and Pre-Compile Query Data Layer Steps
Improvements to Existing Features
- SAS Metadata Imported and Displayed in Data Dictionary
- Option for Load Data Step to Indicate when Linked Dataset Changes
- Option to Generate Graph Data Metrics During Export
- Option to Automatically Deploy Model Changes in a Data Layer
- Show Last Authentication Date for SSO Providers
- Refresh System Information On-Demand Instead of Continuously
- Option to Limit the Age/Size of Audit Logs
- Gather Statistics by Default after Loading to AnzoGraph
- Option to Configure Anzo to Scan Entire CSV File on Import
User Interface Improvements
- More Information at Initial Server Startup
- Home Page Redesign
- Redesign of User Menu and Profile Screen
- Files and Tables Screens Merged for Consistency Across Data Sources
- Redesigned Data Source Profiling Metrics
- Quick Access to Data on Demand Endpoints
- Filter for LDAP Users Versus Local Anzo Users
- Model View Distinguishes Between Subclass Relation and Object Property Relation
- Property Range Lists Preferred Data Types with Option to Show All Types
- Show Most Relevant Error Logs First
- Option to Create New Folder for Anzo Data Store
- File Selection Screen Has Option to Show All File Types
Anzo Unstructured Improvements
- Enhanced Unstructured Pipeline Post-Processesing Performance
- Knowledgebase Annotator for Graphmarts and Data Layers
- Option to Move the Binary Store when Exporting Data
- Option to Capture Binary Store Access Events in Audit Logs
Other Changes and Fixes
- File Store Moved to Administration Menu
- Installs Page Includes Anzo ODBC and JDBC Driver Downloads
- Option for Importing CSV Files with Multi-Line Columns
- Renamed Auto-Ingest to Ingest
- Use Local Name when Uploaded Model Excludes rdfs:label
- Added SSL Options to Email Server Configuration
- Removed Outdated Admin User Interface and Linked Data Collections
- Removed Description Column from Foreign Key List
- Removed RelationReplicator Bundle
- Support Provenance View on Latest Version of Chrome
- JDBC Driver Requests $metadata Once Per Query
- Apply OData $top, $skip and SQL LIMIT, OFFSET when Paging Enabled
- Accurate Error Message when Unsupported RDF File Formats are Imported
- Enable All Users to Copy URIs from Layer or Step Menus
- Exception Displayed if FLDS Creation Fails
- Spark Support for Newline Characters in JDBC URLs
- Ensure Local Spark Engine Generates Unique Files Names when Processing Large Files
- Fail on CSV Data Type Mismatch Instead of Parsing to Null
- Project Results for VALUES Clause with Single Binding
- Apply Style Changes to Heat Map Lens
Data Dictionaries for Metadata Management
Anzo Version 5.0 introduces the new Data Dictionary component, a feature that gives users complete flexibility in managing data source metadata. Data dictionaries define the common concepts that exist in and across data sources, independent of the models and mappings for each source. The data dictionary structure becomes the basis for creating and reusing models and mappings when onboarding data. For more information, see Using Data Dictionaries.
Dynamic Deployments of AnzoGraph, Elasticsearch, and Spark
Anzo Version 5.0 integrates with Amazon Web Services, Google Cloud, and Microsoft Azure services to offer dynamic, Kubernetes-based deployments of AnzoGraph, Spark, and Elasticsearch. The Kubernetes integration automates the scaling and management of the computing resources that support Anzo's data onboarding, modeling, blending, and access capabilities.
When dynamic deployments are enabled:
- Anzo users activate pre-configured Kubernetes environments on-demand without needing specific technical, cloud platform, or infrastructure provisioning skills.
- Right-sized clusters are automatically created and deleted in response to users' real-time requests, avoiding the need to keep instances running indefinitely and reducing the overall cost of maintaining the applications.
- Anzo provides a unified user interface for administrators to create and view all of the dynamic deployment options. Multiple cloud service providers can be managed through the same user interface.
For more information, see Using K8s for Dynamic Deployments of Anzo Components.
Graph Data Metrics
Version 5.0 introduces the ability to calculate metrics for a graph data set in its final format. When metrics are generated for graph data, Anzo profiles the entire data set and reports metrics for the classes and properties in the model as well as statistics about the values for the properties. Generating graph data metrics helps users perform data discovery, assess the quality of the onboarded data, and decide whether to include a data set in a particular graphmart. For more information, see Generating Graph Data Metrics.
Global Search by Title
Version 5.0 introduces a new global search feature that enables users to find resources, such as data sources, data sets, graphmarts, or schemas, by title. The Search field accepts wildcard characters and finds entities across all components. For more information, see Introduction to the User Interface in the Anzo Deployment and User Guide.
Sparkler ETL Compiler
Version 5.0 introduces Cambridge Semantics' Sparkler ETL compiler. Like the Spark Engine, the Sparkler compiler is embedded locally in Anzo and can also be deployed on a standalone Spark server or cluster. Sparkler is a SPARQL-driven ETL compiler that increases performance over the Spark Scala-based compiler in many cases. The Sparkler compiler has all of the same functionality as the Scala-based Spark compiler, and, unlike the Scala-based Spark compiler, supports the ingestion of wide CSV files with a very large number of columns. When configuring pipelines, users now specify whether to use the Scala-based Spark or Sparkler compiler for that pipeline.
The local Scala-based Spark compiler will eventually be deprecated and replaced by the Sparkler compiler.
Comparison of a Backup Version to its Previous Version
In Version 5.0, Anzo provides the ability to compare a backup version of an artifact against the previous version of that artifact. To view a comparison, from the Versions tab for an artifact, select the version for which you want to compare changes from the previous version. In the list of related entities, as shown below, the Actions column displays a compare icon next to each entity that has changed since the previous version. For example:
![]()
Clicking the compare icon opens the Compare Versions dialog box, which shows the TriG files for the two versions side-by-side. For example:
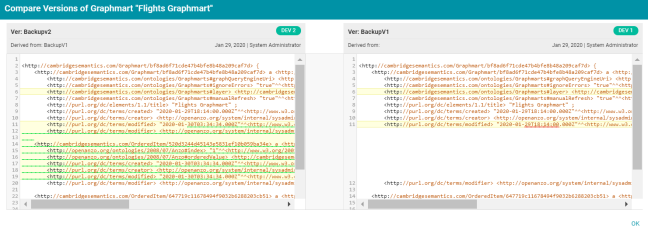
Ability to View and Cancel Queued Queries
In Version 5.0, the System Query Audit log includes a Queued Queries tab that displays a list of the queries that are queued behind currently running queries. Administrators can cancel queries from the list and remove them from the queue.
For AnzoGraph, whether or not to include queued queries in the report is controlled by the new Use Futures Based Query Manager option in AnzoGraph Advanced settings (as shown below). The option is enabled by default.
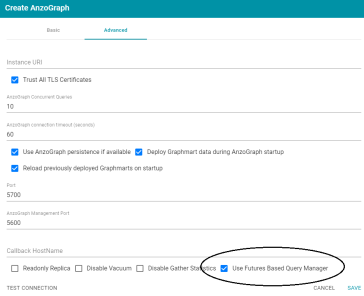
A restart of Anzo is required if Futures Based Query Manager is enabled or disabled after the initial connection to AnzoGraph is saved. For more information, see Connecting to AnzoGraph.
Query-Driven Template and Pre-Compile Query Data Layer Steps
Version 5.0 introduces two new types of data layer steps:
- Query Driven Templated Step: This type of step enables user to create reusable query-driven templates for quickly creating additional query steps.
- Pre-compile Query Step: This type of step runs the included query immediately after a graphmart is loaded so that the query is pre-compiled by AnzoGraph. Pre-compiling a query reduces execution time when an end-user runs that query for the first time.
SAS Metadata Imported and Displayed in Data Dictionary
In previous versions, Anzo did not import any of the metadata that may have been included in SAS7BDAT files. In Version 5.0, Anzo does import the metadata. It only becomes visible, however, when a metadata dictionary is created for the source. For more information, see Importing Data from SAS Files and Using Data Dictionaries.
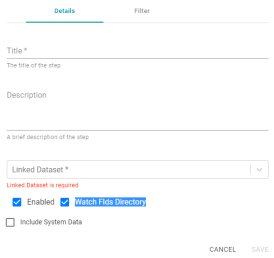
Option for Load Data Step to Indicate when Linked Dataset Changes
Version 5.0 introduces a new option for configuring Load Data Steps to give an indication if the selected linked data set changes on the file store. When the new the Watch FLDS Directory setting is enabled Anzo will indicate that this step (and data layer) need to be refreshed if any of the files in the FLDS directory are changed.
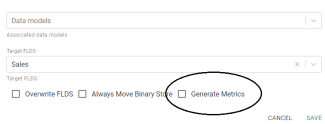
Option to Generate Graph Data Metrics During Export
Version 5.0 introduces the option to generate graph data metrics as part of an Export Step. The metrics are exported as part of the FLDS. If the files are loaded in the future, the graph data metrics will be available in the dataset catalog. The new Generate Metrics option in the Export Step configuration (shown below) controls whether to compute metrics during export.
Option to Automatically Deploy Model Changes in a Data Layer
Version 5.0 introduces a new data layer setting that gives users control over how and when data model changes are deployed to AnzoGraph. When the new Auto Deploy Ontology Changes setting (shown in the image below) is enabled, any changes to the layer's dependent models are deployed to AnzoGraph without having to manually refresh the layer or graphmart. For more information about the setting, see Adding Data Layers to Graphmarts.
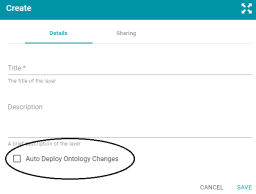
The Manual Refresh Graphmart setting on the graphmart must be disabled for automatic deployment of models to work. For more information about the manual refresh setting, see Creating a Graphmart in the Anzo Deployment and User Guide.
Show Last Authentication Date for SSO Providers
In Version 5.0, SSO provider configurations now display the date when the last successful authenticated login occurred. This change helps administrators determine whether a provider is being used or whether it is a candidate for deletion.
Refresh System Information On-Demand Instead of Continuously
In previous versions, it could be difficult to review process and thread details in the System Information screen because new processes and threads were constantly added to the lists. In Version 5.0, the Processes and Threads lists in System Information are refreshed only when a user clicks the new Snapshot button.
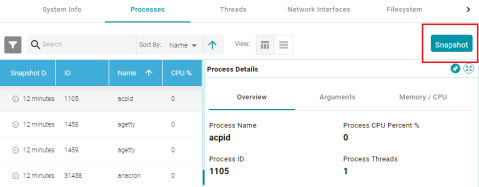
Option to Limit the Age/Size of Audit Logs
Version 5.0 introduces the option to add an age limit (in days) to audit log data sets. Once an audit log data set reaches that age, Anzo stops writing to it and a new audit log data set is started. This option enables users to retain all of the audit log data but work with smaller data sets when loading and analyzing the data. Follow the instructions below to configure the audit log service to add an age limit:
- In the Anzo console, expand the Administration menu and click Advanced Configuration. Click I understand and accept the risk.
- Search for the Anzo Audit Logging Framework bundle and view its details.
- Click the Services tab and expand com.cambridgesemantics.anzo.AuditLog.
- Find the limitAge and maxAge properties (shown below).

- Select the com.cambridgesemantics.anzo.auditlog.limitAge checkbox to enable the age limit feature.
- Edit the com.cambridgesemantics.anzo.auditlog.maxAge property to specify the maximum number of days to log in each data set. When the current audit log reaches that age, Anzo starts writing to a new data set.
- Restart Anzo to apply the configuration changes.
Gather Statistics by Default after Loading to AnzoGraph
In Version 5.0, the Disable Gather Statistics option (shown in the image below) is disabled by default, meaning that AnzoGraph automatically initiates its internal statistics gathering queries immediately after a graphmart is loaded. If statistics gathering is disabled, AnzoGraph runs the internal queries when the first analytic queries are run, increasing the execution time for the first queries. Since loads take longer than queries, adding more time to the load is less noticeable than waiting for statistics to be generated during initial query execution.
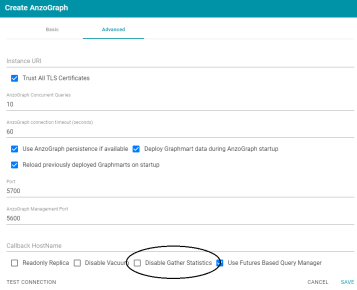
For more information, see Connecting to AnzoGraph in the Anzo Deployment and User Guide.
Option to Configure Anzo to Scan Entire CSV File on Import
To help improve accuracy of data type assignment when importing CSV files, Version 5.0 provides an option to configure the system so that any time a CSV file is imported, Anzo scans the entire file before inferring the data types for each column. Follow the instructions below if you want to configure the system to scan entire CSV files.
This change affects all CSV file imports. Users cannot opt-out of a complete scan at import time. This configuration is not related to the Use Extended Sample setting in file import options. Choosing to scan entire files will significantly increase the time it takes to import files. However, scanning the complete file is the best way to ensure that data type assignments are accurate.
- In the Anzo console, expand the Administration menu and click Advanced Configuration. Click I understand and accept the risk.
- Search for the Anzo Utilityservices VFS bundle and view its details.
- Click the Services tab and expand UtilityServices VFS Activator.
- Find the com.cambridgesemantics.anzo.utilityservices.vfs.isSampleEntireFile property, and select the checkbox to enable the option.
When SampleEntireFile is enabled, the values in the maxSampleSize and sampleSize properties are ignored and Anzo always scans entire CSV files on import
- Restart Anzo to apply the configuration changes.
More Information at Initial Server Startup
In Version 5.0, after the initial installation and startup, Anzo displays information about the number of services that are still starting. For example:
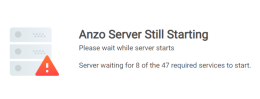
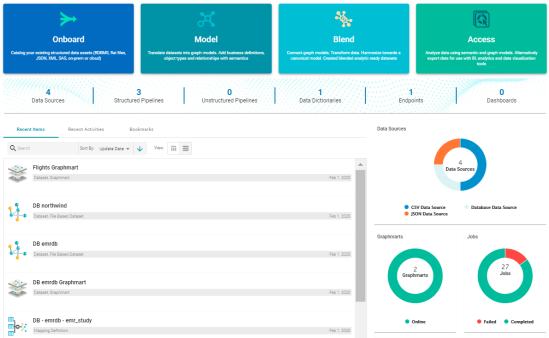
Home Page Redesign
Version 5.0 redesigns the user interface Home page. The screen now provides links to the commonly used features that the logged in user has access to. And a dashboard displays an overview of the system artifacts and recently updated or bookmarked items. For example:
Redesign of User Menu and Profile Screen
Version 5.0 redesigns the user menu that is accessed from the user (![]() ) icon on the right side of the top menu bar. The menu provides access to your user profile, the About screen, and the Application Progress window, which lists recent application activity. It also includes the ability to log out of the console and a Documentation link that opens the Anzo Deployment and User Guide.
) icon on the right side of the top menu bar. The menu provides access to your user profile, the About screen, and the Application Progress window, which lists recent application activity. It also includes the ability to log out of the console and a Documentation link that opens the Anzo Deployment and User Guide.
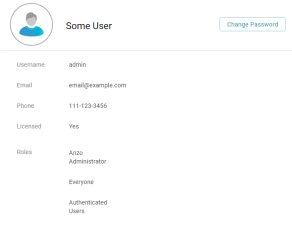
The user profile screen has also been redesigned and includes a Change Password option.
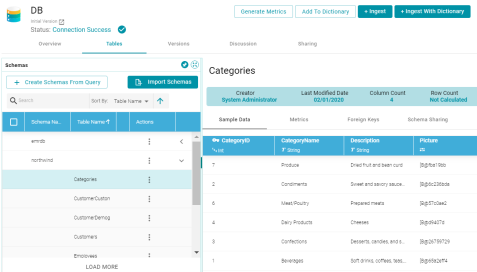
Files and Tables Screens Merged for Consistency Across Data Sources
Version 5.0 combines the Schema Files and Tables screens so that the access for importing data from different data sources is similar and the same information is easily accessible for each data source type. For example, the image below shows the Tables screen for a database data source. The left side of the screen shows the available schemas and includes buttons for creating or importing new schemas. The right side of the screen shows sample data, foreign keys, data source metrics, and schema sharing for configuring user and role permissions.
The following image shows the Tables screen for a CSV data source. The left side of the screen shows the imported files and includes buttons for adding and importing additional files. The right side of the screen shows sample data, foreign keys, data source metrics, and schema sharing for configuring user and role permissions.
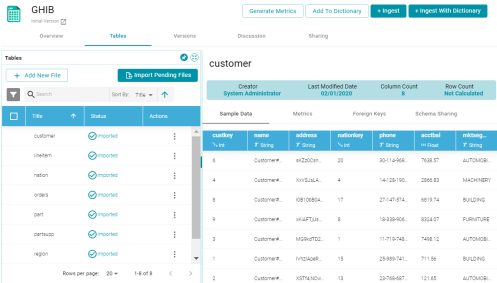
Redesigned Data Source Profiling Metrics
Version 5.0 redesigns the reports that are created when data profiling metrics are generated for a data source. In addition, more column-level metrics are calculated, such as the smallest and largest values in a column, the number of unique values, and the value that appears most often. For more information, see Generating Source Data Metrics.
Quick Access to Data on Demand Endpoints
Version 5.0 adds a Data On Demand option in the Access menu. The new access point enables users to quickly find a list of the configured Data on Demand endpoints. For example:
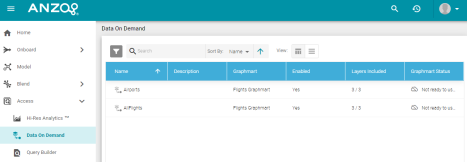
Filter for LDAP Users Versus Local Anzo Users
In Version 5.0, Anzo includes a new Anzo Internal Users option on the Filter panel on the System Roles/User screen. Selecting the option filters the resource list to show only the local Anzo users. For example:
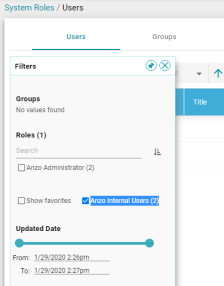
Model View Distinguishes Between Subclass Relation and Object Property Relation
In Version 5.0, the graph view of a data model distinguishes between subclass relationships and object property relationships by using different styles for the lines. Subclass relationships are now shown as a dotted pink line, and object property relationships remain a solid blue line. For example:
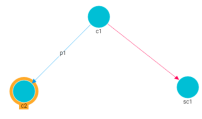
Property Range Lists Preferred Data Types with Option to Show All Types
To help users choose preferred data types when creating or editing properties in a model or data dictionary, Anzo Version 5.0 first presents the list of common property range values, the values that are treated consistently and predictably across systems. The Property Range drop-down list has a new toggle icon, as shown in the image below. By default the field is set to Show Common (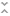 ) types. Clicking the icon changes the field to Show All (
) types. Clicking the icon changes the field to Show All ( ), which displays all types.
), which displays all types.

Show Most Relevant Error Logs First
Version 5.0 changes the order of the logs that are shown on the Logging/Log Actions screen. The most relevant and commonly referenced error logs now appear at the top of the list:
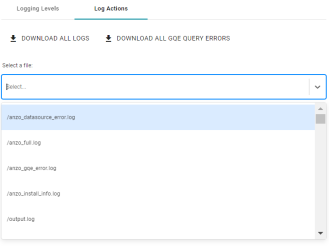
Option to Create New Folder for Anzo Data Store
When you create an Anzo Data Store in Version 5.0, the File Location screen includes the option to create a new folder on the file store.
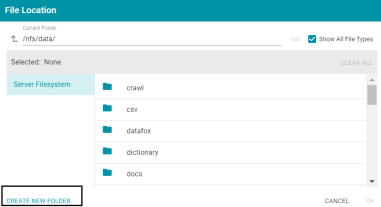
File Selection Screen Has Option to Show All File Types
In Version 5.0, the Add New File screens include a Show All File Types option so that users can view all file types when selecting source files to import. For example:
Enhanced Unstructured Pipeline Post-Processesing Performance
In Version 5.0, the Anzo Unstructured (AU) post-processing code was refactored to eliminate unnecessary operations and parallelize other operations. The following changes increase the performance of unstructured pipeline processing:
- In previous AU versions, when the worker nodes processed documents, they wrote RDF and binary store data to a staging location. At the end of the pipeline process, the RDF and binary store in the staging location was rewritten, moved, or copied to the final location. In Version 5.0, RDF and binary store data are written to disk once in the final output location.
- In previous AU versions, time-consuming post-processing operations, such as Elasticsearch indexing, were not started until all documents in the pipeline were processed. In Version 5.0, parallelization of the post-processing phase enables time-consuming operations to run concurrently with other operations rather than waiting for full pipeline completion.
Knowledgebase Annotator for Graphmarts and Data Layers
In Version 5.0, Knowledgebase Annotators can be configured to run against graphmarts and data layers that are loaded to AnzoGraph as well as linked data sets in the Anzo dataset catalog. For more information about the Knowledgebase Annotator, see Knowledgebase Annotator.
Option to Move the Binary Store when Exporting Data
Version 5.0 includes a new Always Move Binary Store option for Export Steps. This option controls whether the binary store is moved or copied during the export. Since the binary store can be large and have a nested structure, copying the data can take a very long time. Since moving the binary store is almost instantaneous, however, enabling Always Move Binary Store can reduce the time it takes to complete the export.
Option to Capture Binary Store Access Events in Audit Logs
Version 5.0 introduces the option to capture audit log information about binary store requests. Information such as time of the request, the user who made the request, and the document accessed will be logged. Follow the instructions below to configure this option:
- In the Anzo console, expand the Administration menu and click Advanced Configuration.
- Search for the Anzo Audit Logging Framework bundle and view its details.
- Click the Services tab and expand com.cambridgesemantics.anzo.AuditLog.
- Select the com.cambridgesemantics.anzo.auditlog.rdfLog property to enable the option.
- Make sure that the com.cambridgesemantics.anzo.auditlog.splitByType property is selected/enabled (it is enabled by default).
- Restart Anzo to apply the configuration change.
New binary store access audit events will be added to the logs in the subdirectories under <install_path>/Server/logs/audit/audit-flds.
File Store Moved to Administration Menu
In Version 5.0, the File Store menu item is moved from the Onboard menu to the Administration menu.
Installs Page Includes Anzo ODBC and JDBC Driver Downloads
In Version 5.0, the Anzo Software Installation Packages page, accessed via https://<Anzo_server_IP>/installs/, includes a link for accessing the Anzo ODBC and JDBC driver downloads.
Option for Importing CSV Files with Multi-Line Columns
In Version 5.0, the Edit CSV File screen that enables configuration of CSV files for import has a new Multiline File option. Enabling this option allows you to import CSV files that have quoted multi-line columns.
CSV files that have spaces in their file path or file name cannot be imported into Anzo.
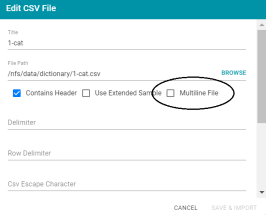
Renamed Auto-Ingest to Ingest
In Version 5.0, the Auto Ingest button was renamed Ingest, and an Ingest With Dictionary button was added for ingesting data with an associated data dictionary.
Use Local Name when Uploaded Model Excludes rdfs:label
In previous versions, if a user uploaded a model to Anzo that was missing the rdfs:label property, which defines name of the model, the model would be named "(Untitled)." In Version 5.0, if an uploaded model is missing the rdfs:label property, Anzo uses the local name from the model URI in the file. For example, if the URI is "<http://cambridgesemantics.com/ontologies/MyModel>," the name of the model becomes "MyModel."
Added SSL Options to Email Server Configuration
In previous versions, Anzo supported only non-SSL, anonymous access to external SMTP servers. Version 5.0 adds the option to use SSL when configuring Anzo to connect to an email server. For more information, see Configure the SMTP Server Used to Send Email in the Anzo Deployment and User Guide.
Removed Outdated Admin User Interface and Linked Data Collections
Version 5.0 removes the Admin user interface that was available by default at https://<IP>:8946/admin/. All functionality from that interface exists under the Administration menu in the current user interface. Removal of the Admin user interface also removes the ability to create and manage Linked Data Collections, which were replaced by Graphmarts in Anzo Version 4.0.
Removed Description Column from Foreign Key List
Version 5.0 removes the Description column from the Active Keys selection list. The Description was not editable and repeated the key name.
Removed RelationReplicator Bundle
Version 5.0 removes the RelationReplicator Bundle from the system. This bundle is not used by any Anzo components.
Support Provenance View on Latest Version of Chrome
In previous versions, the Provenance view would not load and displayed a react component error on the latest version of Google Chrome, version 80. Version 5.0 resolves the issues so that provenance is displayed with Chrome version 80.
JDBC Driver Requests $metadata Once Per Query
In previous versions, the Anzo CData JDBC driver was fetching metadata multiple times per request, causing performance to slow down for Data on Demand queries that included $metadata. In Version 5.0, the JDBC driver was updated to ensure requests retrieve metadata once per request and reuse the results throughout the query.
To take advantage of this fix, upgrade any existing JDBC drivers with the latest version after installing Anzo 5.0. For instructions, see Accessing Data via the ODBC or JDBC API in the Anzo Deployment and User Guide.
Apply OData $top, $skip and SQL LIMIT, OFFSET when Paging Enabled
In previous versions, if client or server side paging was enabled and users queried Data on Demand endpoints via OData or JDBC, the $top and $skip OData parameters and LIMIT and OFFEST query options were ignored and all of the data was returned. Version 5.0 ensures that the OData and query options described above are considered when client or server side paging is enabled and the appropriate results are returned.
Accurate Error Message when Unsupported RDF File Formats are Imported
In previous versions, if an unsupported RDF file format was imported to the dataset catalog, the error message that was returned did not adequately describe the issue. In Version 5.0, Anzo returns a meaningful error message if the imported file format is not supported by AnzoGraph.
Enable All Users to Copy URIs from Layer or Step Menus
In previous Anzo versions, if a user other than the sysadmin user selected Copy URI from a data layer or step menu in a graphmart (shown in the image below), the URI would not get copied to the clipboard. Version 5.0 corrects the issue so that all users can copy URIs from the layer and step menus.
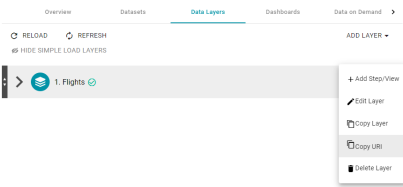
Fail on CSV Data Type Mismatch Instead of Parsing to Null
In previous versions, if a CSV file had values with data types that did not match the specified type for the column, Anzo parsed the mismatched values to null during the ETL process. That caused confusion because the data set had fewer than expected records. In Version 5.0, if mismatched data types are encountered, Anzo fails the job so that users can correct the issue.
Exception Displayed if FLDS Creation Fails
In some cases, Spark reported that an ETL job was completed, but the final FLDS creation did not succeed. Version 5.0 ensures that an exception is displayed if a job completes but final FLDS processing fails.
Spark Support for Newline Characters in JDBC URLs
When onboarding data from an OData database using the CData JDBC driver, using a newline character (\n) between custom headers in the connection string generated Scala that failed to compile. Version 5.0 resolves the issue so that ETL jobs succeed for JDBC URLs with \n characters.
Ensure Local Spark Engine Generates Unique Files Names when Processing Large Files
In certain circumstances when the embedded Spark ETL engine processed an extremely large CSV file, some records were missing from the resulting FLDS. The issue occurred because non-unique file names were generated in the output in some cases, and records were overwritten. Version 5.0 resolves the issue by ensuring that all file names, both permanent and temporary, are unique.
Project Results for VALUES Clause with Single Binding
In previous versions, if a query that was run against a local volume included a VALUES clause with a single binding, Anzo failed to project the results. For example, the following query did not produce results even though the data included "abc."
SELECT ?value
WHERE {
VALUES(?value){("abc")}
}
Version 5.0 resolves the issues so that results are projected if a query like the example above is run against a local volume data source.
Apply Style Changes to Heat Map Lens
Version 5.0 fixes an issue in the Hi-Res Analytics application where changes to the colors displayed in a heat map were not applied to the lens.